 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePotential Contrast: Properties, Equivalences, and Generalization to Multiple Classes
May 02, 2025Potential contrast is typically used as an image quality measure and quantifies the maximal possible contrast between samples from two classes of pixels in an image after an arbitrary grayscale transformation. It has been valuable in cultural heritage applications, identifying and visualizing relevant information in multispectral images while requiring a small number of pixels to be manually sampled. In this work, we introduce a normalized version of potential contrast that removes dependence on image format and also prove equalities that enable generalization to more than two classes and to continuous settings. Finally, we exemplify the utility of multi-class normalized potential contrast through an application to a medieval music manuscript with visible bleedthrough from the back page. We share our implementations, based on both original algorithms and our new equalities, including generalization to multiple classes, at https://github.com/wallacepeaslee/Multiple-Class-Normalized-Potential-Contrast.
Parameter choices in HaarPSI for IQA with medical images
Oct 31, 2024When developing machine learning models, image quality assessment (IQA) measures are a crucial component for evaluation. However, commonly used IQA measures have been primarily developed and optimized for natural images. In many specialized settings, such as medical images, this poses an often-overlooked problem regarding suitability. In previous studies, the IQA measure HaarPSI showed promising behavior for natural and medical images. HaarPSI is based on Haar wavelet representations and the framework allows optimization of two parameters. So far, these parameters have been aligned for natural images. Here, we optimize these parameters for two annotated medical data sets, a photoacoustic and a chest X-Ray data set. We observe that they are more sensitive to the parameter choices than the employed natural images, and on the other hand both medical data sets lead to similar parameter values when optimized. We denote the optimized setting, which improves the performance for the medical images notably, by HaarPSI$_{MED}$. The results suggest that adapting common IQA measures within their frameworks for medical images can provide a valuable, generalizable addition to the employment of more specific task-based measures.
Can Rule-Based Insights Enhance LLMs for Radiology Report Classification? Introducing the RadPrompt Methodology
Aug 07, 2024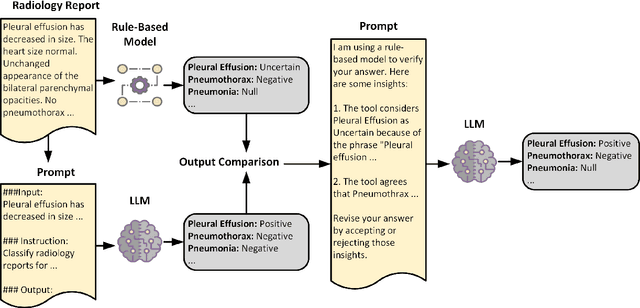
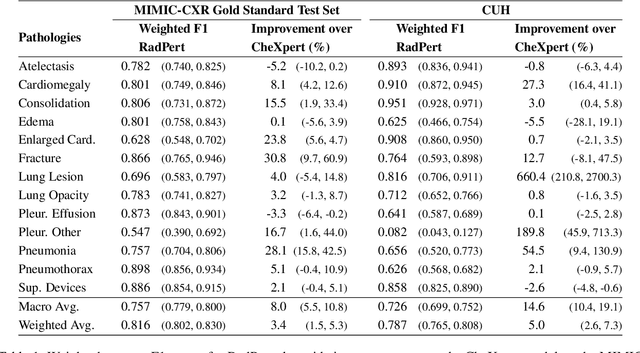
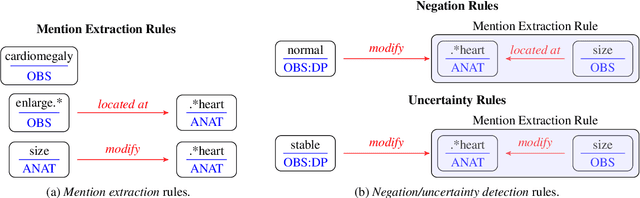
