 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn genuine invariance learning without weight-tying
Aug 07, 2023



In this paper, we investigate properties and limitations of invariance learned by neural networks from the data compared to the genuine invariance achieved through invariant weight-tying. To do so, we adopt a group theoretical perspective and analyze invariance learning in neural networks without weight-tying constraints. We demonstrate that even when a network learns to correctly classify samples on a group orbit, the underlying decision-making in such a model does not attain genuine invariance. Instead, learned invariance is strongly conditioned on the input data, rendering it unreliable if the input distribution shifts. We next demonstrate how to guide invariance learning toward genuine invariance by regularizing the invariance of a model at the training. To this end, we propose several metrics to quantify learned invariance: (i) predictive distribution invariance, (ii) logit invariance, and (iii) saliency invariance similarity. We show that the invariance learned with the invariance error regularization closely reassembles the genuine invariance of weight-tying models and reliably holds even under a severe input distribution shift. Closer analysis of the learned invariance also reveals the spectral decay phenomenon, when a network chooses to achieve the invariance to a specific transformation group by reducing the sensitivity to any input perturbation.
Learning to Summarize Videos by Contrasting Clips
Jan 13, 2023


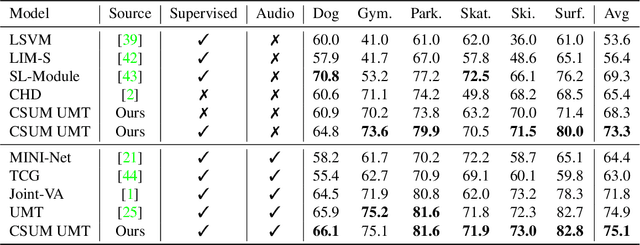
Video summarization aims at choosing parts of a video that narrate a story as close as possible to the original one. Most of the existing video summarization approaches focus on hand-crafted labels. As the number of videos grows exponentially, there emerges an increasing need for methods that can learn meaningful summarizations without labeled annotations. In this paper, we aim to maximally exploit unsupervised video summarization while concentrating the supervision to a few, personalized labels as an add-on. To do so, we formulate the key requirements for the informative video summarization. Then, we propose contrastive learning as the answer to both questions. To further boost Contrastive video Summarization (CSUM), we propose to contrast top-k features instead of a mean video feature as employed by the existing method, which we implement with a differentiable top-k feature selector. Our experiments on several benchmarks demonstrate, that our approach allows for meaningful and diverse summaries when no labeled data is provided.
LieGG: Studying Learned Lie Group Generators
Oct 09, 2022



Symmetries built into a neural network have appeared to be very beneficial for a wide range of tasks as it saves the data to learn them. We depart from the position that when symmetries are not built into a model a priori, it is advantageous for robust networks to learn symmetries directly from the data to fit a task function. In this paper, we present a method to extract symmetries learned by a neural network and to evaluate the degree to which a network is invariant to them. With our method, we are able to explicitly retrieve learned invariances in a form of the generators of corresponding Lie-groups without prior knowledge of symmetries in the data. We use the proposed method to study how symmetrical properties depend on a neural network's parameterization and configuration. We found that the ability of a network to learn symmetries generalizes over a range of architectures. However, the quality of learned symmetries depends on the depth and the number of parameters.
Contrasting quadratic assignments for set-based representation learning
May 31, 2022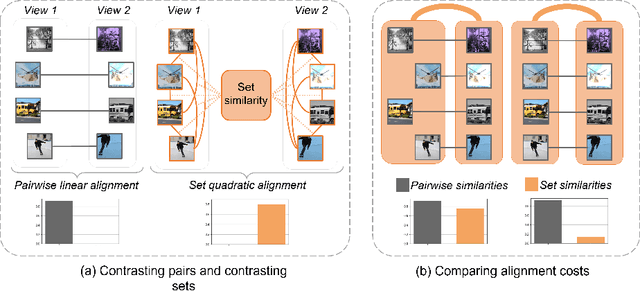

