 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachines listening to music: the role of signal representations in learning from music
Mar 27, 2019
Recent, extremely successful methods in deep learning, such as convolutional neural networks (CNNs) have originated in machine learning for images. When applied to music signals and related music information retrieval (MIR) problems, researchers often apply standard FFT-based signal processing methods in order to create an image from the raw audio data. The impact of this basic signal processing step on the final outcome of the MIR task has not been widely studied and is not well understood. In this contribution, we study Gabor Scattering and a new representation, namely Mel Scattering. Furthermore, we suggest an alternative enhancement of the loss function that uses transformed representations of the output data to incorporate additional available information. We show how applying various different signal analysis methods can lead to useful invariances and improve the overall performance in MIR problems by reducing the amount of necessary training data or the necessity of augmentation.
Basic Filters for Convolutional Neural Networks Applied to Music: Training or Design?
Sep 19, 2018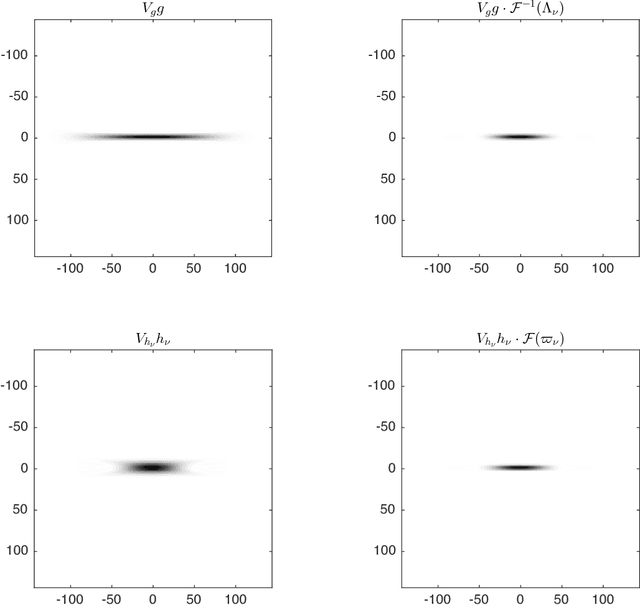
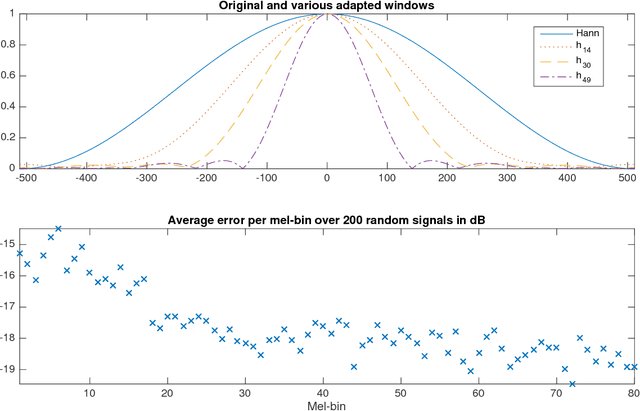
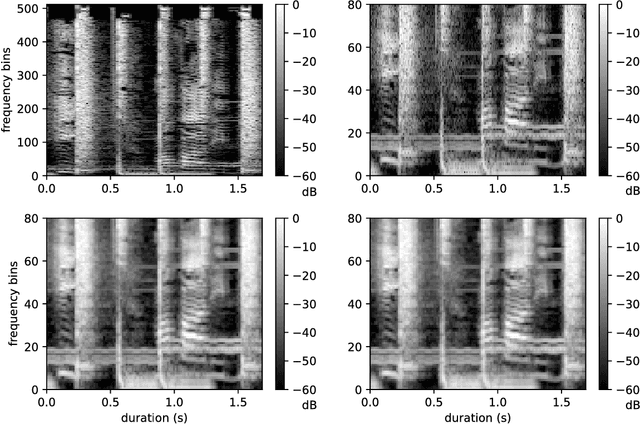
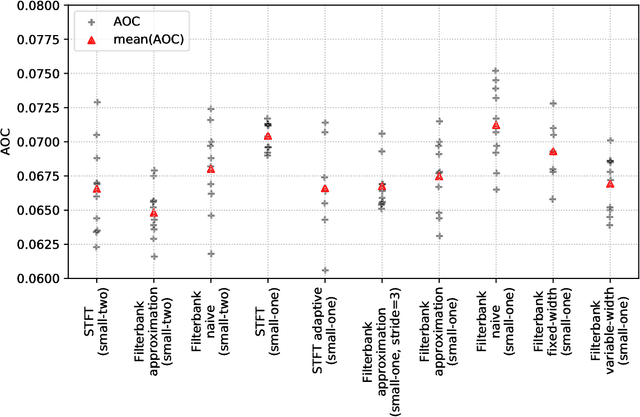
When convolutional neural networks are used to tackle learning problems based on music or, more generally, time series data, raw one-dimensional data are commonly pre-processed to obtain spectrogram or mel-spectrogram coefficients, which are then used as input to the actual neural network. In this contribution, we investigate, both theoretically and experimentally, the influence of this pre-processing step on the network's performance and pose the question, whether replacing it by applying adaptive or learned filters directly to the raw data, can improve learning success. The theoretical results show that approximately reproducing mel-spectrogram coefficients by applying adaptive filters and subsequent time-averaging is in principle possible. We also conducted extensive experimental work on the task of singing voice detection in music. The results of these experiments show that for classification based on Convolutional Neural Networks the features obtained from adaptive filter banks followed by time-averaging perform better than the canonical Fourier-transform-based mel-spectrogram coefficients. Alternative adaptive approaches with center frequencies or time-averaging lengths learned from training data perform equally well.
Gabor frames and deep scattering networks in audio processing
Jun 27, 2017

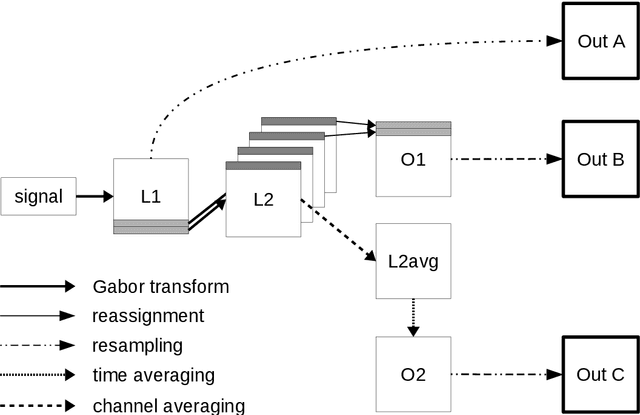
In this paper a feature extractor based on Gabor frames and Mallat's scattering transform, called Gabor scattering, is introduced. This feature extractor is applied to a simple signal model for audio signals, i.e. a class of tones consisting of fundamental frequency and its multiples and an according envelope. Within different layers, different invariances to certain signal features occur. In this paper we give a mathematical explanation for the first and the second layer which are illustrated by numerical examples. Deformation stability of this feature extractor will be shown by using a decoupling technique, previously suggested for the scattering transform of Cartoon functions. Here it is used to see if the feature extractor is robust to changes in spectral shape and frequency modulation.