 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal pieces: analysing and improving spiking neural networks piece by piece
Apr 18, 2025We introduce a novel concept for spiking neural networks (SNNs) derived from the idea of "linear pieces" used to analyse the expressiveness and trainability of artificial neural networks (ANNs). We prove that the input domain of SNNs decomposes into distinct causal regions where its output spike times are locally Lipschitz continuous with respect to the input spike times and network parameters. The number of such regions - which we call "causal pieces" - is a measure of the approximation capabilities of SNNs. In particular, we demonstrate in simulation that parameter initialisations which yield a high number of causal pieces on the training set strongly correlate with SNN training success. Moreover, we find that feedforward SNNs with purely positive weights exhibit a surprisingly high number of causal pieces, allowing them to achieve competitive performance levels on benchmark tasks. We believe that causal pieces are not only a powerful and principled tool for improving SNNs, but might also open up new ways of comparing SNNs and ANNs in the future.
Regularized Gauss-Newton for Optimizing Overparameterized Neural Networks
Apr 23, 2024The generalized Gauss-Newton (GGN) optimization method incorporates curvature estimates into its solution steps, and provides a good approximation to the Newton method for large-scale optimization problems. GGN has been found particularly interesting for practical training of deep neural networks, not only for its impressive convergence speed, but also for its close relation with neural tangent kernel regression, which is central to recent studies that aim to understand the optimization and generalization properties of neural networks. This work studies a GGN method for optimizing a two-layer neural network with explicit regularization. In particular, we consider a class of generalized self-concordant (GSC) functions that provide smooth approximations to commonly-used penalty terms in the objective function of the optimization problem. This approach provides an adaptive learning rate selection technique that requires little to no tuning for optimal performance. We study the convergence of the two-layer neural network, considered to be overparameterized, in the optimization loop of the resulting GGN method for a given scaling of the network parameters. Our numerical experiments highlight specific aspects of GSC regularization that help to improve generalization of the optimized neural network. The code to reproduce the experimental results is available at https://github.com/adeyemiadeoye/ggn-score-nn.
Efficient Learning Using Spiking Neural Networks Equipped With Affine Encoders and Decoders
Apr 06, 2024We study the learning problem associated with spiking neural networks. Specifically, we consider hypothesis sets of spiking neural networks with affine temporal encoders and decoders and simple spiking neurons having only positive synaptic weights. We demonstrate that the positivity of the weights continues to enable a wide range of expressivity results, including rate-optimal approximation of smooth functions or approximation without the curse of dimensionality. Moreover, positive-weight spiking neural networks are shown to depend continuously on their parameters which facilitates classical covering number-based generalization statements. Finally, we observe that from a generalization perspective, contrary to feedforward neural networks or previous results for general spiking neural networks, the depth has little to no adverse effect on the generalization capabilities.
Mathematical Capabilities of ChatGPT
Jan 31, 2023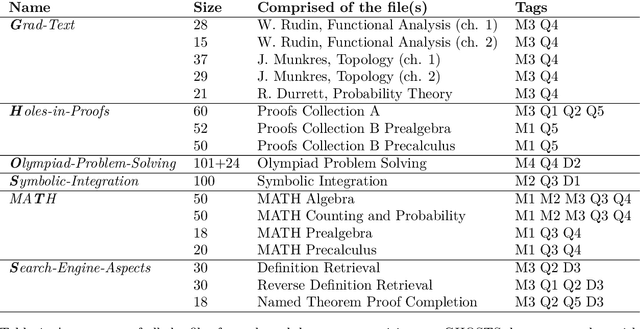


We investigate the mathematical capabilities of ChatGPT by testing it on publicly available datasets, as well as hand-crafted ones, and measuring its performance against other models trained on a mathematical corpus, such as Minerva. We also test whether ChatGPT can be a useful assistant to professional mathematicians by emulating various use cases that come up in the daily professional activities of mathematicians (question answering, theorem searching). In contrast to formal mathematics, where large databases of formal proofs are available (e.g., the Lean Mathematical Library), current datasets of natural-language mathematics, used to benchmark language models, only cover elementary mathematics. We address this issue by introducing a new dataset: GHOSTS. It is the first natural-language dataset made and curated by working researchers in mathematics that (1) aims to cover graduate-level mathematics and (2) provides a holistic overview of the mathematical capabilities of language models. We benchmark ChatGPT on GHOSTS and evaluate performance against fine-grained criteria. We make this new dataset publicly available to assist a community-driven comparison of ChatGPT with (future) large language models in terms of advanced mathematical comprehension. We conclude that contrary to many positive reports in the media (a potential case of selection bias), ChatGPT's mathematical abilities are significantly below those of an average mathematics graduate student. Our results show that ChatGPT often understands the question but fails to provide correct solutions. Hence, if your goal is to use it to pass a university exam, you would be better off copying from your average peer!