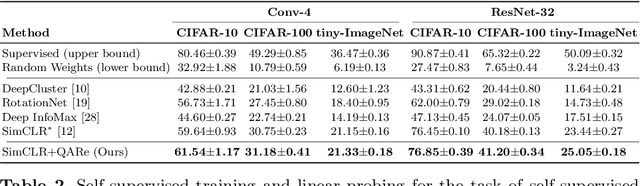
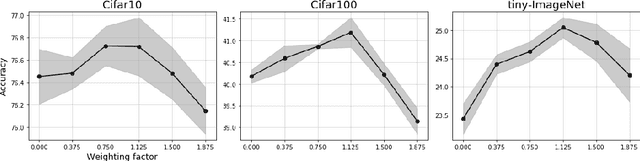
The standard approach to contrastive learning is to maximize the agreement between different views of the data. The views are ordered in pairs, such that they are either positive, encoding different views of the same object, or negative, corresponding to views of different objects. The supervisory signal comes from maximizing the total similarity over positive pairs, while the negative pairs are needed to avoid collapse. In this work, we note that the approach of considering individual pairs cannot account for both intra-set and inter-set similarities when the sets are formed from the views of the data. It thus limits the information content of the supervisory signal available to train representations. We propose to go beyond contrasting individual pairs of objects by focusing on contrasting objects as sets. For this, we use combinatorial quadratic assignment theory designed to evaluate set and graph similarities and derive set-contrastive objective as a regularizer for contrastive learning methods. We conduct experiments and demonstrate that our method improves learned representations for the tasks of metric learning and self-supervised classification.
Human-Object Interaction Detection via Weak Supervision
Dec 01, 2021



The goal of this paper is Human-object Interaction (HO-I) detection. HO-I detection aims to find interacting human-objects regions and classify their interaction from an image. Researchers obtain significant improvement in recent years by relying on strong HO-I alignment supervision from [5]. HO-I alignment supervision pairs humans with their interacted objects, and then aligns human-object pair(s) with their interaction categories. Since collecting such annotation is expensive, in this paper, we propose to detect HO-I without alignment supervision. We instead rely on image-level supervision that only enumerates existing interactions within the image without pointing where they happen. Our paper makes three contributions: i) We propose Align-Former, a visual-transformer based CNN that can detect HO-I with only image-level supervision. ii) Align-Former is equipped with HO-I align layer, that can learn to select appropriate targets to allow detector supervision. iii) We evaluate Align-Former on HICO-DET [5] and V-COCO [13], and show that Align-Former outperforms existing image-level supervised HO-I detectors by a large margin (4.71% mAP improvement from 16.14% to 20.85% on HICO-DET [5]).
Wiggling Weights to Improve the Robustness of Classifiers
Nov 18, 2021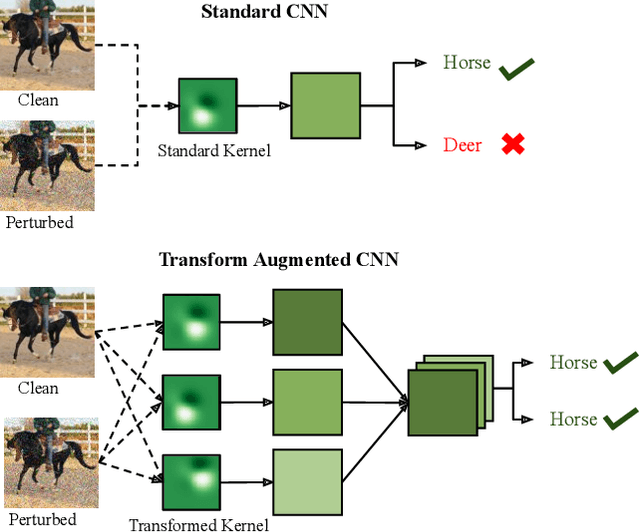
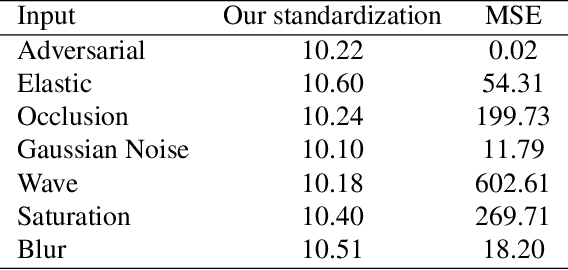
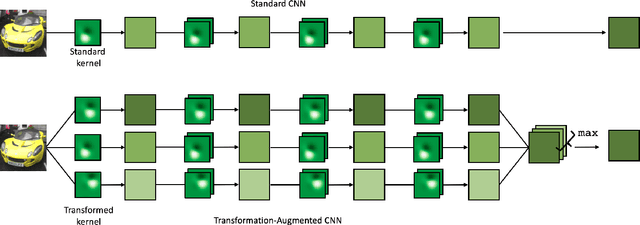

