 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyTAS: A Hyperspectral Image Transformer Architecture Search Benchmark and Analysis
Jul 23, 2024

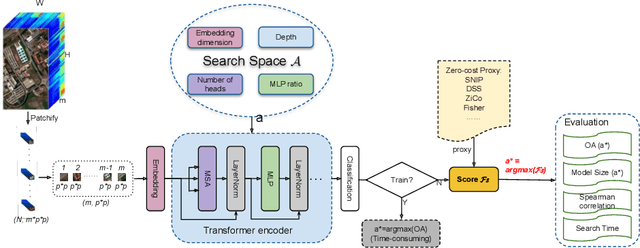

Hyperspectral Imaging (HSI) plays an increasingly critical role in precise vision tasks within remote sensing, capturing a wide spectrum of visual data. Transformer architectures have significantly enhanced HSI task performance, while advancements in Transformer Architecture Search (TAS) have improved model discovery. To harness these advancements for HSI classification, we make the following contributions: i) We propose HyTAS, the first benchmark on transformer architecture search for Hyperspectral imaging, ii) We comprehensively evaluate 12 different methods to identify the optimal transformer over 5 different datasets, iii) We perform an extensive factor analysis on the Hyperspectral transformer search performance, greatly motivating future research in this direction. All benchmark materials are available at HyTAS.
What Can AutoML Do For Continual Learning?
Nov 20, 2023This position paper outlines the potential of AutoML for incremental (continual) learning to encourage more research in this direction. Incremental learning involves incorporating new data from a stream of tasks and distributions to learn enhanced deep representations and adapt better to new tasks. However, a significant limitation of incremental learners is that most current techniques freeze the backbone architecture, hyperparameters, and the order & structure of the learning tasks throughout the learning and adaptation process. We strongly believe that AutoML offers promising solutions to address these limitations, enabling incremental learning to adapt to more diverse real-world tasks. Therefore, instead of directly proposing a new method, this paper takes a step back by posing the question: "What can AutoML do for incremental learning?" We outline three key areas of research that can contribute to making incremental learners more dynamic, highlighting concrete opportunities to apply AutoML methods in novel ways as well as entirely new challenges for AutoML research.
Locality-Aware Hyperspectral Classification
Sep 04, 2023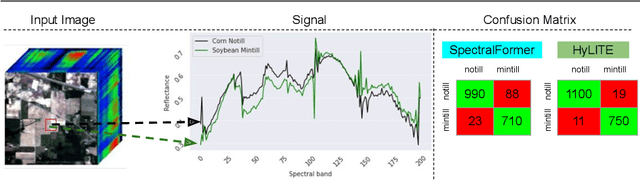