VC dimensions of group convolutional neural networks
Dec 19, 2022We study the generalization capacity of group convolutional neural networks. We identify precise estimates for the VC dimensions of simple sets of group convolutional neural networks. In particular, we find that for infinite groups and appropriately chosen convolutional kernels, already two-parameter families of convolutional neural networks have an infinite VC dimension, despite being invariant to the action of an infinite group.
Limitations of neural network training due to numerical instability of backpropagation
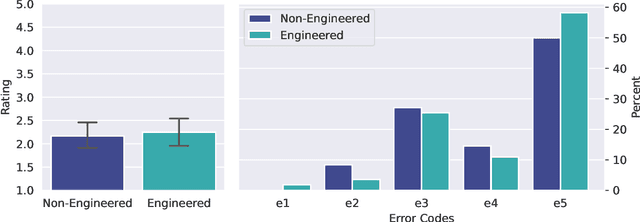
Oct 06, 2022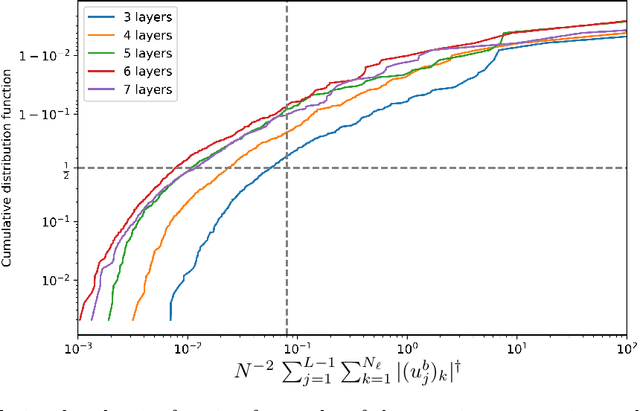
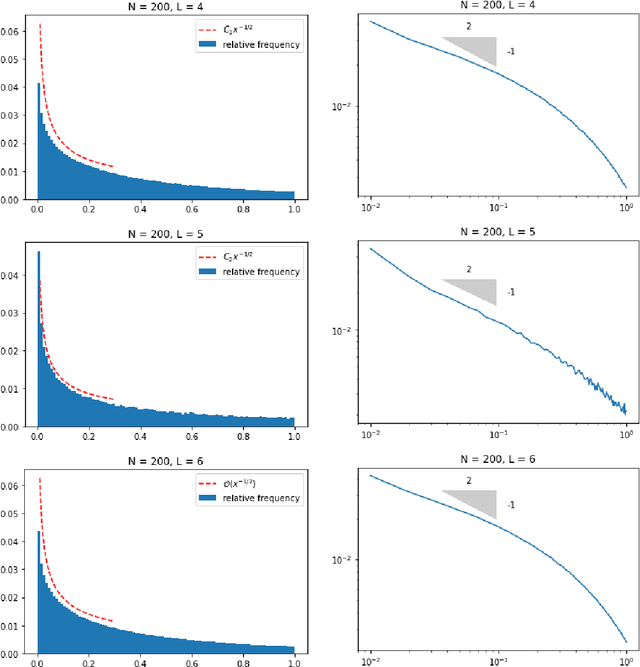
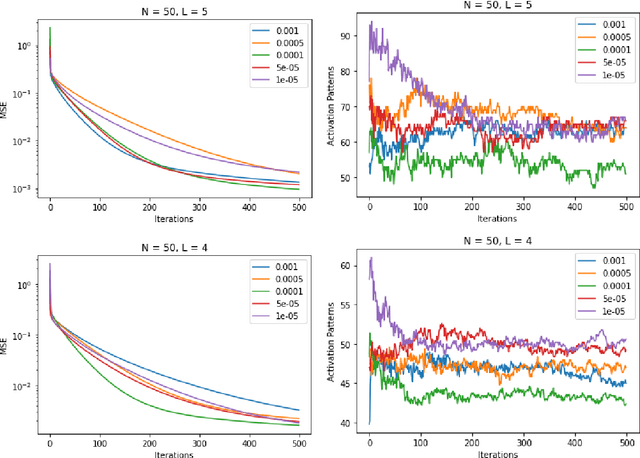
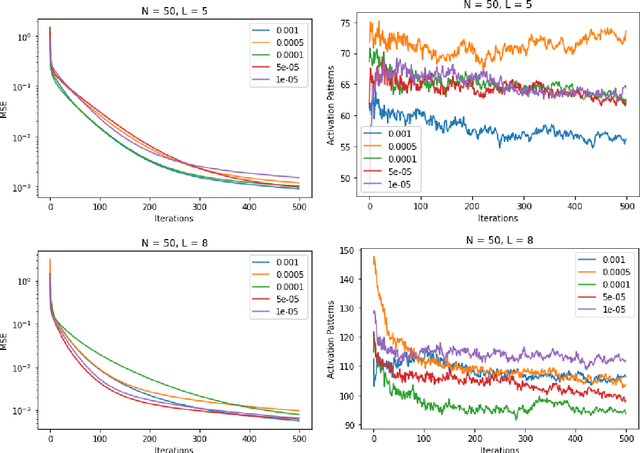
We study the training of deep neural networks by gradient descent where floating-point arithmetic is used to compute the gradients. In this framework and under realistic assumptions, we demonstrate that it is highly unlikely to find ReLU neural networks that maintain, in the course of training with gradient descent, superlinearly many affine pieces with respect to their number of layers. In virtually all approximation theoretical arguments which yield high order polynomial rates of approximation, sequences of ReLU neural networks with exponentially many affine pieces compared to their numbers of layers are used. As a consequence, we conclude that approximating sequences of ReLU neural networks resulting from gradient descent in practice differ substantially from theoretically constructed sequences. The assumptions and the theoretical results are compared to a numerical study, which yields concurring results.
