 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStress-Testing LiDAR Registration
Apr 16, 2022
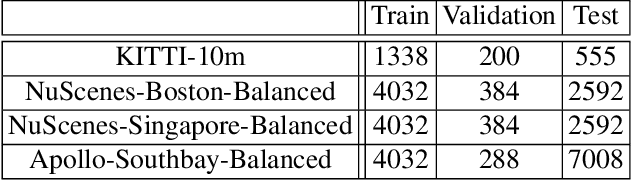
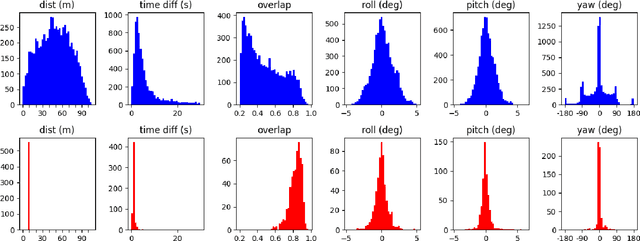
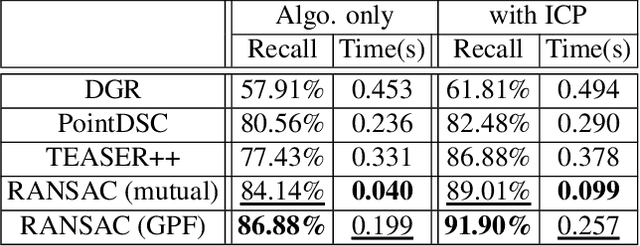
Point cloud registration (PCR) is an important task in many fields including autonomous driving with LiDAR sensors. PCR algorithms have improved significantly in recent years, by combining deep-learned features with robust estimation methods. These algorithms succeed in scenarios such as indoor scenes and object models registration. However, testing in the automotive LiDAR setting, which presents its own challenges, has been limited. The standard benchmark for this setting, KITTI-10m, has essentially been saturated by recent algorithms: many of them achieve near-perfect recall. In this work, we stress-test recent PCR techniques with LiDAR data. We propose a method for selecting balanced registration sets, which are challenging sets of frame-pairs from LiDAR datasets. They contain a balanced representation of the different relative motions that appear in a dataset, i.e. small and large rotations, small and large offsets in space and time, and various combinations of these. We perform a thorough comparison of accuracy and run-time on these benchmarks. Perhaps unexpectedly, we find that the fastest and simultaneously most accurate approach is a version of advanced RANSAC. We further improve results with a novel pre-filtering method.
DeepBBS: Deep Best Buddies for Point Cloud Registration
Oct 16, 2021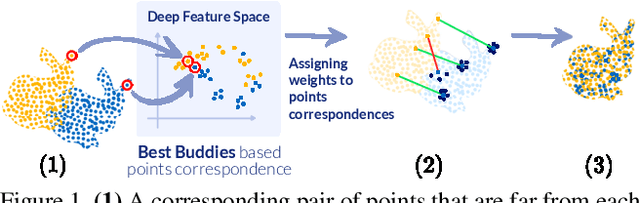
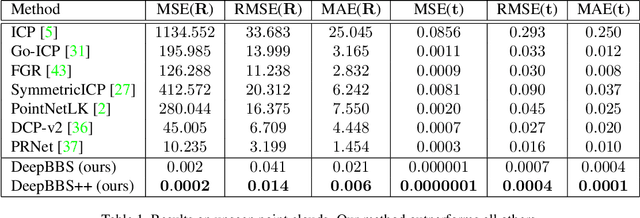
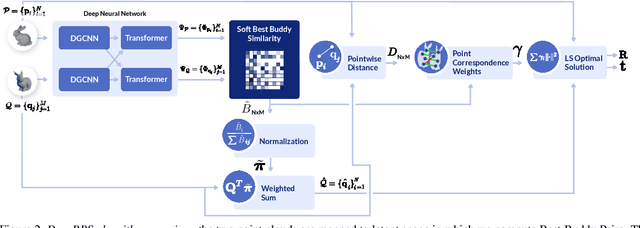

Recently, several deep learning approaches have been proposed for point cloud registration. These methods train a network to generate a representation that helps finding matching points in two 3D point clouds. Finding good matches allows them to calculate the transformation between the point clouds accurately. Two challenges of these techniques are dealing with occlusions and generalizing to objects of classes unseen during training. This work proposes DeepBBS, a novel method for learning a representation that takes into account the best buddy distance between points during training. Best Buddies (i.e., mutual nearest neighbors) are pairs of points nearest to each other. The Best Buddies criterion is a strong indication for correct matches that, in turn, leads to accurate registration. Our experiments show improved performance compared to previous methods. In particular, our learned representation leads to an accurate registration for partial shapes and in unseen categories.