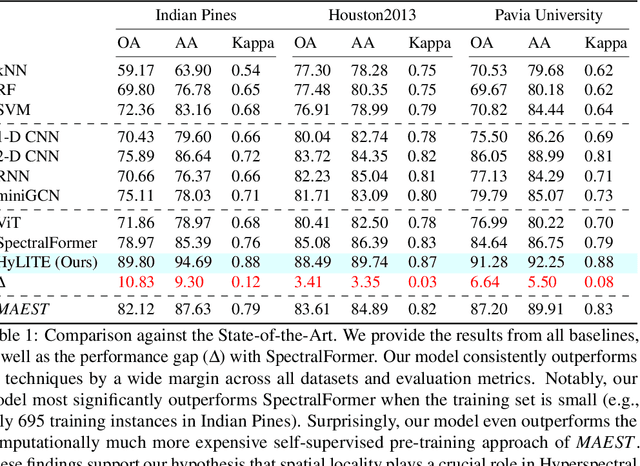
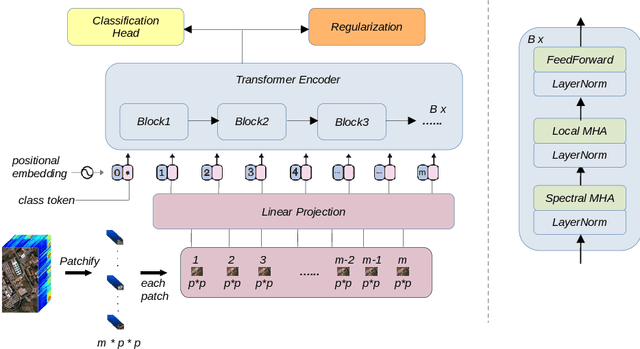
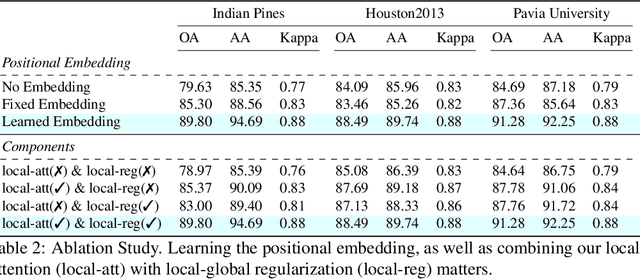
Hyperspectral image classification is gaining popularity for high-precision vision tasks in remote sensing, thanks to their ability to capture visual information available in a wide continuum of spectra. Researchers have been working on automating Hyperspectral image classification, with recent efforts leveraging Vision-Transformers. However, most research models only spectra information and lacks attention to the locality (i.e., neighboring pixels), which may be not sufficiently discriminative, resulting in performance limitations. To address this, we present three contributions: i) We introduce the Hyperspectral Locality-aware Image TransformEr (HyLITE), a vision transformer that models both local and spectral information, ii) A novel regularization function that promotes the integration of local-to-global information, and iii) Our proposed approach outperforms competing baselines by a significant margin, achieving up to 10% gains in accuracy. The trained models and the code are available at HyLITE.
Adaptive Regularization for Class-Incremental Learning
Mar 24, 2023


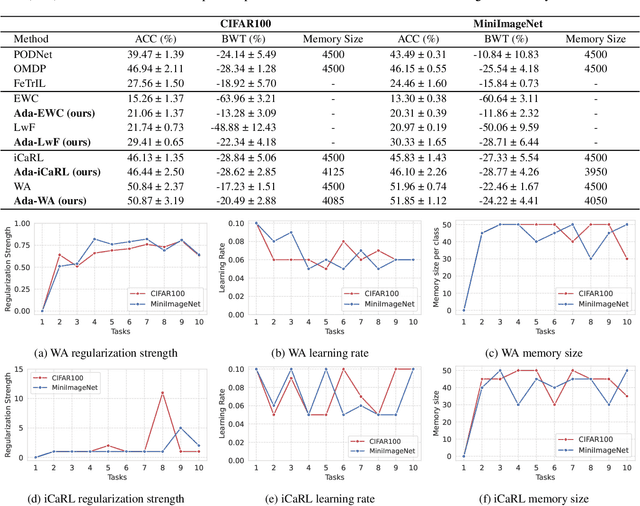
Class-Incremental Learning updates a deep classifier with new categories while maintaining the previously observed class accuracy. Regularizing the neural network weights is a common method to prevent forgetting previously learned classes while learning novel ones. However, existing regularizers use a constant magnitude throughout the learning sessions, which may not reflect the varying levels of difficulty of the tasks encountered during incremental learning. This study investigates the necessity of adaptive regularization in Class-Incremental Learning, which dynamically adjusts the regularization strength according to the complexity of the task at hand. We propose a Bayesian Optimization-based approach to automatically determine the optimal regularization magnitude for each learning task. Our experiments on two datasets via two regularizers demonstrate the importance of adaptive regularization for achieving accurate and less forgetful visual incremental learning.
