 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedistributor: Transforming Empirical Data Distributions
Oct 25, 2022



We present an algorithm and package, Redistributor, which forces a collection of scalar samples to follow a desired distribution. When given independent and identically distributed samples of some random variable $S$ and the continuous cumulative distribution function of some desired target $T$, it provably produces a consistent estimator of the transformation $R$ which satisfies $R(S)=T$ in distribution. As the distribution of $S$ or $T$ may be unknown, we also include algorithms for efficiently estimating these distributions from samples. This allows for various interesting use cases in image processing, where Redistributor serves as a remarkably simple and easy-to-use tool that is capable of producing visually appealing results. The package is implemented in Python and is optimized to efficiently handle large data sets, making it also suitable as a preprocessing step in machine learning. The source code is available at https://gitlab.com/paloha/redistributor.
How degenerate is the parametrization of neural networks with the ReLU activation function?
May 23, 2019


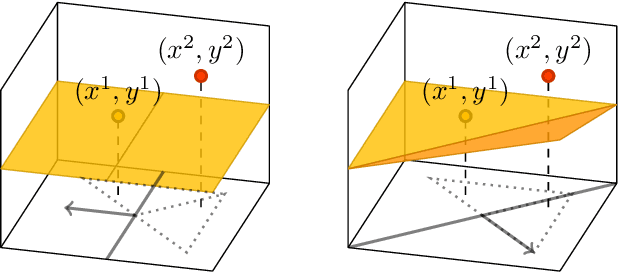
Neural network training is usually accomplished by solving a non-convex optimization problem using stochastic gradient descent. Although one optimizes over the networks parameters, the loss function generally only depends on the realization of a neural network, i.e. the function it computes. Studying the functional optimization problem over the space of realizations can open up completely new ways to understand neural network training. In particular, usual loss functions like the mean squared error are convex on sets of neural network realizations, which themselves are non-convex. Note, however, that each realization has many different, possibly degenerate, parametrizations. In particular, a local minimum in the parametrization space needs not correspond to a local minimum in the realization space. To establish such a connection, inverse stability of the realization map is required, meaning that proximity of realizations must imply proximity of corresponding parametrizations. In this paper we present pathologies which prevent inverse stability in general, and proceed to establish a restricted set of parametrizations on which we have inverse stability w.r.t. to a Sobolev norm. Furthermore, we show that by optimizing over such restricted sets, it is still possible to learn any function, which can be learned by optimization over unrestricted sets. While most of this paper focuses on shallow networks, none of methods used are, in principle, limited to shallow networks, and it should be possible to extend them to deep neural networks.
Towards a regularity theory for ReLU networks -- chain rule and global error estimates
May 13, 2019