Best Buddies Registration for Point Clouds
Oct 05, 2020


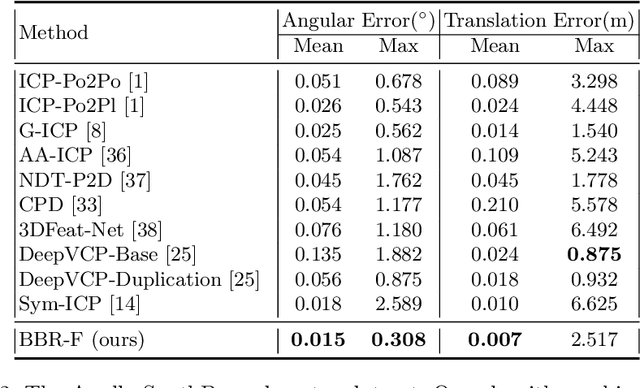
We propose new, and robust, loss functions for the point cloud registration problem. Our loss functions are inspired by the Best Buddies Similarity (BBS) measure that counts the number of mutual nearest neighbors between two point sets. This measure has been shown to be robust to outliers and missing data in the case of template matching for images. We present several algorithms, collectively named Best Buddy Registration (BBR), where each algorithm consists of optimizing one of these loss functions with Adam gradient descent. The loss functions differ in several ways, including the distance function used (point-to-point vs. point-to-plane), and how the BBS measure is combined with the actual distances between pairs of points. Experiments on various data sets, both synthetic and real, demonstrate the effectiveness of the BBR algorithms, showing that they are quite robust to noise, outliers, and distractors, and cope well with extremely sparse point clouds. One variant, BBR-F, achieves state-of-the-art accuracy in the registration of automotive lidar scans taken up to several seconds apart, from the KITTI and Apollo-Southbay datasets.
The Oracle of DLphi
Jan 27, 2019We present a novel technique based on deep learning and set theory which yields exceptional classification and prediction results. Having access to a sufficiently large amount of labelled training data, our methodology is capable of predicting the labels of the test data almost always even if the training data is entirely unrelated to the test data. In other words, we prove in a specific setting that as long as one has access to enough data points, the quality of the data is irrelevant.
On the Resistance of Neural Nets to Label Noise
Mar 30, 2018
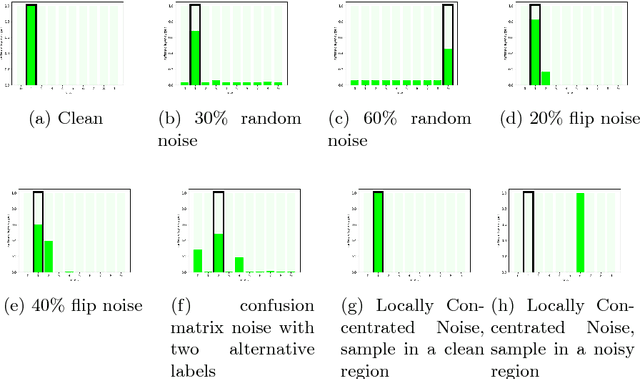
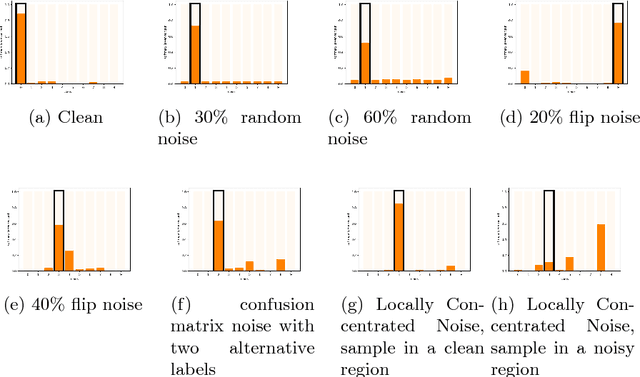
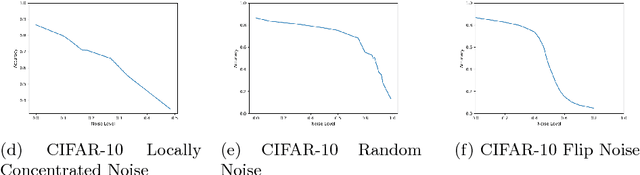
We investigate the behavior of convolutional neural networks (CNN) in the presence of label noise. We show empirically that CNN prediction for a given test sample depends on the labels of the training samples in its local neighborhood. This is similar to the way that the K-nearest neighbors (K-NN) classifier works. With this understanding, we derive an analytical expression for the expected accuracy of a K-NN, and hence a CNN, classifier for any level of noise. In particular, we show that K-NN, and CNN, are resistant to label noise that is randomly spread across the training set, but are very sensitive to label noise that is concentrated. Experiments on real datasets validate our analytical expression by showing that they match the empirical results for varying degrees of label noise.