Robustness against unwanted perturbations is an important aspect of deploying neural network classifiers in the real world. Common natural perturbations include noise, saturation, occlusion, viewpoint changes, and blur deformations. All of them can be modelled by the newly proposed transform-augmented convolutional networks. While many approaches for robustness train the network by providing augmented data to the network, we aim to integrate perturbations in the network architecture to achieve improved and more general robustness. To demonstrate that wiggling the weights consistently improves classification, we choose a standard network and modify it to a transform-augmented network. On perturbed CIFAR-10 images, the modified network delivers a better performance than the original network. For the much smaller STL-10 dataset, in addition to delivering better general robustness, wiggling even improves the classification of unperturbed, clean images substantially. We conclude that wiggled transform-augmented networks acquire good robustness even for perturbations not seen during training.
PIE: Pseudo-Invertible Encoder
Oct 31, 2021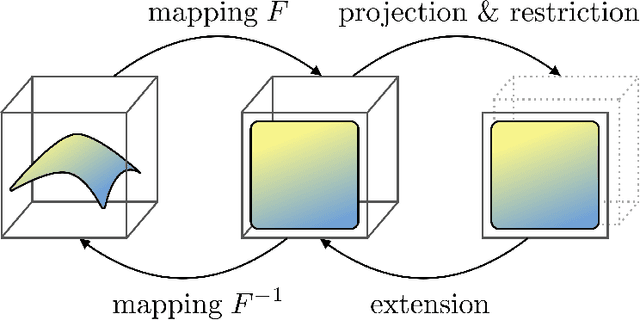


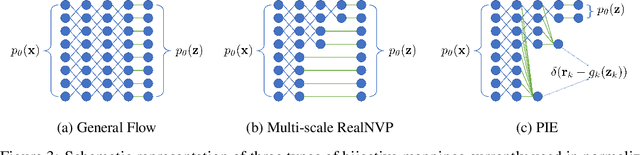
We consider the problem of information compression from high dimensional data. Where many studies consider the problem of compression by non-invertible transformations, we emphasize the importance of invertible compression. We introduce new class of likelihood-based autoencoders with pseudo bijective architecture, which we call Pseudo Invertible Encoders. We provide the theoretical explanation of their principles. We evaluate Gaussian Pseudo Invertible Encoder on MNIST, where our model outperforms WAE and VAE in sharpness of the generated images.
Two is a crowd: tracking relations in videos
Aug 11, 2021
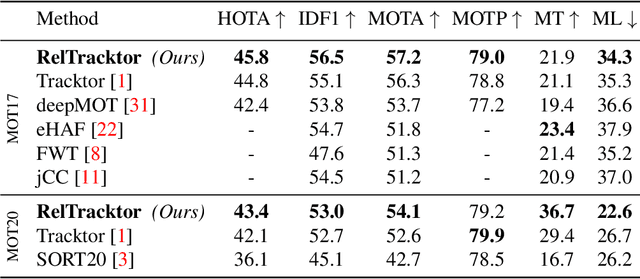