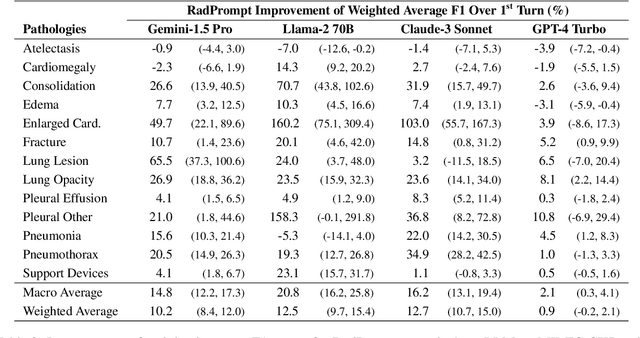
Developing imaging models capable of detecting pathologies from chest X-rays can be cost and time-prohibitive for large datasets as it requires supervision to attain state-of-the-art performance. Instead, labels extracted from radiology reports may serve as distant supervision since these are routinely generated as part of clinical practice. Despite their widespread use, current rule-based methods for label extraction rely on extensive rule sets that are limited in their robustness to syntactic variability. To alleviate these limitations, we introduce RadPert, a rule-based system that integrates an uncertainty-aware information schema with a streamlined set of rules, enhancing performance. Additionally, we have developed RadPrompt, a multi-turn prompting strategy that leverages RadPert to bolster the zero-shot predictive capabilities of large language models, achieving a statistically significant improvement in weighted average F1 score over GPT-4 Turbo. Most notably, RadPrompt surpasses both its underlying models, showcasing the synergistic potential of LLMs with rule-based models. We have evaluated our methods on two English Corpora: the MIMIC-CXR gold-standard test set and a gold-standard dataset collected from the Cambridge University Hospitals.
A study on the adequacy of common IQA measures for medical images
May 29, 2024
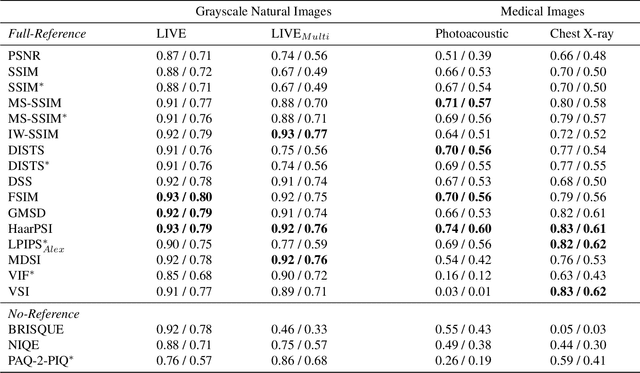
Image quality assessment (IQA) is standard practice in the development stage of novel machine learning algorithms that operate on images. The most commonly used IQA measures have been developed and tested for natural images, but not in the medical setting. Reported inconsistencies arising in medical images are not surprising, as they have different properties than natural images. In this study, we test the applicability of common IQA measures for medical image data by comparing their assessment to manually rated chest X-ray (5 experts) and photoacoustic image data (1 expert). Moreover, we include supplementary studies on grayscale natural images and accelerated brain MRI data. The results of all experiments show a similar outcome in line with previous findings for medical imaging: PSNR and SSIM in the default setting are in the lower range of the result list and HaarPSI outperforms the other tested measures in the overall performance. Also among the top performers in our medical experiments are the full reference measures DISTS, FSIM, LPIPS and MS-SSIM. Generally, the results on natural images yield considerably higher correlations, suggesting that the additional employment of tailored IQA measures for medical imaging algorithms is needed.