Although for neural networks with locally Lipschitz continuous activation functions the classical derivative exists almost everywhere, the standard chain rule is in general not applicable. We will consider a way of introducing a derivative for neural networks that admits a chain rule, which is both rigorous and easy to work with. In addition we will present a method of converting approximation results on bounded domains to global (pointwise) estimates. This can be used to extend known neural network approximation theory to include the study of regularity properties. Of particular interest is the application to neural networks with ReLU activation function, where it contributes to the understanding of the success of deep learning methods for high-dimensional partial differential equations.
The Oracle of DLphi
Jan 27, 2019We present a novel technique based on deep learning and set theory which yields exceptional classification and prediction results. Having access to a sufficiently large amount of labelled training data, our methodology is capable of predicting the labels of the test data almost always even if the training data is entirely unrelated to the test data. In other words, we prove in a specific setting that as long as one has access to enough data points, the quality of the data is irrelevant.
Deep Neural Network Approximation Theory
Jan 08, 2019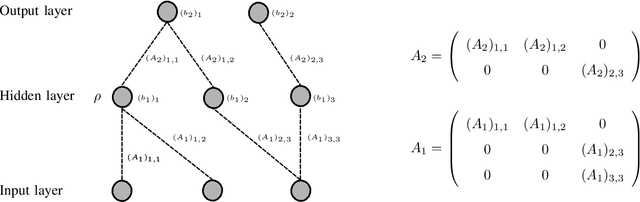
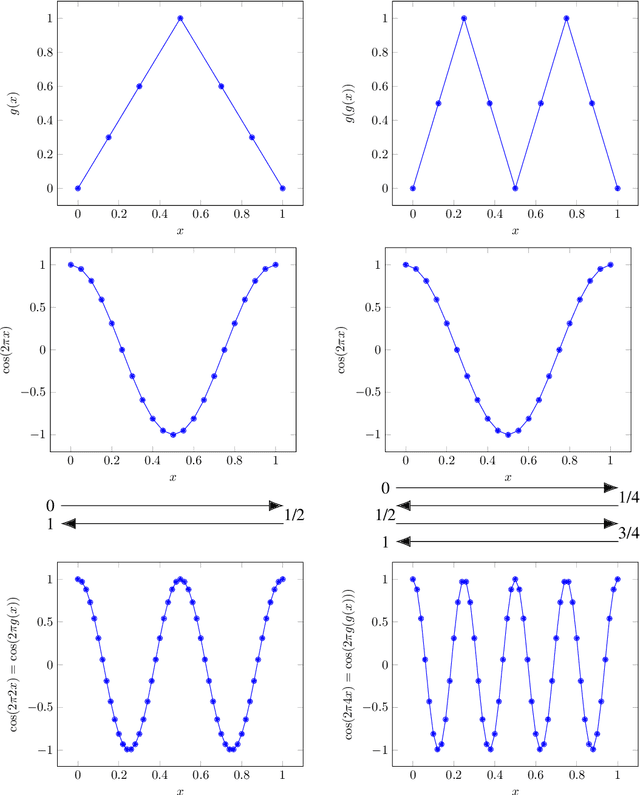
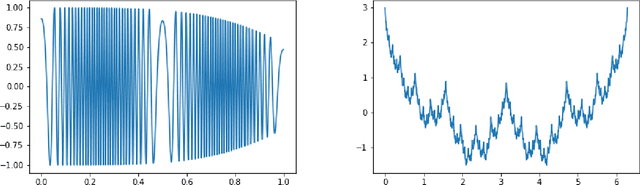
Deep neural networks have become state-of-the-art technology for a wide range of practical machine learning tasks such as image classification, handwritten digit recognition, speech recognition, or game intelligence. This paper develops the fundamental limits of learning in deep neural networks by characterizing what is possible if no constraints on the learning algorithm and the amount of training data are imposed. Concretely, we consider information-theoretically optimal approximation through deep neural networks with the guiding theme being a relation between the complexity of the function (class) to be approximated and the complexity of the approximating network in terms of connectivity and memory requirements for storing the network topology and the associated quantized weights. The theory we develop educes remarkable universality properties of deep networks. Specifically, deep networks are optimal approximants for vastly different function classes such as affine systems and Gabor systems. This universality is afforded by a concurrent invariance property of deep networks to time-shifts, scalings, and frequency-shifts. In addition, deep networks provide exponential approximation accuracy i.e., the approximation error decays exponentially in the number of non-zero weights in the network of vastly different functions such as the squaring operation, multiplication, polynomials, sinusoidal functions, general smooth functions, and even one-dimensional oscillatory textures and fractal functions such as the Weierstrass function, both of which do not have any known methods achieving exponential approximation accuracy. In summary, deep neural networks provide information-theoretically optimal approximation of a very wide range of functions and function classes used in mathematical signal processing.
The universal approximation power of finite-width deep ReLU networks
Jun 05, 2018
We show that finite-width deep ReLU neural networks yield rate-distortion optimal approximation (B\"olcskei et al., 2018) of polynomials, windowed sinusoidal functions, one-dimensional oscillatory textures, and the Weierstrass function, a fractal function which is continuous but nowhere differentiable. Together with their recently established universal approximation property of affine function systems (B\"olcskei et al., 2018), this shows that deep neural networks approximate vastly different signal structures generated by the affine group, the Weyl-Heisenberg group, or through warping, and even certain fractals, all with approximation error decaying exponentially in the number of neurons. We also prove that in the approximation of sufficiently smooth functions finite-width deep networks require strictly smaller connectivity than finite-depth wide networks.