 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessment of Developmental Dysgraphia Utilising a Display Tablet
Oct 23, 2024Even though the computerised assessment of developmental dysgraphia (DD) based on online handwriting processing has increasing popularity, most of the solutions are based on a setup, where a child writes on a paper fixed to a digitizing tablet that is connected to a computer. Although this approach enables the standard way of writing using an inking pen, it is difficult to be administered by children themselves. The main goal of this study is thus to explore, whether the quantitative analysis of online handwriting recorded via a display screen tablet could sufficiently support the assessment of DD as well. For the purpose of this study, we enrolled 144 children (attending the 3rd and 4th class of a primary school), whose handwriting proficiency was assessed by a special education counsellor, and who assessed themselves by the Handwriting Proficiency Screening Questionnaires for Children (HPSQ C). Using machine learning models based on a gradient-boosting algorithm, we were able to support the DD diagnosis with up to 83.6% accuracy. The HPSQ C total score was estimated with a minimum error equal to 10.34 %. Children with DD spent significantly higher time in-air, they had a higher number of pen elevations, a bigger height of on-surface strokes, a lower in-air tempo, and a higher variation in the angular velocity. Although this study shows a promising impact of DD assessment via display tablets, it also accents the fact that modelling of subjective scores is challenging and a complex and data-driven quantification of DD manifestations is needed.
* 16 pages
Prodromal Diagnosis of Lewy Body Diseases Based on the Assessment of Graphomotor and Handwriting Difficulties
Jan 20, 2023To this date, studies focusing on the prodromal diagnosis of Lewy body diseases (LBDs) based on quantitative analysis of graphomotor and handwriting difficulties are missing. In this work, we enrolled 18 subjects diagnosed with possible or probable mild cognitive impairment with Lewy bodies (MCI-LB), 7 subjects having more than 50% probability of developing Parkinson's disease (PD), 21 subjects with both possible/probable MCI-LB and probability of PD > 50%, and 37 age- and gender-matched healthy controls (HC). Each participant performed three tasks: Archimedean spiral drawing (to quantify graphomotor difficulties), sentence writing task (to quantify handwriting difficulties), and pentagon copying test (to quantify cognitive decline). Next, we parameterized the acquired data by various temporal, kinematic, dynamic, spatial, and task-specific features. And finally, we trained classification models for each task separately as well as a model for their combination to estimate the predictive power of the features for the identification of LBDs. Using this approach we were able to identify prodromal LBDs with 74% accuracy and showed the promising potential of computerized objective and non-invasive diagnosis of LBDs based on the assessment of graphomotor and handwriting difficulties.
* Print ISBN 978-3-031-19744-4
Exploration of Various Fractional Order Derivatives in Parkinson's Disease Dysgraphia Analysis
Jan 20, 2023Parkinson's disease (PD) is a common neurodegenerative disorder with a prevalence rate estimated to 2.0% for people aged over 65 years. Cardinal motor symptoms of PD such as rigidity and bradykinesia affect the muscles involved in the handwriting process resulting in handwriting abnormalities called PD dysgraphia. Nowadays, online handwritten signal (signal with temporal information) acquired by the digitizing tablets is the most advanced approach of graphomotor difficulties analysis. Although the basic kinematic features were proved to effectively quantify the symptoms of PD dysgraphia, a recent research identified that the theory of fractional calculus can be used to improve the graphomotor difficulties analysis. Therefore, in this study, we follow up on our previous research, and we aim to explore the utilization of various approaches of fractional order derivative (FD) in the analysis of PD dysgraphia. For this purpose, we used the repetitive loops task from the Parkinson's disease handwriting database (PaHaW). Handwritten signals were parametrized by the kinematic features employing three FD approximations: Gr\"unwald-Letnikov's, Riemann-Liouville's, and Caputo's. Results of the correlation analysis revealed a significant relationship between the clinical state and the handwriting features based on the velocity. The extracted features by Caputo's FD approximation outperformed the rest of the analyzed FD approaches. This was also confirmed by the results of the classification analysis, where the best model trained by Caputo's handwriting features resulted in a balanced accuracy of 79.73% with a sensitivity of 83.78% and a specificity of 75.68%.
