 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSculpting [CLS] Features for Pre-Trained Model-Based Class-Incremental Learning
Feb 20, 2025Class-incremental learning requires models to continually acquire knowledge of new classes without forgetting old ones. Although pre-trained models have demonstrated strong performance in class-incremental learning, they remain susceptible to catastrophic forgetting when learning new concepts. Excessive plasticity in the models breaks generalizability and causes forgetting, while strong stability results in insufficient adaptation to new classes. This necessitates effective adaptation with minimal modifications to preserve the general knowledge of pre-trained models. To address this challenge, we first introduce a new parameter-efficient fine-tuning module 'Learn and Calibrate', or LuCA, designed to acquire knowledge through an adapter-calibrator couple, enabling effective adaptation with well-refined feature representations. Second, for each learning session, we deploy a sparse LuCA module on top of the last token just before the classifier, which we refer to as 'Token-level Sparse Calibration and Adaptation', or TOSCA. This strategic design improves the orthogonality between the modules and significantly reduces both training and inference complexity. By leaving the generalization capabilities of the pre-trained models intact and adapting exclusively via the last token, our approach achieves a harmonious balance between stability and plasticity. Extensive experiments demonstrate TOSCA's state-of-the-art performance while introducing ~8 times fewer parameters compared to prior methods.
Continual Learning on a Data Diet
Oct 23, 2024



Continual Learning (CL) methods usually learn from all available data. However, this is not the case in human cognition which efficiently focuses on key experiences while disregarding the redundant information. Similarly, not all data points in a dataset have equal potential; some can be more informative than others. This disparity may significantly impact the performance, as both the quality and quantity of samples directly influence the model's generalizability and efficiency. Drawing inspiration from this, we explore the potential of learning from important samples and present an empirical study for evaluating coreset selection techniques in the context of CL to stimulate research in this unexplored area. We train different continual learners on increasing amounts of selected samples and investigate the learning-forgetting dynamics by shedding light on the underlying mechanisms driving their improved stability-plasticity balance. We present several significant observations: learning from selectively chosen samples (i) enhances incremental accuracy, (ii) improves knowledge retention of previous tasks, and (iii) refines learned representations. This analysis contributes to a deeper understanding of selective learning strategies in CL scenarios.
Continual Learning with Dynamic Sparse Training: Exploring Algorithms for Effective Model Updates
Aug 28, 2023


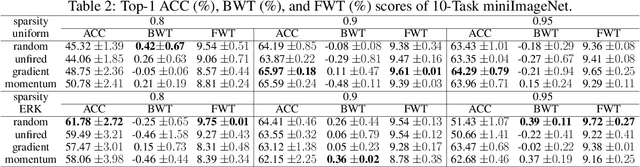
Continual learning (CL) refers to the ability of an intelligent system to sequentially acquire and retain knowledge from a stream of data with as little computational overhead as possible. To this end; regularization, replay, architecture, and parameter isolation approaches were introduced to the literature. Parameter isolation using a sparse network which enables to allocate distinct parts of the neural network to different tasks and also allows to share of parameters between tasks if they are similar. Dynamic Sparse Training (DST) is a prominent way to find these sparse networks and isolate them for each task. This paper is the first empirical study investigating the effect of different DST components under the CL paradigm to fill a critical research gap and shed light on the optimal configuration of DST for CL if it exists. Therefore, we perform a comprehensive study in which we investigate various DST components to find the best topology per task on well-known CIFAR100 and miniImageNet benchmarks in a task-incremental CL setup since our primary focus is to evaluate the performance of various DST criteria, rather than the process of mask selection. We found that, at a low sparsity level, Erdos-Renyi Kernel (ERK) initialization utilizes the backbone more efficiently and allows to effectively learn increments of tasks. At a high sparsity level, however, uniform initialization demonstrates more reliable and robust performance. In terms of growth strategy; performance is dependent on the defined initialization strategy, and the extent of sparsity. Finally, adaptivity within DST components is a promising way for better continual learners.
Adaptive Regularization for Class-Incremental Learning
Mar 24, 2023Class-Incremental Learning updates a deep classifier with new categories while maintaining the previously observed class accuracy. Regularizing the neural network weights is a common method to prevent forgetting previously learned classes while learning novel ones. However, existing regularizers use a constant magnitude throughout the learning sessions, which may not reflect the varying levels of difficulty of the tasks encountered during incremental learning. This study investigates the necessity of adaptive regularization in Class-Incremental Learning, which dynamically adjusts the regularization strength according to the complexity of the task at hand. We propose a Bayesian Optimization-based approach to automatically determine the optimal regularization magnitude for each learning task. Our experiments on two datasets via two regularizers demonstrate the importance of adaptive regularization for achieving accurate and less forgetful visual incremental learning.