 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFakET: Simulating Cryo-Electron Tomograms with Neural Style Transfer
Apr 04, 2023Particle localization and -classification constitute two of the most fundamental problems in computational microscopy. In recent years, deep learning based approaches have been introduced for these tasks with great success. A key shortcoming of these supervised learning methods is their need for large training data sets, typically generated from particle models in conjunction with complex numerical forward models simulating the physics of transmission electron microscopes. Computer implementations of such forward models are computationally extremely demanding and limit the scope of their applicability. In this paper we propose a simple method for simulating the forward operator of an electron microscope based on additive noise and Neural Style Transfer techniques. We evaluate the method on localization and classification tasks using one of the established state-of-the-art architectures showing performance on par with the benchmark. In contrast to previous approaches, our method accelerates the data generation process by a factor of 750 while using 33 times less memory and scales well to typical transmission electron microscope detector sizes. It utilizes GPU acceleration and parallel processing. It can be used as a stand-alone method to adapt a training data set or as a data augmentation technique. The source code is available at https://gitlab.com/deepet/faket.
Redistributor: Transforming Empirical Data Distributions
Oct 25, 2022



We present an algorithm and package, Redistributor, which forces a collection of scalar samples to follow a desired distribution. When given independent and identically distributed samples of some random variable $S$ and the continuous cumulative distribution function of some desired target $T$, it provably produces a consistent estimator of the transformation $R$ which satisfies $R(S)=T$ in distribution. As the distribution of $S$ or $T$ may be unknown, we also include algorithms for efficiently estimating these distributions from samples. This allows for various interesting use cases in image processing, where Redistributor serves as a remarkably simple and easy-to-use tool that is capable of producing visually appealing results. The package is implemented in Python and is optimized to efficiently handle large data sets, making it also suitable as a preprocessing step in machine learning. The source code is available at https://gitlab.com/paloha/redistributor.
Towards Robust Voice Pathology Detection
Jul 13, 2019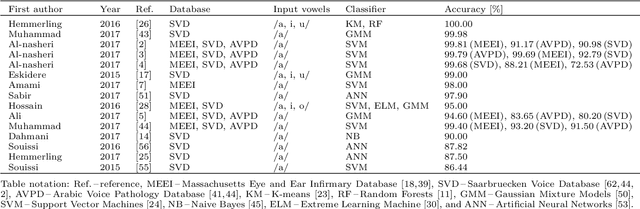
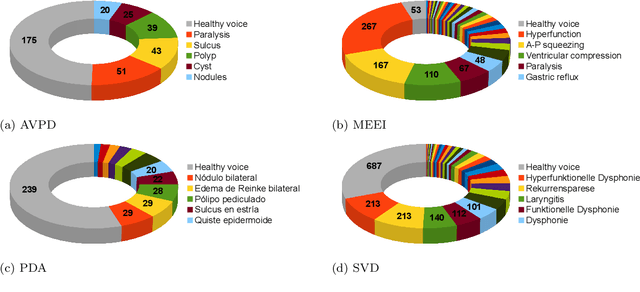
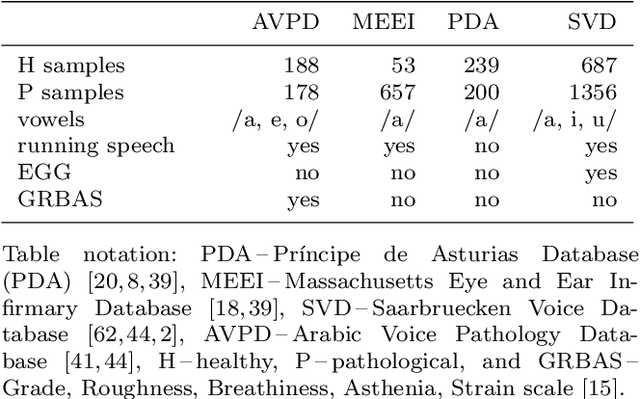