* Print ISBN 978-3-031-19744-4
Perceptual Features as Markers of Parkinson's Disease: The Issue of Clinical Interpretability
Mar 21, 2022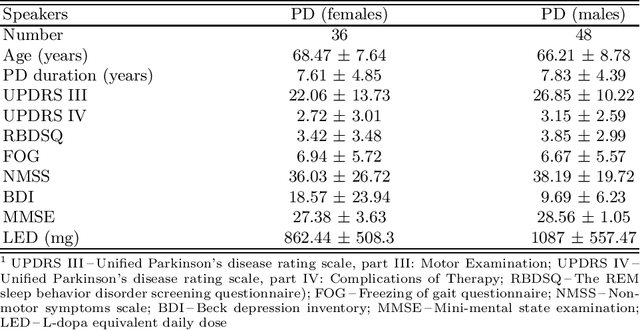
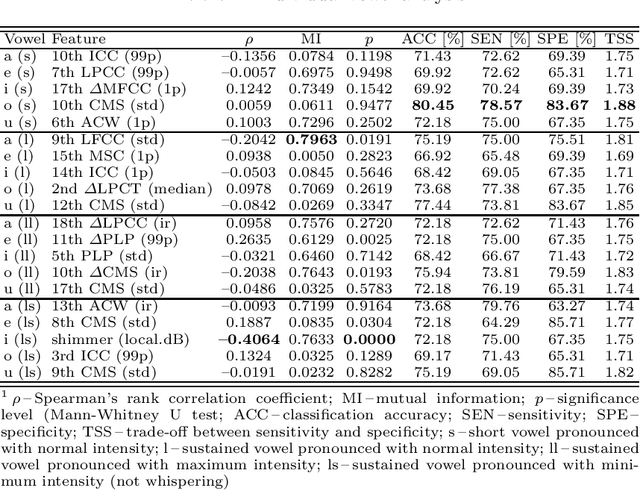
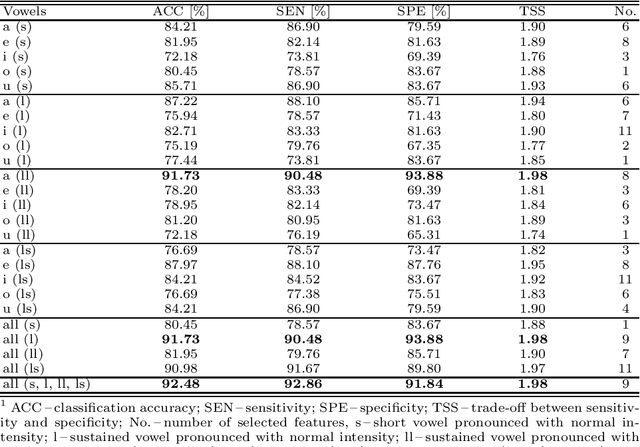

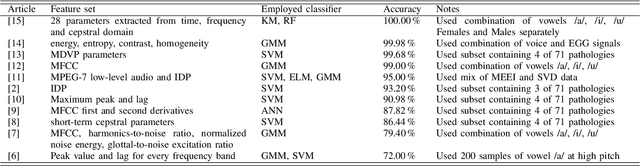
Up to 90% of patients with Parkinson's disease (PD) suffer from hypokinetic dysathria (HD) which is also manifested in the field of phonation. Clinical signs of HD like monoloudness, monopitch or hoarse voice are usually quantified by conventional clinical interpretable features (jitter, shimmer, harmonic-to-noise ratio, etc.). This paper provides large and robust insight into perceptual analysis of 5 Czech vowels of 84 PD patients and proves that despite the clinical inexplicability the perceptual features outperform the conventional ones, especially in terms of discrimination power (classification accuracy ACC = 92 %, sensitivity SEN = 93 %, specificity SPE = 92 %) and partial correlation with clinical scores like UPDRS (Unified Parkinson's disease rating scale), MMSE (Mini-mental state examination) or FOG (Freezing of gait questionnaire), where p < 0.0001.