A study of why we need to reassess full reference image quality assessment with medical images
May 29, 2024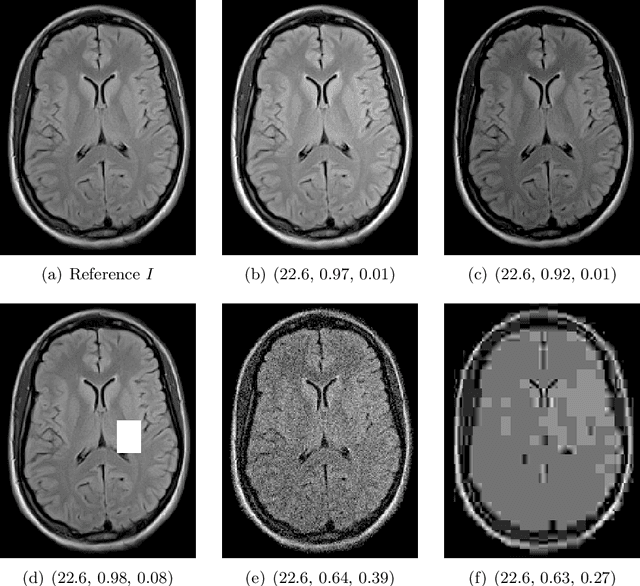
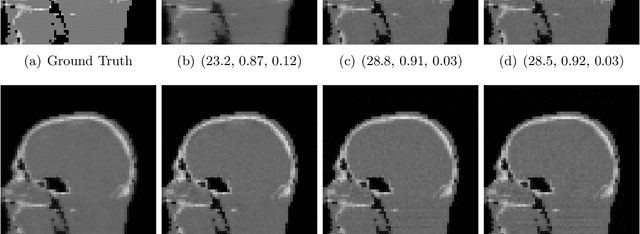
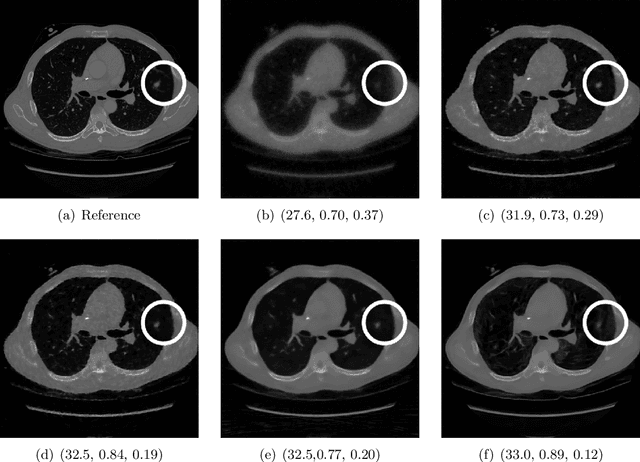

Image quality assessment (IQA) is not just indispensable in clinical practice to ensure high standards, but also in the development stage of novel algorithms that operate on medical images with reference data. This paper provides a structured and comprehensive collection of examples where the two most common full reference (FR) image quality measures prove to be unsuitable for the assessment of novel algorithms using different kinds of medical images, including real-world MRI, CT, OCT, X-Ray, digital pathology and photoacoustic imaging data. In particular, the FR-IQA measures PSNR and SSIM are known and tested for working successfully in many natural imaging tasks, but discrepancies in medical scenarios have been noted in the literature. Inconsistencies arising in medical images are not surprising, as they have very different properties than natural images which have not been targeted nor tested in the development of the mentioned measures, and therefore might imply wrong judgement of novel methods for medical images. Therefore, improvement is urgently needed in particular in this era of AI to increase explainability, reproducibility and generalizability in machine learning for medical imaging and beyond. On top of the pitfalls we will provide ideas for future research as well as suggesting guidelines for the usage of FR-IQA measures applied to medical images.
visClust: A visual clustering algorithm based on orthogonal projections
Nov 07, 2022



We present a novel clustering algorithm, visClust, that is based on lower dimensional data representations and visual interpretation. Thereto, we design a transformation that allows the data to be represented by a binary integer array enabling the further use of image processing methods to select a partition. Qualitative and quantitative analyses show that the algorithm obtains high accuracy (measured with an adjusted one-sided Rand-Index) and requires low runtime and RAM. We compare the results to 6 state-of-the-art algorithms, confirming the quality of visClust by outperforming in most experiments. Moreover, the algorithm asks for just one obligatory input parameter while allowing optimization via optional parameters. The code is made available on GitHub.