Deep neural networks can stably solve high-dimensional, noisy, non-linear inverse problems
Jun 07, 2022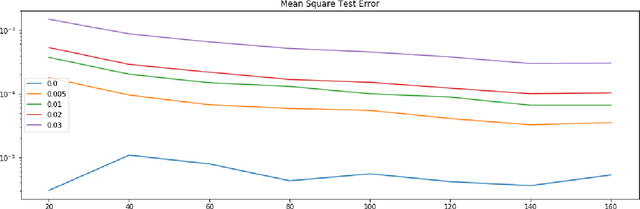



We study the problem of reconstructing solutions of inverse problems with neural networks when only noisy data is available. We assume that the problem can be modeled with an infinite-dimensional forward operator that is not continuously invertible. Then, we restrict this forward operator to finite-dimensional spaces so that the inverse is Lipschitz continuous. For the inverse operator, we demonstrate that there exists a neural network which is a robust-to-noise approximation of the operator. In addition, we show that these neural networks can be learned from appropriately perturbed training data. We demonstrate the admissibility of this approach to a wide range of inverse problems of practical interest. Numerical examples are given that support the theoretical findings.
The Oracle of DLphi
Jan 27, 2019We present a novel technique based on deep learning and set theory which yields exceptional classification and prediction results. Having access to a sufficiently large amount of labelled training data, our methodology is capable of predicting the labels of the test data almost always even if the training data is entirely unrelated to the test data. In other words, we prove in a specific setting that as long as one has access to enough data points, the quality of the data is irrelevant.