* 8 pages, published in International Conference on NONLINEAR SPEECH PROCESSING, NOLISP 2015 jointly organized with the 25th Italian Workshop on Neural Networks, WIRN 2015, held at May 2015, Vietri sul Mare, Salerno, Italy
Identification of Hypokinetic Dysarthria Using Acoustic Analysis of Poem Recitation
Mar 18, 2022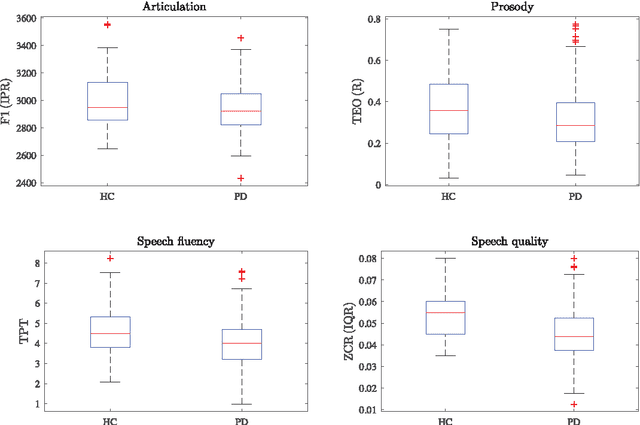

Up to 90 % of patients with Parkinson's disease (PD) suffer from hypokinetic dysarthria (HD). In this work, we analysed the power of conventional speech features quantifying imprecise articulation, dysprosody, speech dysfluency and speech quality deterioration extracted from a specialized poem recitation task to discriminate dysarthric and healthy speech. For this purpose, 152 speakers (53 healthy speakers, 99 PD patients) were examined. Only mildly strong correlation between speech features and clinical status of the speakers was observed. In the case of univariate classification analysis, sensitivity of 62.63% (imprecise articulation), 61.62% (dysprosody), 71.72% (speech dysfluency) and 59.60% (speech quality deterioration) was achieved. Multivariate classification analysis improved the classification performance. Sensitivity of 83.42% using only two features describing imprecise articulation and speech quality deterioration in HD was achieved. We showed the promising potential of the selected speech features and especially the use of poem recitation task to quantify and identify HD in PD.
Robust and Complex Approach of Pathological Speech Signal Analysis
Mar 17, 2022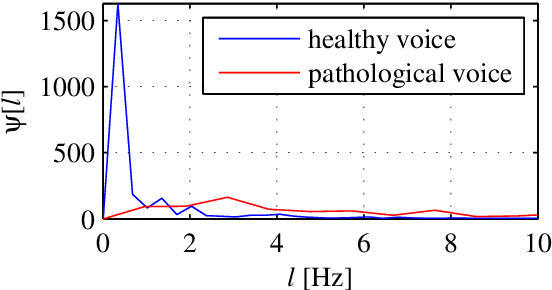

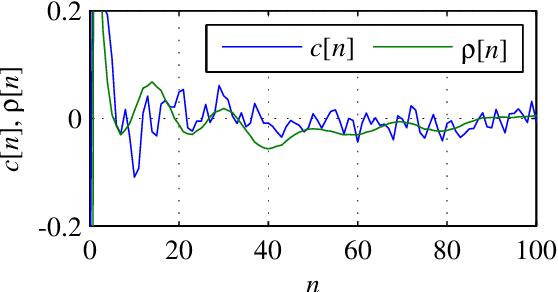
This paper presents a study of the approaches in the state-of-the-art in the field of pathological speech signal analysis with a special focus on parametrization techniques. It provides a description of 92 speech features where some of them are already widely used in this field of science and some of them have not been tried yet (they come from different areas of speech signal processing like speech recognition or coding). As an original contribution, this work introduces 36 completely new pathological voice measures based on modulation spectra, inferior colliculus coefficients, bicepstrum, sample and approximate entropy and empirical mode decomposition. The significance of these features was tested on 3 (English, Spanish and Czech) pathological voice databases with respect to classification accuracy, sensitivity and specificity.