Blood vessel segmentation in en-face OCTA images: a frequency based method
Sep 13, 2021
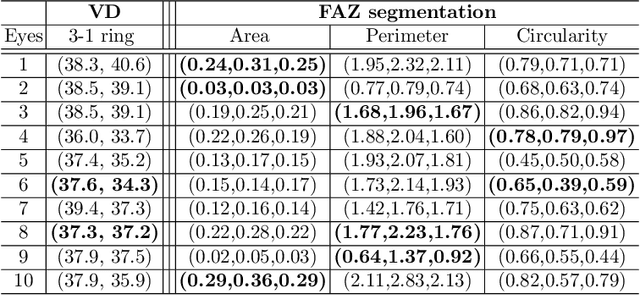
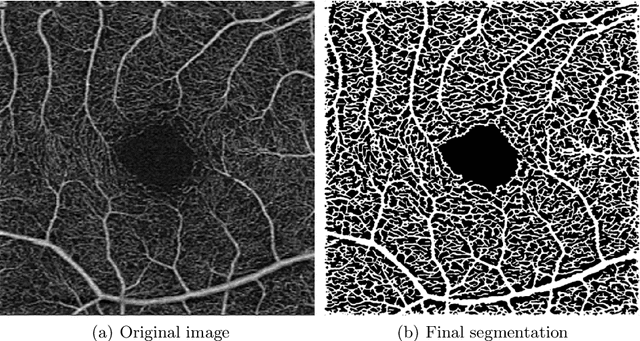
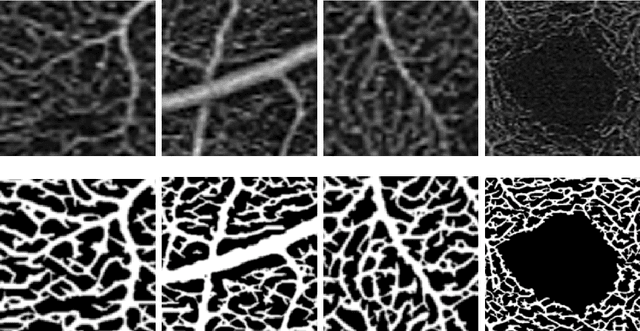
Optical coherence tomography angiography (OCTA) is a novel noninvasive imaging modality for visualization of retinal blood flow in the human retina. Using specific OCTA imaging biomarkers for the identification of pathologies, automated image segmentations of the blood vessels can improve subsequent analysis and diagnosis. We present a novel method for the vessel identification based on frequency representations of the image, in particular, using so-called Gabor filter banks. The algorithm is evaluated on an OCTA image data set from $10$ eyes acquired by a Cirrus HD-OCT device. The segmentation outcomes received very good qualitative visual evaluation feedback and coincide well with device-specific values concerning vessel density. Concerning locality our segmentations are even more reliable and accurate. Therefore, we suggest the computation of adaptive local vessel density maps that allow straightforward analysis of retinal blood flow.
An amplified-target loss approach for photoreceptor layer segmentation in pathological OCT scans
Aug 02, 2019
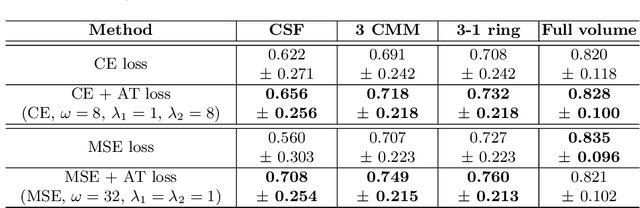


Segmenting anatomical structures such as the photoreceptor layer in retinal optical coherence tomography (OCT) scans is challenging in pathological scenarios. Supervised deep learning models trained with standard loss functions are usually able to characterize only the most common disease appeareance from a training set, resulting in suboptimal performance and poor generalization when dealing with unseen lesions. In this paper we propose to overcome this limitation by means of an augmented target loss function framework. We introduce a novel amplified-target loss that explicitly penalizes errors within the central area of the input images, based on the observation that most of the challenging disease appeareance is usually located in this area. We experimentally validated our approach using a data set with OCT scans of patients with macular diseases. We observe increased performance compared to the models that use only the standard losses. Our proposed loss function strongly supports the segmentation model to better distinguish photoreceptors in highly pathological scenarios.