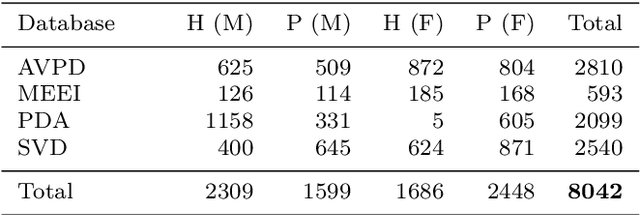
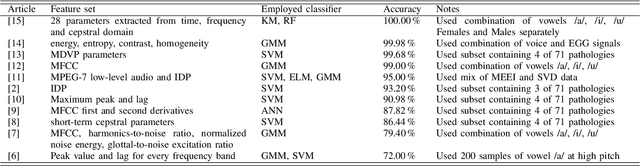
Automatic objective non-invasive detection of pathological voice based on computerized analysis of acoustic signals can play an important role in early diagnosis, progression tracking and even effective treatment of pathological voices. In search towards such a robust voice pathology detection system we investigated 3 distinct classifiers within supervised learning and anomaly detection paradigms. We conducted a set of experiments using a variety of input data such as raw waveforms, spectrograms, mel-frequency cepstral coefficients (MFCC) and conventional acoustic (dysphonic) features (AF). In comparison with previously published works, this article is the first to utilize combination of 4 different databases comprising normophonic and pathological recordings of sustained phonation of the vowel /a/ unrestricted to a subset of vocal pathologies. Furthermore, to our best knowledge, this article is the first to explore gradient boosted trees and deep learning for this application. The following best classification performances measured by F1 score on dedicated test set were achieved: XGBoost (0.733) using AF and MFCC, DenseNet (0.621) using MFCC, and Isolation Forest (0.610) using AF. Even though these results are of exploratory character, conducted experiments do show promising potential of gradient boosting and deep learning methods to robustly detect voice pathologies.
* 11 pages, 1 figure, 10 tables. Keywords: Voice pathology detection, deep learning, gradient boosting, anomaly detection
Voice Pathology Detection Using Deep Learning: a Preliminary Study
Jul 12, 2019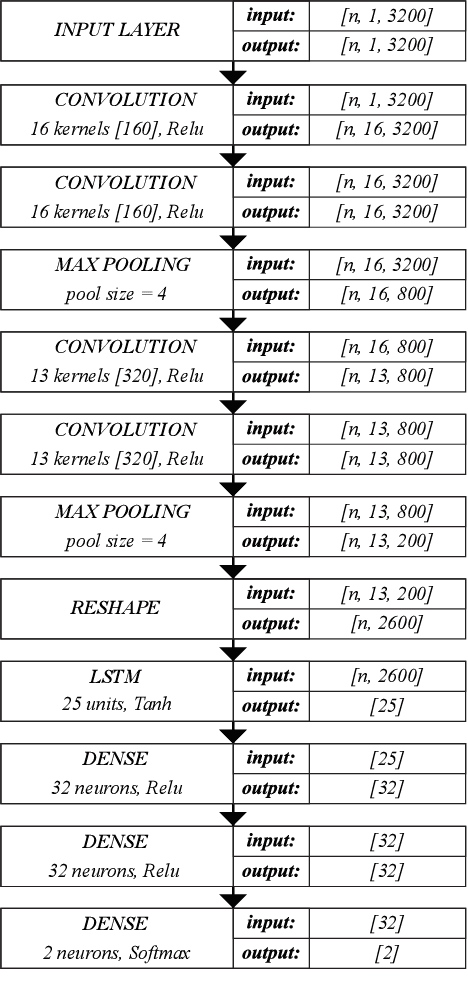


This paper describes a preliminary investigation of Voice Pathology Detection using Deep Neural Networks (DNN). We used voice recordings of sustained vowel /a/ produced at normal pitch from German corpus Saarbruecken Voice Database (SVD). This corpus contains voice recordings and electroglottograph signals of more than 2 000 speakers. The idea behind this experiment is the use of convolutional layers in combination with recurrent Long-Short-Term-Memory (LSTM) layers on raw audio signal. Each recording was split into 64 ms Hamming windowed segments with 30 ms overlap. Our trained model achieved 71.36% accuracy with 65.04% sensitivity and 77.67% specificity on 206 validation files and 68.08% accuracy with 66.75% sensitivity and 77.89% specificity on 874 testing files. This is a promising result in favor of this approach because it is comparable to similar previously published experiment that used different methodology. Further investigation is needed to achieve the state-of-the-art results.