* 41 pages, published in Neurocomputing, Volume 167, 2015, Pages 94-111, ISSN 0925-2312
Assessing Progress of Parkinson s Disease Using Acoustic Analysis of Phonation
Mar 17, 2022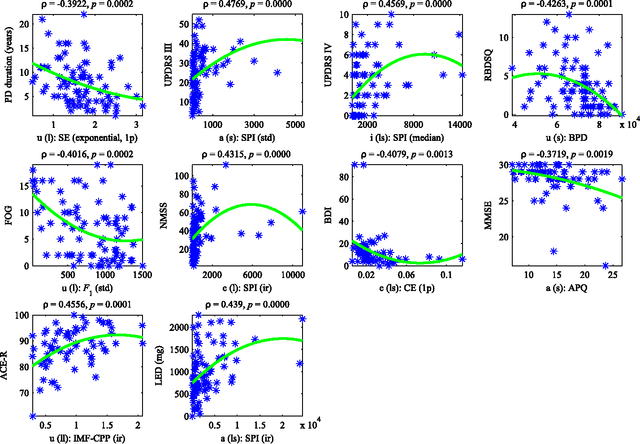
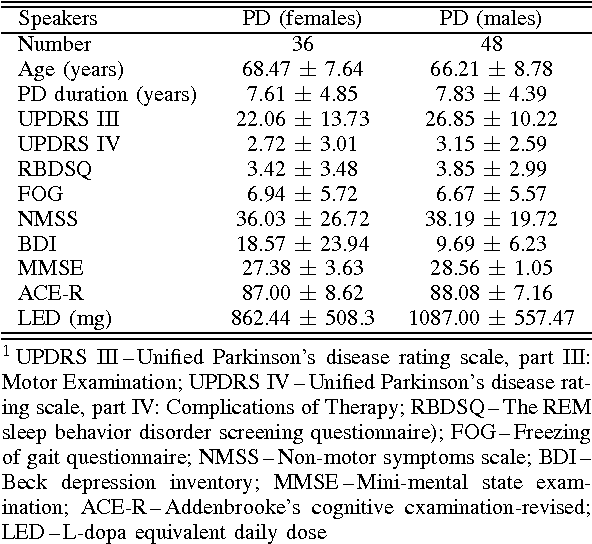
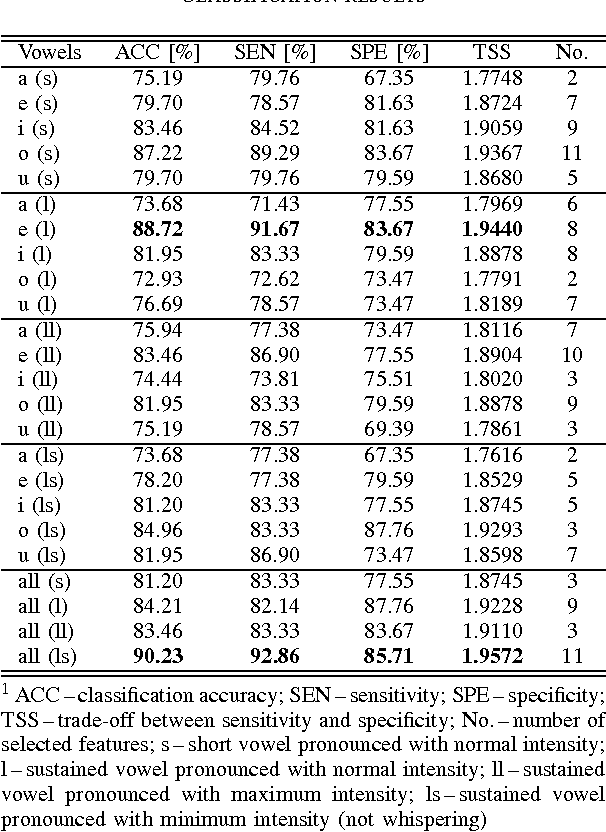
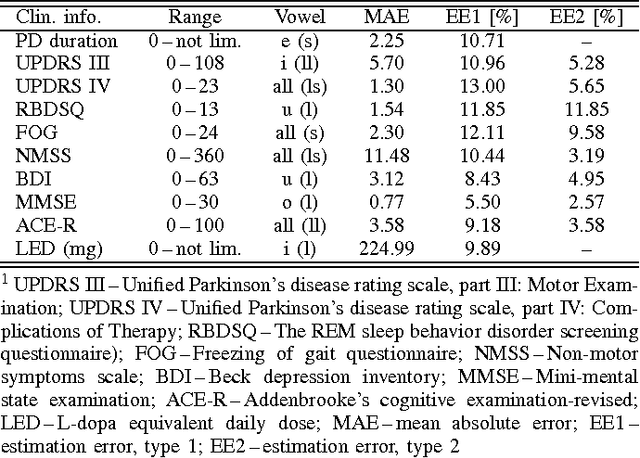
This paper deals with a complex acoustic analysis of phonation in patients with Parkinson's disease (PD) with a special focus on estimation of disease progress that is described by 7 different clinical scales ,e. g. Unified Parkinson's disease rating scale or Beck depression inventory. The analysis is based on parametrization of 5 Czech vowels pronounced by 84 PD patients. Using classification and regression trees we estimated all clinical scores with maximal error lower or equal to 13 %. Best estimation was observed in the case of Mini-mental state examination (MAE = 0.77, estimation error 5.50 %. Finally, we proposed a binary classification based on random forests that is able to identify Parkinson's disease with sensitivity SEN = 92.86 % (SPE = 85.71 %). The parametrization process was based on extraction of 107 speech features quantifying different clinical signs of hypokinetic dysarthria present in PD.