Towards Label-Efficient Incremental Learning: A Survey
Feb 11, 2023The current dominant paradigm when building a machine learning model is to iterate over a dataset over and over until convergence. Such an approach is non-incremental, as it assumes access to all images of all categories at once. However, for many applications, non-incremental learning is unrealistic. To that end, researchers study incremental learning, where a learner is required to adapt to an incoming stream of data with a varying distribution while preventing forgetting of past knowledge. Significant progress has been made, however, the vast majority of works focus on the fully supervised setting, making these algorithms label-hungry thus limiting their real-life deployment. To that end, in this paper, we make the first attempt to survey recently growing interest in label-efficient incremental learning. We identify three subdivisions, namely semi-, few-shot- and self-supervised learning to reduce labeling efforts. Finally, we identify novel directions that can further enhance label-efficiency and improve incremental learning scalability. Project website: https://github.com/kilickaya/label-efficient-il.
Are Labels Needed for Incremental Instance Learning?
Feb 02, 2023In this paper, we learn to classify visual object instances, incrementally and via self-supervision (self-incremental). Our learner observes a single instance at a time, which is then discarded from the dataset. Incremental instance learning is challenging, since longer learning sessions exacerbate forgetfulness, and labeling instances is cumbersome. We overcome these challenges via three contributions: i. We propose VINIL, a self-incremental learner that can learn object instances sequentially, ii. We equip VINIL with self-supervision to by-pass the need for instance labelling, iii. We compare VINIL to label-supervised variants on two large-scale benchmarks and show that VINIL significantly improves accuracy while reducing forgetfulness.
Human-Object Interaction Detection via Weak Supervision
Dec 01, 2021



The goal of this paper is Human-object Interaction (HO-I) detection. HO-I detection aims to find interacting human-objects regions and classify their interaction from an image. Researchers obtain significant improvement in recent years by relying on strong HO-I alignment supervision from [5]. HO-I alignment supervision pairs humans with their interacted objects, and then aligns human-object pair(s) with their interaction categories. Since collecting such annotation is expensive, in this paper, we propose to detect HO-I without alignment supervision. We instead rely on image-level supervision that only enumerates existing interactions within the image without pointing where they happen. Our paper makes three contributions: i) We propose Align-Former, a visual-transformer based CNN that can detect HO-I with only image-level supervision. ii) Align-Former is equipped with HO-I align layer, that can learn to select appropriate targets to allow detector supervision. iii) We evaluate Align-Former on HICO-DET [5] and V-COCO [13], and show that Align-Former outperforms existing image-level supervised HO-I detectors by a large margin (4.71% mAP improvement from 16.14% to 20.85% on HICO-DET [5]).
Structured Visual Search via Composition-aware Learning
Oct 27, 2020
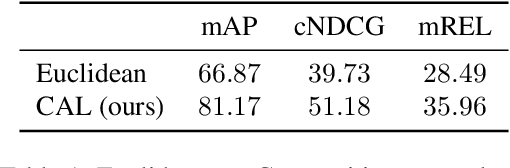
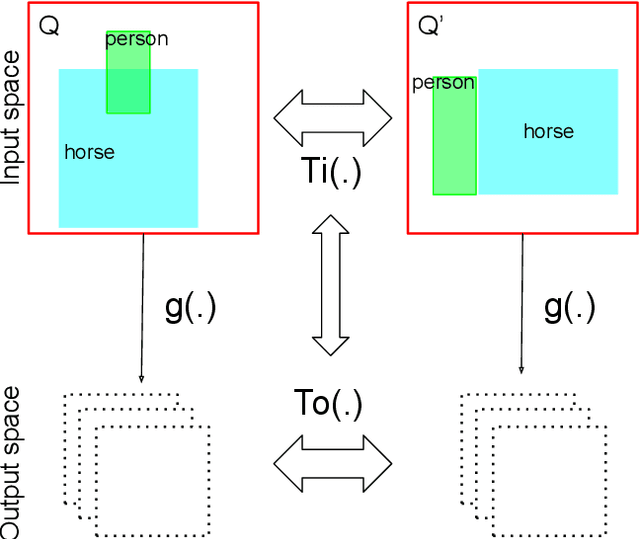
This paper studies visual search using structured queries. The structure is in the form of a 2D composition that encodes the position and the category of the objects. The transformation of the position and the category of the objects leads to a continuous-valued relationship between visual compositions, which carries highly beneficial information, although not leveraged by previous techniques. To that end, in this work, our goal is to leverage these continuous relationships by using the notion of symmetry in equivariance. Our model output is trained to change symmetrically with respect to the input transformations, leading to a sensitive feature space. Doing so leads to a highly efficient search technique, as our approach learns from fewer data using a smaller feature space. Experiments on two large-scale benchmarks of MS-COCO and HICO-DET demonstrates that our approach leads to a considerable gain in the performance against competing techniques.
