 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Gauss-Newton Optimization for Training Deep Neural Networks
May 23, 2024We present EGN, a stochastic second-order optimization algorithm that combines the generalized Gauss-Newton (GN) Hessian approximation with low-rank linear algebra to compute the descent direction. Leveraging the Duncan-Guttman matrix identity, the parameter update is obtained by factorizing a matrix which has the size of the mini-batch. This is particularly advantageous for large-scale machine learning problems where the dimension of the neural network parameter vector is several orders of magnitude larger than the batch size. Additionally, we show how improvements such as line search, adaptive regularization, and momentum can be seamlessly added to EGN to further accelerate the algorithm. Moreover, under mild assumptions, we prove that our algorithm converges to an $\epsilon$-stationary point at a linear rate. Finally, our numerical experiments demonstrate that EGN consistently exceeds, or at most matches the generalization performance of well-tuned SGD, Adam, and SGN optimizers across various supervised and reinforcement learning tasks.
Regularized Gauss-Newton for Optimizing Overparameterized Neural Networks
Apr 23, 2024The generalized Gauss-Newton (GGN) optimization method incorporates curvature estimates into its solution steps, and provides a good approximation to the Newton method for large-scale optimization problems. GGN has been found particularly interesting for practical training of deep neural networks, not only for its impressive convergence speed, but also for its close relation with neural tangent kernel regression, which is central to recent studies that aim to understand the optimization and generalization properties of neural networks. This work studies a GGN method for optimizing a two-layer neural network with explicit regularization. In particular, we consider a class of generalized self-concordant (GSC) functions that provide smooth approximations to commonly-used penalty terms in the objective function of the optimization problem. This approach provides an adaptive learning rate selection technique that requires little to no tuning for optimal performance. We study the convergence of the two-layer neural network, considered to be overparameterized, in the optimization loop of the resulting GGN method for a given scaling of the network parameters. Our numerical experiments highlight specific aspects of GSC regularization that help to improve generalization of the optimized neural network. The code to reproduce the experimental results is available at https://github.com/adeyemiadeoye/ggn-score-nn.
Self-concordant Smoothing for Convex Composite Optimization
Sep 04, 2023We introduce the notion of self-concordant smoothing for minimizing the sum of two convex functions: the first is smooth and the second may be nonsmooth. Our framework results naturally from the smoothing approximation technique referred to as partial smoothing in which only a part of the nonsmooth function is smoothed. The key highlight of our approach is in a natural property of the resulting problem's structure which provides us with a variable-metric selection method and a step-length selection rule particularly suitable for proximal Newton-type algorithms. In addition, we efficiently handle specific structures promoted by the nonsmooth function, such as $\ell_1$-regularization and group-lasso penalties. We prove local quadratic convergence rates for two resulting algorithms: Prox-N-SCORE, a proximal Newton algorithm and Prox-GGN-SCORE, a proximal generalized Gauss-Newton (GGN) algorithm. The Prox-GGN-SCORE algorithm highlights an important approximation procedure which helps to significantly reduce most of the computational overhead associated with the inverse Hessian. This approximation is essentially useful for overparameterized machine learning models and in the mini-batch settings. Numerical examples on both synthetic and real datasets demonstrate the efficiency of our approach and its superiority over existing approaches.
SC-Reg: Training Overparameterized Neural Networks under Self-Concordant Regularization
Dec 14, 2021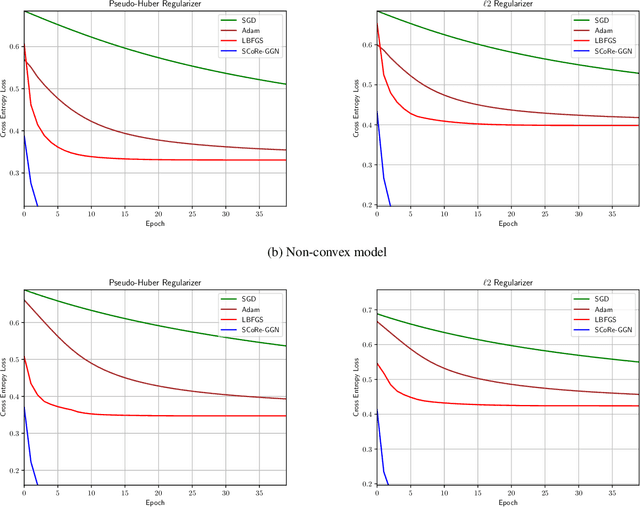

In this paper we propose the SC-Reg (self-concordant regularization) framework for learning overparameterized feedforward neural networks by incorporating second-order information in the \emph{Newton decrement} framework for convex problems. We propose the generalized Gauss-Newton with Self-Concordant Regularization (SCoRe-GGN) algorithm that updates the network parameters each time it receives a new input batch. The proposed algorithm exploits the structure of the second-order information in the Hessian matrix, thereby reducing the training computational overhead. Although our current analysis considers only the convex case, numerical experiments show the efficiency of our method and its fast convergence under both convex and non-convex settings, which compare favorably against baseline first-order methods and a quasi-Newton method.