* 8 pages published in the 4th IEEE IWOBI 2015, pp. 115-122, 10-12 June, 2015 Donostia-San Sebastian. ISBN: 978-84-606-8733-7
Towards Robust Voice Pathology Detection
Jul 13, 2019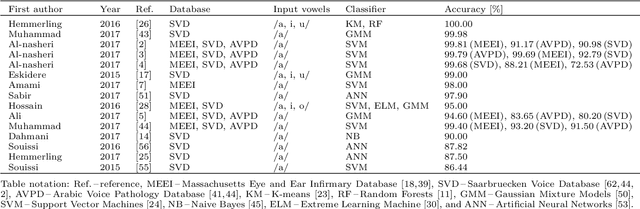
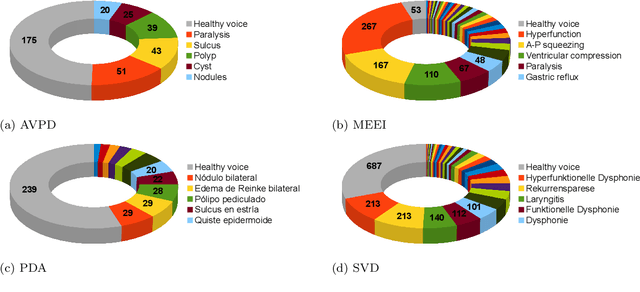
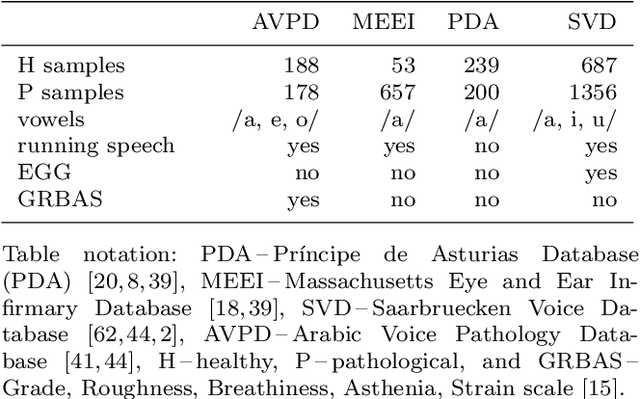
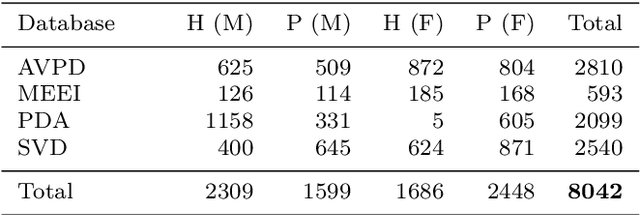
Automatic objective non-invasive detection of pathological voice based on computerized analysis of acoustic signals can play an important role in early diagnosis, progression tracking and even effective treatment of pathological voices. In search towards such a robust voice pathology detection system we investigated 3 distinct classifiers within supervised learning and anomaly detection paradigms. We conducted a set of experiments using a variety of input data such as raw waveforms, spectrograms, mel-frequency cepstral coefficients (MFCC) and conventional acoustic (dysphonic) features (AF). In comparison with previously published works, this article is the first to utilize combination of 4 different databases comprising normophonic and pathological recordings of sustained phonation of the vowel /a/ unrestricted to a subset of vocal pathologies. Furthermore, to our best knowledge, this article is the first to explore gradient boosted trees and deep learning for this application. The following best classification performances measured by F1 score on dedicated test set were achieved: XGBoost (0.733) using AF and MFCC, DenseNet (0.621) using MFCC, and Isolation Forest (0.610) using AF. Even though these results are of exploratory character, conducted experiments do show promising potential of gradient boosting and deep learning methods to robustly detect voice pathologies.