Self-Selective Context for Interaction Recognition
Oct 17, 2020
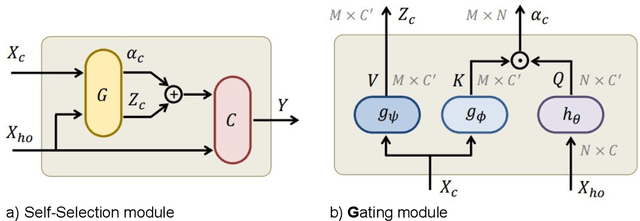

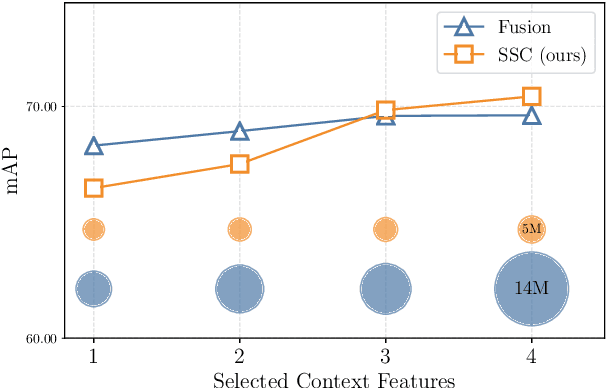
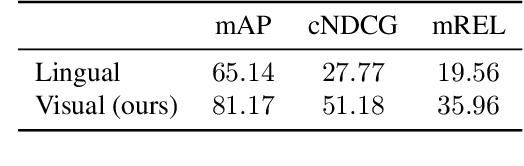
Human-object interaction recognition aims for identifying the relationship between a human subject and an object. Researchers incorporate global scene context into the early layers of deep Convolutional Neural Networks as a solution. They report a significant increase in the performance since generally interactions are correlated with the scene (\ie riding bicycle on the city street). However, this approach leads to the following problems. It increases the network size in the early layers, therefore not efficient. It leads to noisy filter responses when the scene is irrelevant, therefore not accurate. It only leverages scene context whereas human-object interactions offer a multitude of contexts, therefore incomplete. To circumvent these issues, in this work, we propose Self-Selective Context (SSC). SSC operates on the joint appearance of human-objects and context to bring the most discriminative context(s) into play for recognition. We devise novel contextual features that model the locality of human-object interactions and show that SSC can seamlessly integrate with the State-of-the-art interaction recognition models. Our experiments show that SSC leads to an important increase in interaction recognition performance, while using much fewer parameters.
Diagnosing Rarity in Human-Object Interaction Detection
Jun 10, 2020



Human-object interaction (HOI) detection is a core task in computer vision. The goal is to localize all human-object pairs and recognize their interactions. An interaction defined by a <verb, noun> tuple leads to a long-tailed visual recognition challenge since many combinations are rarely represented. The performance of the proposed models is limited especially for the tail categories, but little has been done to understand the reason. To that end, in this paper, we propose to diagnose rarity in HOI detection. We propose a three-step strategy, namely Detection, Identification and Recognition where we carefully analyse the limiting factors by studying state-of-the-art models. Our findings indicate that detection and identification steps are altered by the interaction signals like occlusion and relative location, as a result limiting the recognition accuracy.