* 4 pages, 1 figure, 5 tables
Machines listening to music: the role of signal representations in learning from music
Mar 27, 2019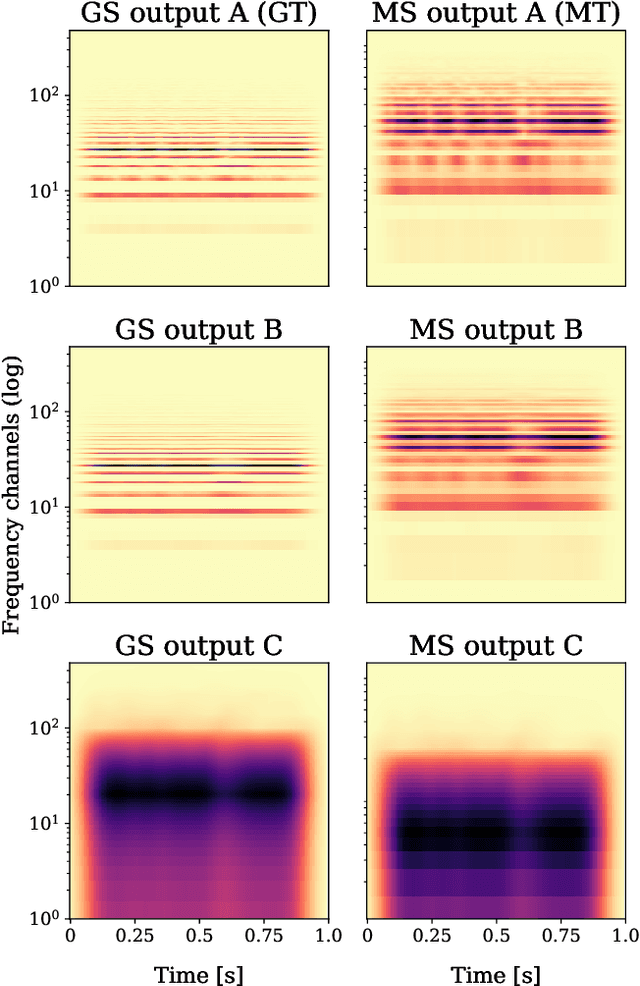
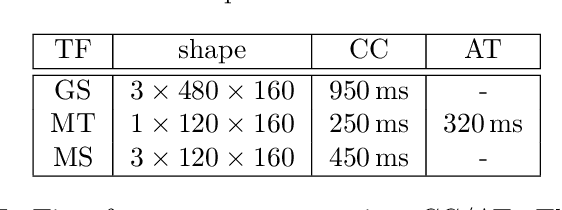
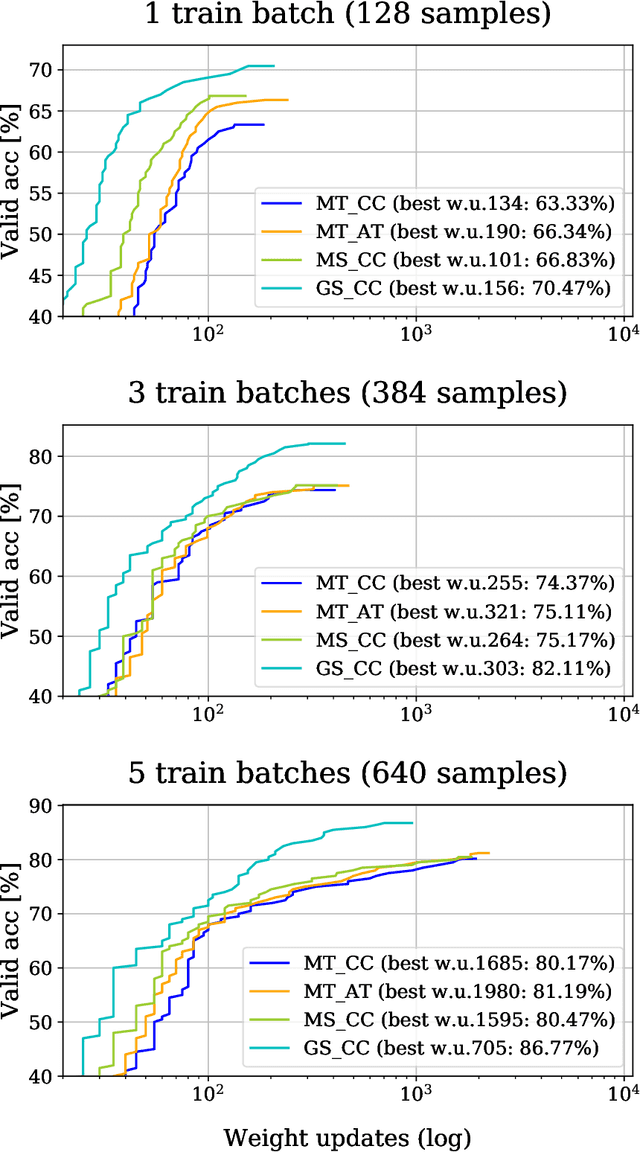
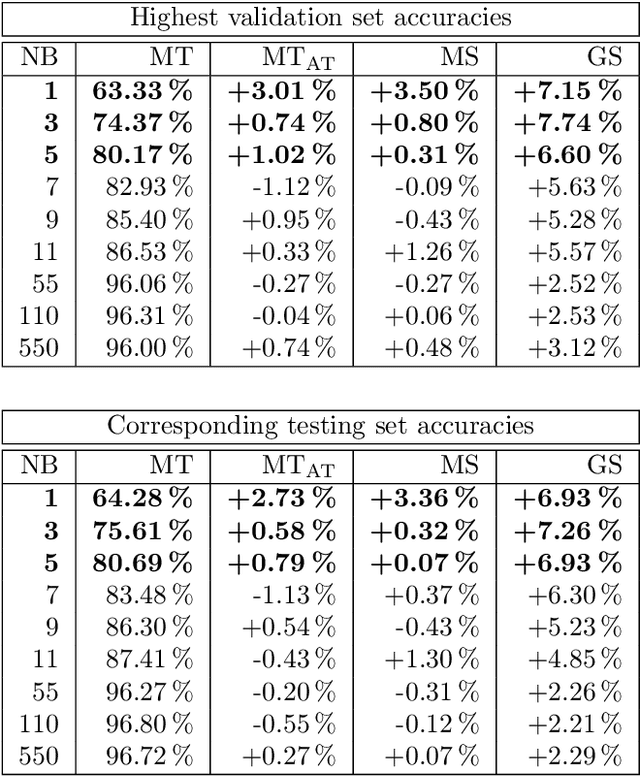
Recent, extremely successful methods in deep learning, such as convolutional neural networks (CNNs) have originated in machine learning for images. When applied to music signals and related music information retrieval (MIR) problems, researchers often apply standard FFT-based signal processing methods in order to create an image from the raw audio data. The impact of this basic signal processing step on the final outcome of the MIR task has not been widely studied and is not well understood. In this contribution, we study Gabor Scattering and a new representation, namely Mel Scattering. Furthermore, we suggest an alternative enhancement of the loss function that uses transformed representations of the output data to incorporate additional available information. We show how applying various different signal analysis methods can lead to useful invariances and improve the overall performance in MIR problems by reducing the amount of necessary training data or the necessity of augmentation.