* 11 pages, 1 figure, 10 tables. Keywords: Voice pathology detection, deep learning, gradient boosting, anomaly detection
Voice Pathology Detection Using Deep Learning: a Preliminary Study
Jul 12, 2019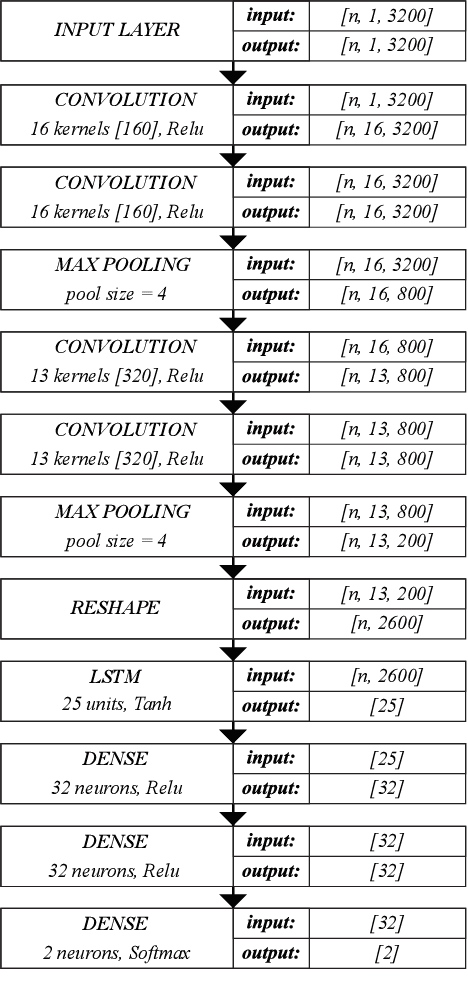


This paper describes a preliminary investigation of Voice Pathology Detection using Deep Neural Networks (DNN). We used voice recordings of sustained vowel /a/ produced at normal pitch from German corpus Saarbruecken Voice Database (SVD). This corpus contains voice recordings and electroglottograph signals of more than 2 000 speakers. The idea behind this experiment is the use of convolutional layers in combination with recurrent Long-Short-Term-Memory (LSTM) layers on raw audio signal. Each recording was split into 64 ms Hamming windowed segments with 30 ms overlap. Our trained model achieved 71.36% accuracy with 65.04% sensitivity and 77.67% specificity on 206 validation files and 68.08% accuracy with 66.75% sensitivity and 77.89% specificity on 874 testing files. This is a promising result in favor of this approach because it is comparable to similar previously published experiment that used different methodology. Further investigation is needed to achieve the state-of-the-art results.