Machines listening to music: the role of signal representations in learning from music
Mar 27, 2019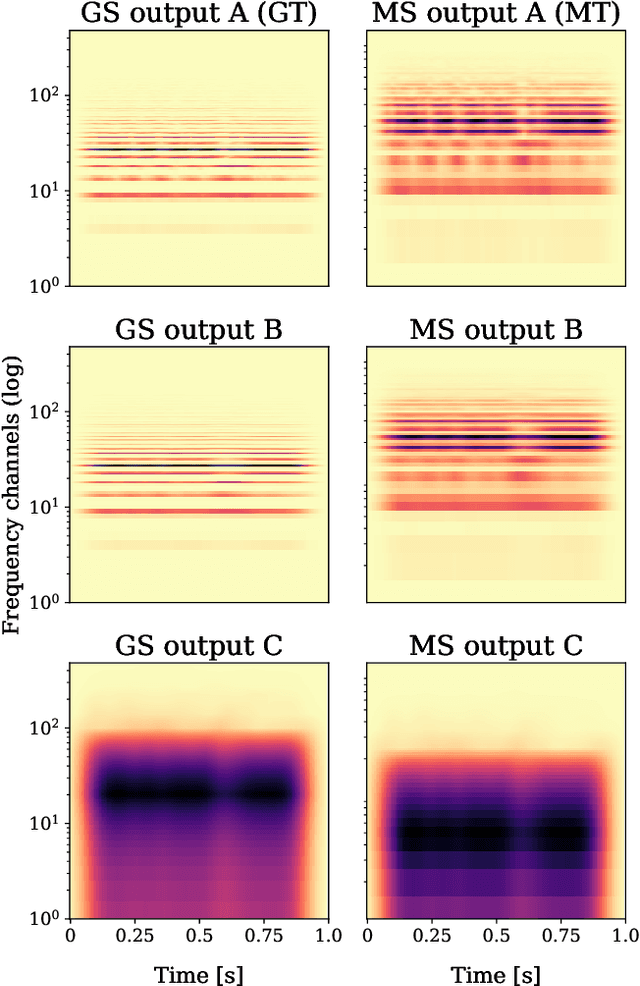
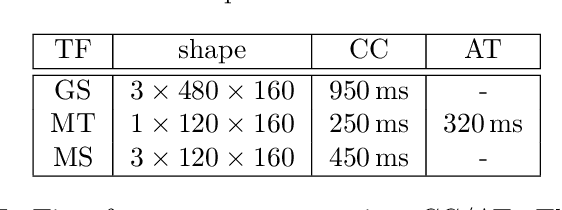
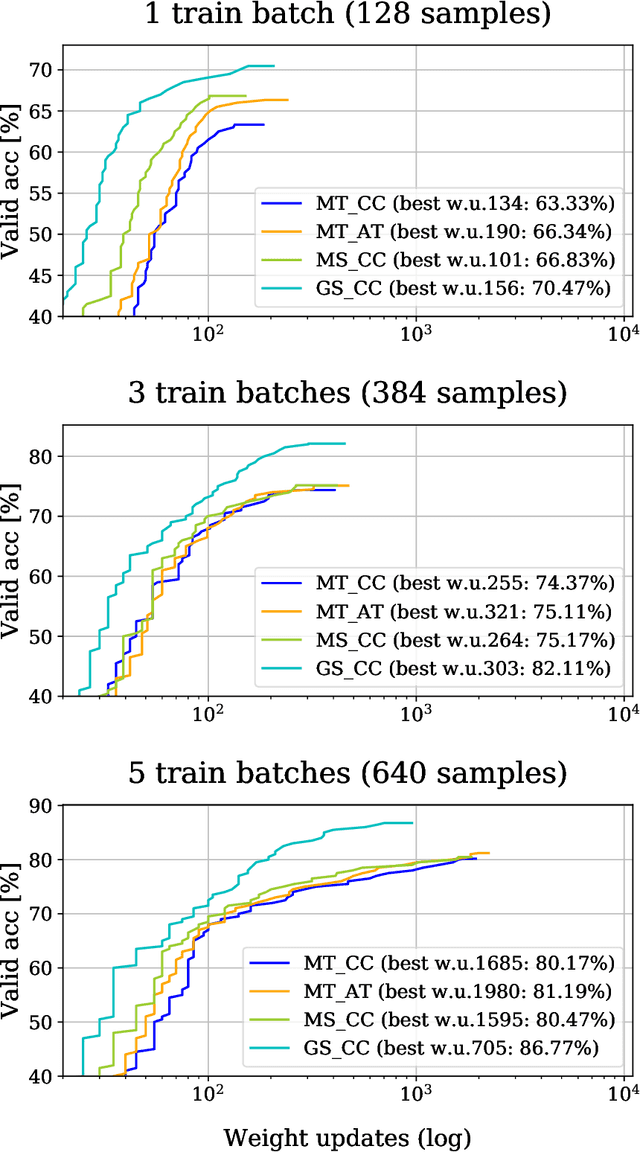
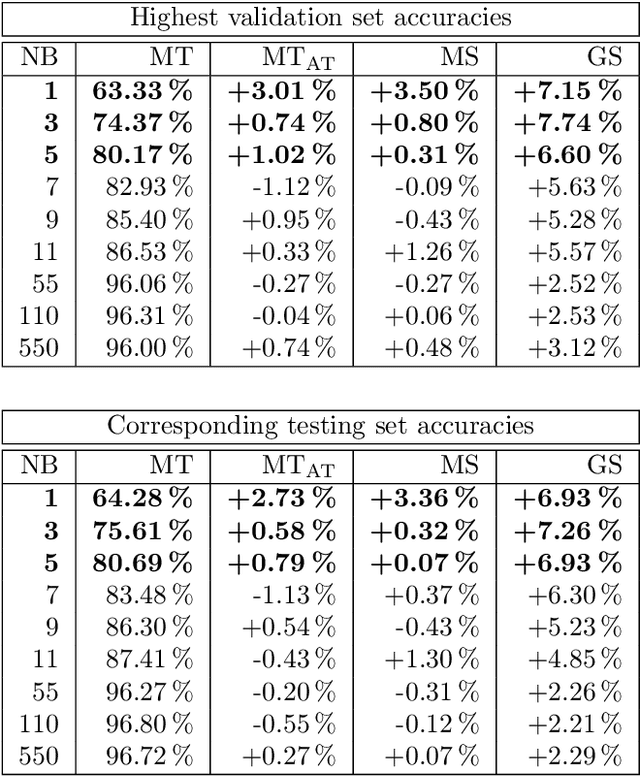
Recent, extremely successful methods in deep learning, such as convolutional neural networks (CNNs) have originated in machine learning for images. When applied to music signals and related music information retrieval (MIR) problems, researchers often apply standard FFT-based signal processing methods in order to create an image from the raw audio data. The impact of this basic signal processing step on the final outcome of the MIR task has not been widely studied and is not well understood. In this contribution, we study Gabor Scattering and a new representation, namely Mel Scattering. Furthermore, we suggest an alternative enhancement of the loss function that uses transformed representations of the output data to incorporate additional available information. We show how applying various different signal analysis methods can lead to useful invariances and improve the overall performance in MIR problems by reducing the amount of necessary training data or the necessity of augmentation.