On orthogonal projections for dimension reduction and applications in variational loss functions for learning problems
Jan 22, 2019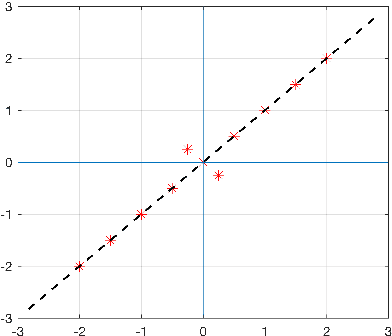
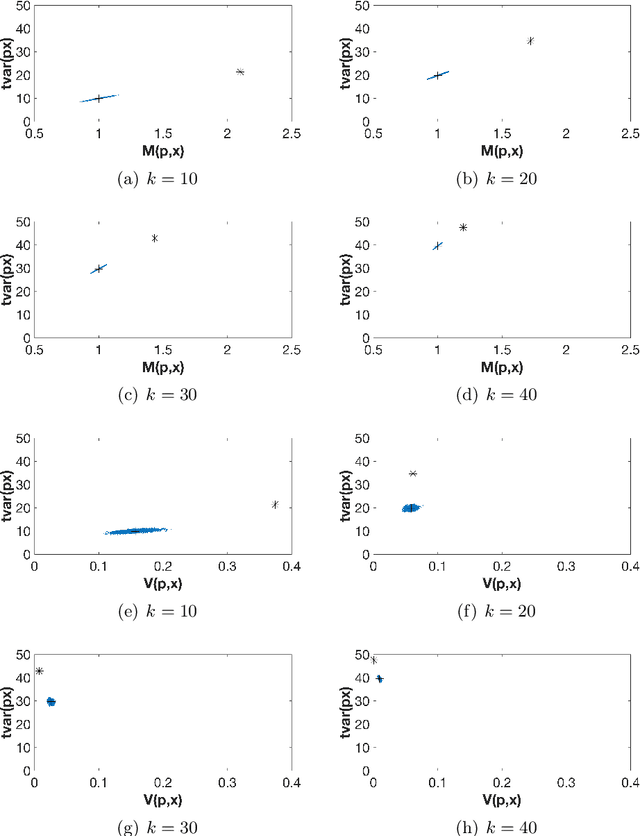
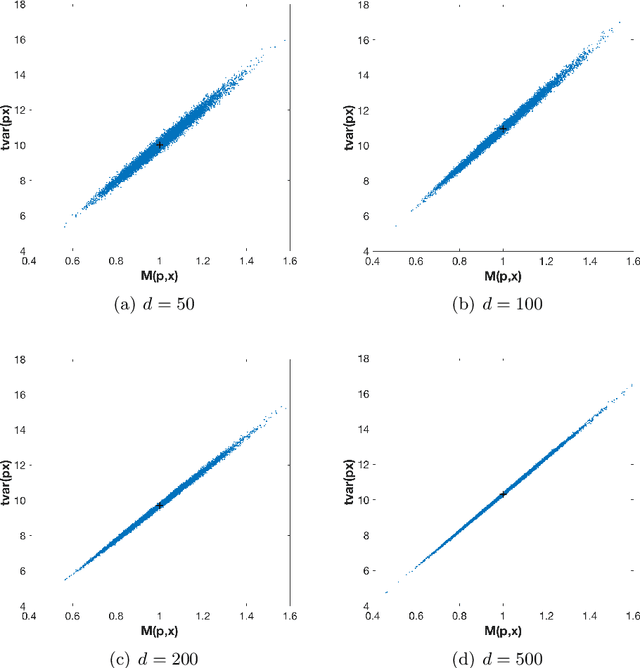
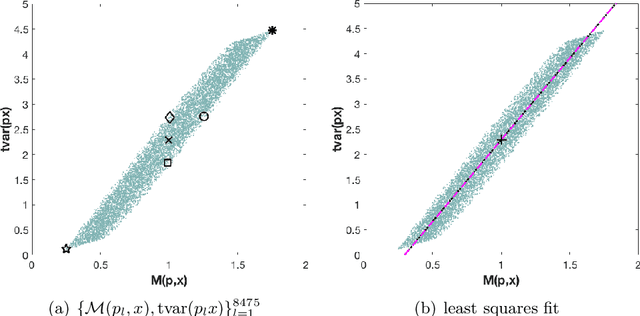
The use of orthogonal projections on high-dimensional input and target data in learning frameworks is studied. First, we investigate the relations between two standard objectives in dimension reduction, maximizing variance and preservation of pairwise relative distances. The derivation of their asymptotic correlation and numerical experiments tell that a projection usually cannot satisfy both objectives. In a standard classification problem we determine projections on the input data that balance them and compare subsequent results. Next, we extend our application of orthogonal projections to deep learning frameworks. We introduce new variational loss functions that enable integration of additional information via transformations and projections of the target data. In two supervised learning problems, clinical image segmentation and music information classification, the application of the proposed loss functions increase the accuracy.