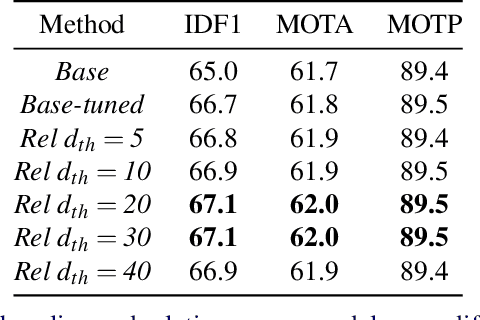
Tracking multiple objects individually differs from tracking groups of related objects. When an object is a part of the group, its trajectory depends on the trajectories of the other group members. Most of the current state-of-the-art trackers follow the approach of tracking each object independently, with the mechanism to handle the overlapping trajectories where necessary. Such an approach does not take inter-object relations into account, which may cause unreliable tracking for the members of the groups, especially in crowded scenarios, where individual cues become unreliable due to occlusions. To overcome these limitations and to extend such trackers to crowded scenes, we propose a plug-in Relation Encoding Module (REM). REM encodes relations between tracked objects by running a message passing over a corresponding spatio-temporal graph, computing relation embeddings for the tracked objects. Our experiments on MOT17 and MOT20 demonstrate that the baseline tracker improves its results after a simple extension with REM. The proposed module allows for tracking severely or even fully occluded objects by utilizing relational cues.
Built-in Elastic Transformations for Improved Robustness
Jul 20, 2021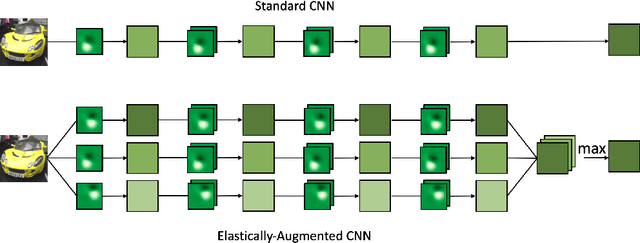
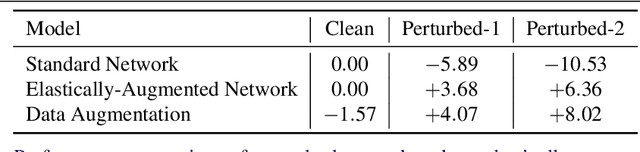
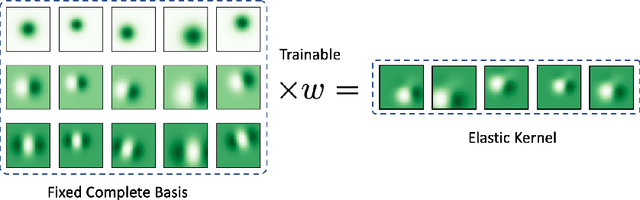
We focus on building robustness in the convolutions of neural visual classifiers, especially against natural perturbations like elastic deformations, occlusions and Gaussian noise. Existing CNNs show outstanding performance on clean images, but fail to tackle naturally occurring perturbations. In this paper, we start from elastic perturbations, which approximate (local) view-point changes of the object. We present elastically-augmented convolutions (EAConv) by parameterizing filters as a combination of fixed elastically-perturbed bases functions and trainable weights for the purpose of integrating unseen viewpoints in the CNN. We show on CIFAR-10 and STL-10 datasets that the general robustness of our method on unseen occlusion and Gaussian perturbations improves, while even improving the performance on clean images slightly without performing any data augmentation.
DISCO: accurate Discrete Scale Convolutions
Jun 04, 2021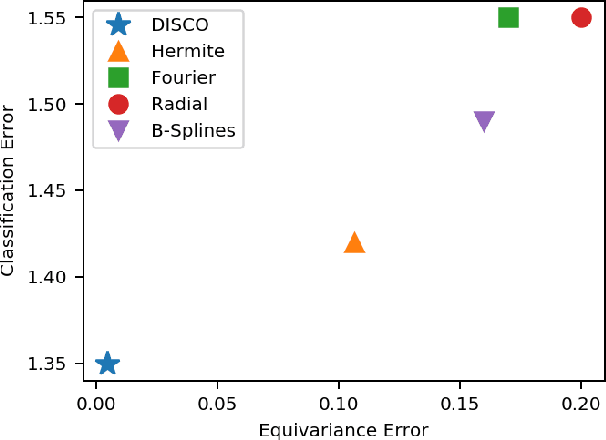

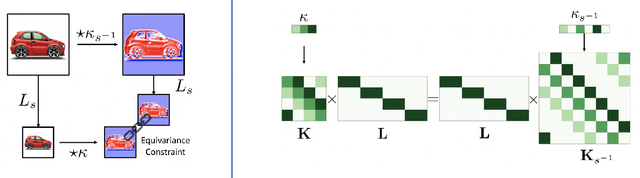
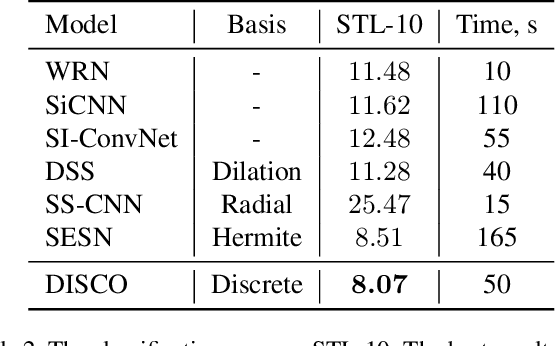
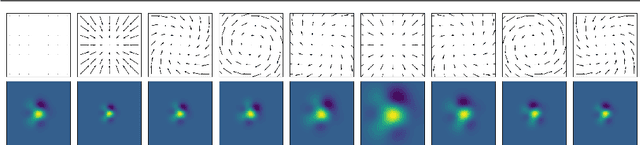
Scale is often seen as a given, disturbing factor in many vision tasks. When doing so it is one of the factors why we need more data during learning. In recent work scale equivariance was added to convolutional neural networks. It was shown to be effective for a range of tasks. We aim for accurate scale-equivariant convolutional neural networks (SE-CNNs) applicable for problems where high granularity of scale and small filter sizes are required. Current SE-CNNs rely on weight sharing and filter rescaling, the latter of which is accurate for integer scales only. To reach accurate scale equivariance, we derive general constraints under which scale-convolution remains equivariant to discrete rescaling. We find the exact solution for all cases where it exists, and compute the approximation for the rest. The discrete scale-convolution pays off, as demonstrated in a new state-of-the-art classification on MNIST-scale and improving the results on STL-10. With the same SE scheme, we also improve the computational effort of a scale-equivariant Siamese tracker on OTB-13.