On orthogonal projections for dimension reduction and applications in variational loss functions for learning problems
Jan 22, 2019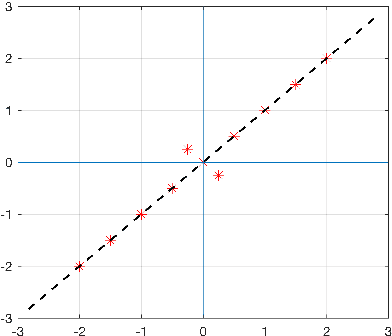
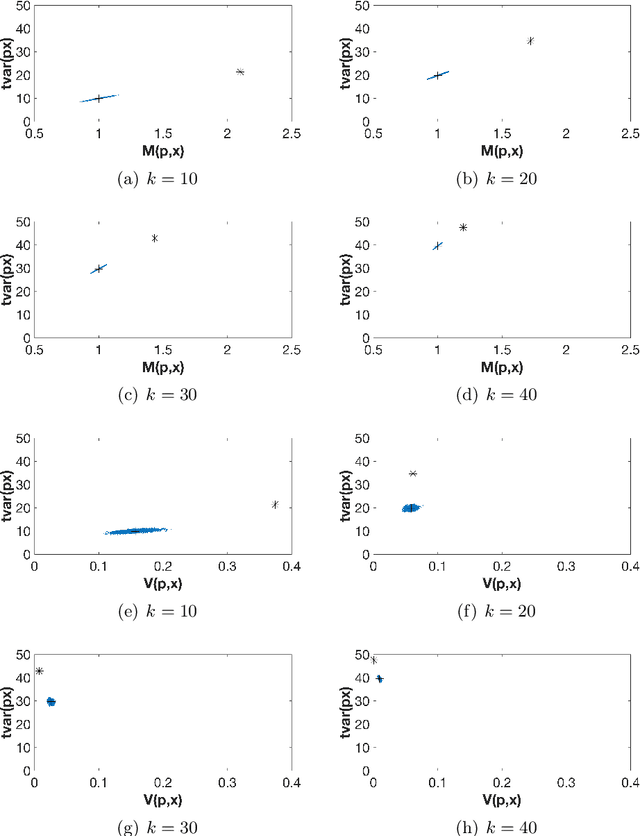
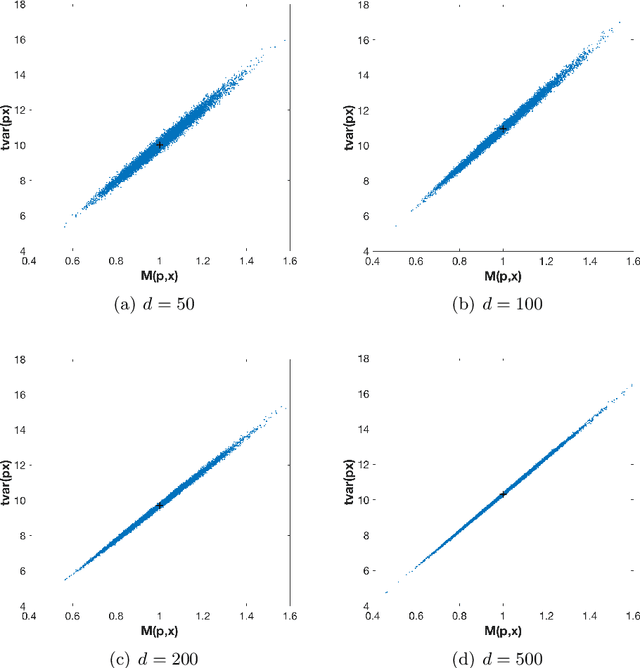
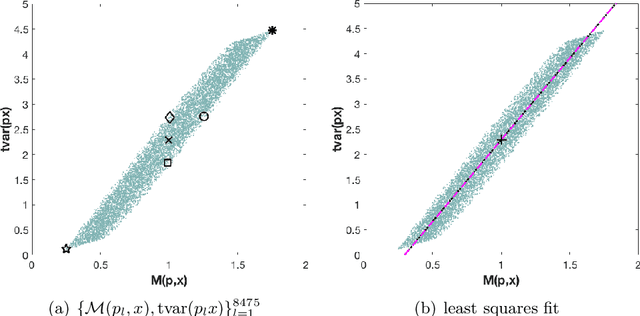
The use of orthogonal projections on high-dimensional input and target data in learning frameworks is studied. First, we investigate the relations between two standard objectives in dimension reduction, maximizing variance and preservation of pairwise relative distances. The derivation of their asymptotic correlation and numerical experiments tell that a projection usually cannot satisfy both objectives. In a standard classification problem we determine projections on the input data that balance them and compare subsequent results. Next, we extend our application of orthogonal projections to deep learning frameworks. We introduce new variational loss functions that enable integration of additional information via transformations and projections of the target data. In two supervised learning problems, clinical image segmentation and music information classification, the application of the proposed loss functions increase the accuracy.