 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the VC dimension of deep group convolutional neural networks
Oct 21, 2024We study the generalization capabilities of Group Convolutional Neural Networks (GCNNs) with ReLU activation function by deriving upper and lower bounds for their Vapnik-Chervonenkis (VC) dimension. Specifically, we analyze how factors such as the number of layers, weights, and input dimension affect the VC dimension. We further compare the derived bounds to those known for other types of neural networks. Our findings extend previous results on the VC dimension of continuous GCNNs with two layers, thereby providing new insights into the generalization properties of GCNNs, particularly regarding the dependence on the input resolution of the data.
On genuine invariance learning without weight-tying
Aug 07, 2023



In this paper, we investigate properties and limitations of invariance learned by neural networks from the data compared to the genuine invariance achieved through invariant weight-tying. To do so, we adopt a group theoretical perspective and analyze invariance learning in neural networks without weight-tying constraints. We demonstrate that even when a network learns to correctly classify samples on a group orbit, the underlying decision-making in such a model does not attain genuine invariance. Instead, learned invariance is strongly conditioned on the input data, rendering it unreliable if the input distribution shifts. We next demonstrate how to guide invariance learning toward genuine invariance by regularizing the invariance of a model at the training. To this end, we propose several metrics to quantify learned invariance: (i) predictive distribution invariance, (ii) logit invariance, and (iii) saliency invariance similarity. We show that the invariance learned with the invariance error regularization closely reassembles the genuine invariance of weight-tying models and reliably holds even under a severe input distribution shift. Closer analysis of the learned invariance also reveals the spectral decay phenomenon, when a network chooses to achieve the invariance to a specific transformation group by reducing the sensitivity to any input perturbation.
VC dimensions of group convolutional neural networks
Dec 19, 2022We study the generalization capacity of group convolutional neural networks. We identify precise estimates for the VC dimensions of simple sets of group convolutional neural networks. In particular, we find that for infinite groups and appropriately chosen convolutional kernels, already two-parameter families of convolutional neural networks have an infinite VC dimension, despite being invariant to the action of an infinite group.
LieGG: Studying Learned Lie Group Generators
Oct 09, 2022



Symmetries built into a neural network have appeared to be very beneficial for a wide range of tasks as it saves the data to learn them. We depart from the position that when symmetries are not built into a model a priori, it is advantageous for robust networks to learn symmetries directly from the data to fit a task function. In this paper, we present a method to extract symmetries learned by a neural network and to evaluate the degree to which a network is invariant to them. With our method, we are able to explicitly retrieve learned invariances in a form of the generators of corresponding Lie-groups without prior knowledge of symmetries in the data. We use the proposed method to study how symmetrical properties depend on a neural network's parameterization and configuration. We found that the ability of a network to learn symmetries generalizes over a range of architectures. However, the quality of learned symmetries depends on the depth and the number of parameters.
Evaluating Disentangled Representations
Oct 12, 2019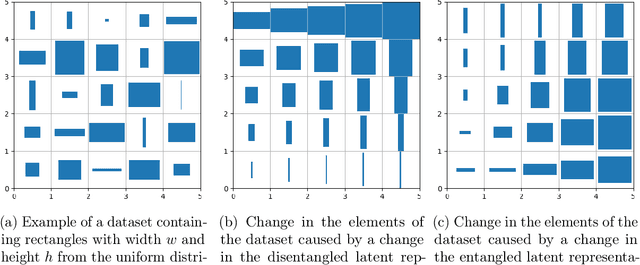
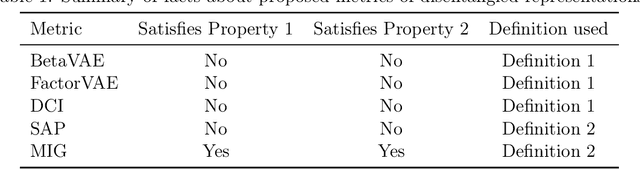
There is no generally agreed upon definition of disentangled representation. Intuitively, the data is generated by a few factors of variation, which are captured and separated in a disentangled representation. Disentangled representations are useful for many tasks such as reinforcement learning, transfer learning, and zero-shot learning. However, the absence of a formally accepted definition makes it difficult to evaluate algorithms for learning disentangled representations. Recently, important steps have been taken towards evaluating disentangled representations: the existing metrics of disentanglement were compared through an experimental study and a framework for the quantitative evaluation of disentangled representations was proposed. However, theoretical guarantees for existing metrics of disentanglement are still missing. In this paper, we analyze metrics of disentanglement and their properties. Specifically, we analyze if the metrics satisfy two desirable properties: (1)~give a high score to representations that are disentangled according to the definition; and (2)~give a low score to representations that are entangled according to the definition. We show that most of the current metrics do not satisfy at least one of these properties. Consequently, we propose a new definition for a metric of disentanglement that satisfies both of the properties.