* 4 pages, 1 figure, 5 tables
Machines listening to music: the role of signal representations in learning from music
Mar 27, 2019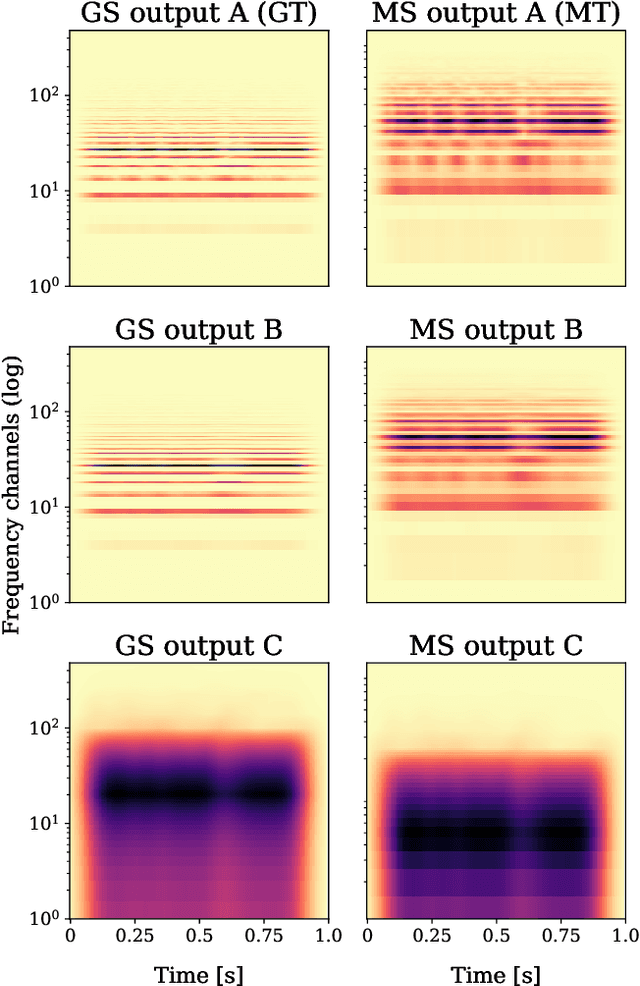
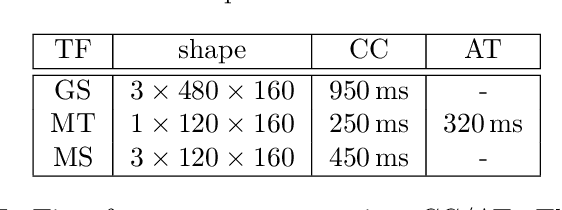
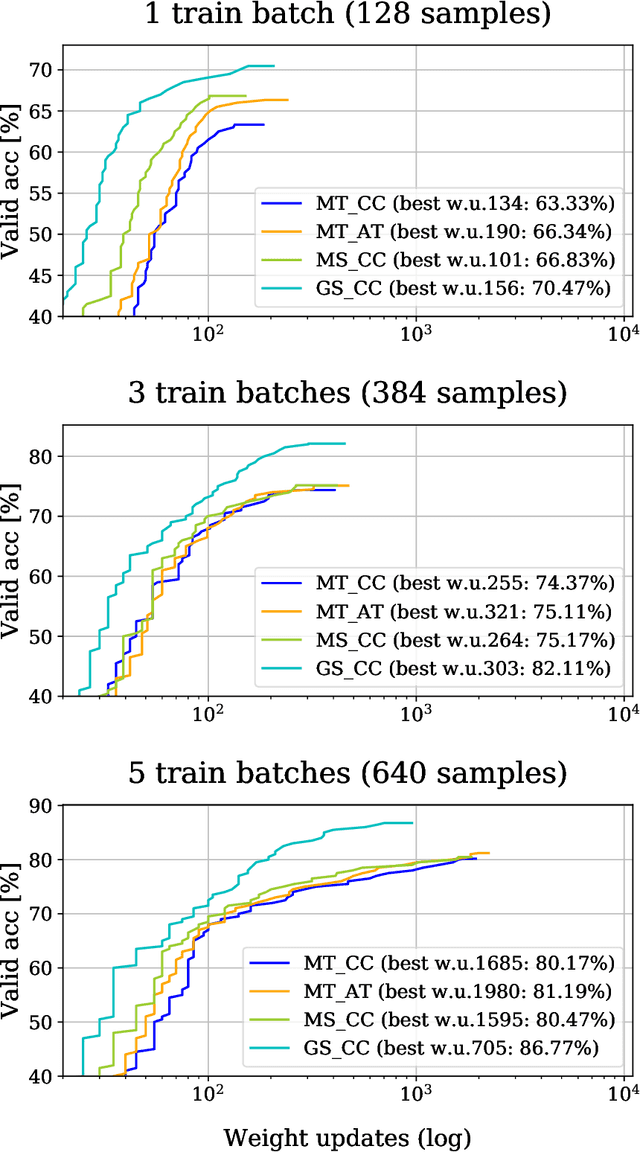
Recent, extremely successful methods in deep learning, such as convolutional neural networks (CNNs) have originated in machine learning for images. When applied to music signals and related music information retrieval (MIR) problems, researchers often apply standard FFT-based signal processing methods in order to create an image from the raw audio data. The impact of this basic signal processing step on the final outcome of the MIR task has not been widely studied and is not well understood. In this contribution, we study Gabor Scattering and a new representation, namely Mel Scattering. Furthermore, we suggest an alternative enhancement of the loss function that uses transformed representations of the output data to incorporate additional available information. We show how applying various different signal analysis methods can lead to useful invariances and improve the overall performance in MIR problems by reducing the amount of necessary training data or the necessity of augmentation.