 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValidity in Music Information Research Experiments
Jan 04, 2023



Validity is the truth of an inference made from evidence, such as data collected in an experiment, and is central to working scientifically. Given the maturity of the domain of music information research (MIR), validity in our opinion should be discussed and considered much more than it has been so far. Considering validity in one's work can improve its scientific and engineering value. Puzzling MIR phenomena like adversarial attacks and performance glass ceilings become less mysterious through the lens of validity. In this article, we review the subject of validity in general, considering the four major types of validity from a key reference: Shadish et al. 2002. We ground our discussion of these types with a prototypical MIR experiment: music classification using machine learning. Through this MIR experimentalists can be guided to make valid inferences from data collected from their experiments.
Concept-Based Techniques for "Musicologist-friendly" Explanations in a Deep Music Classifier
Aug 29, 2022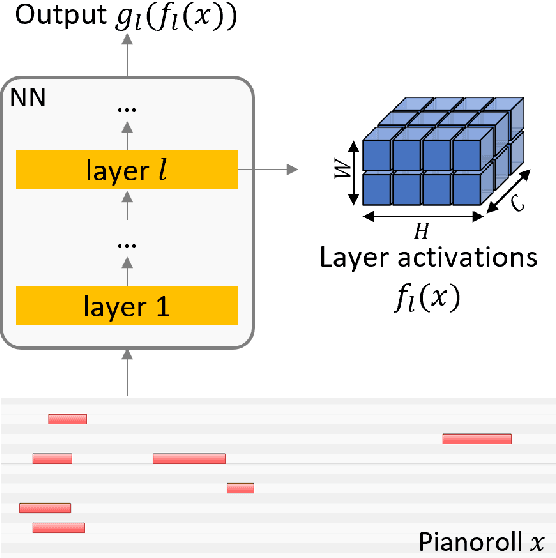

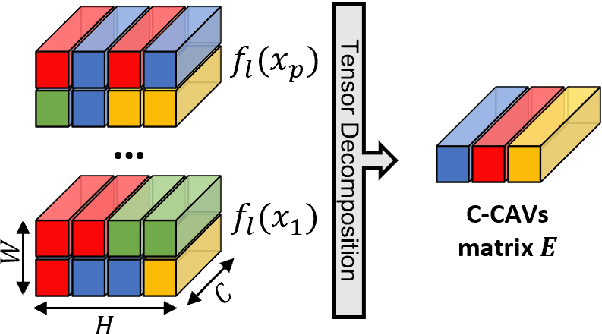
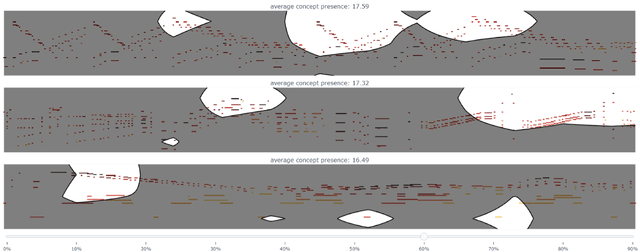
Current approaches for explaining deep learning systems applied to musical data provide results in a low-level feature space, e.g., by highlighting potentially relevant time-frequency bins in a spectrogram or time-pitch bins in a piano roll. This can be difficult to understand, particularly for musicologists without technical knowledge. To address this issue, we focus on more human-friendly explanations based on high-level musical concepts. Our research targets trained systems (post-hoc explanations) and explores two approaches: a supervised one, where the user can define a musical concept and test if it is relevant to the system; and an unsupervised one, where musical excerpts containing relevant concepts are automatically selected and given to the user for interpretation. We demonstrate both techniques on an existing symbolic composer classification system, showcase their potential, and highlight their intrinsic limitations.
Defending a Music Recommender Against Hubness-Based Adversarial Attacks
May 24, 2022
Adversarial attacks can drastically degrade performance of recommenders and other machine learning systems, resulting in an increased demand for defence mechanisms. We present a new line of defence against attacks which exploit a vulnerability of recommenders that operate in high dimensional data spaces (the so-called hubness problem). We use a global data scaling method, namely Mutual Proximity (MP), to defend a real-world music recommender which previously was susceptible to attacks that inflated the number of times a particular song was recommended. We find that using MP as a defence greatly increases robustness of the recommender against a range of attacks, with success rates of attacks around 44% (before defence) dropping to less than 6% (after defence). Additionally, adversarial examples still able to fool the defended system do so at the price of noticeably lower audio quality as shown by a decreased average SNR.
On the Veracity of Local, Model-agnostic Explanations in Audio Classification: Targeted Investigations with Adversarial Examples
Jul 19, 2021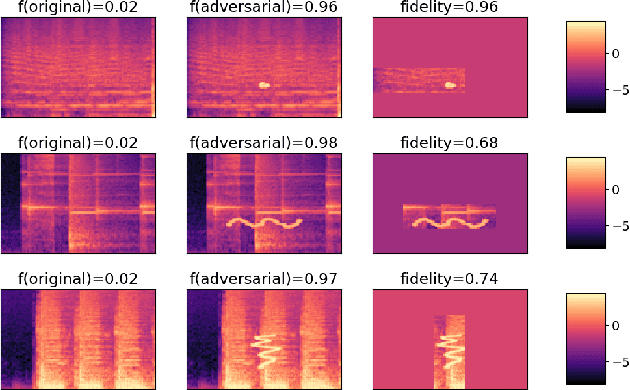
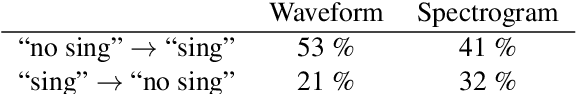
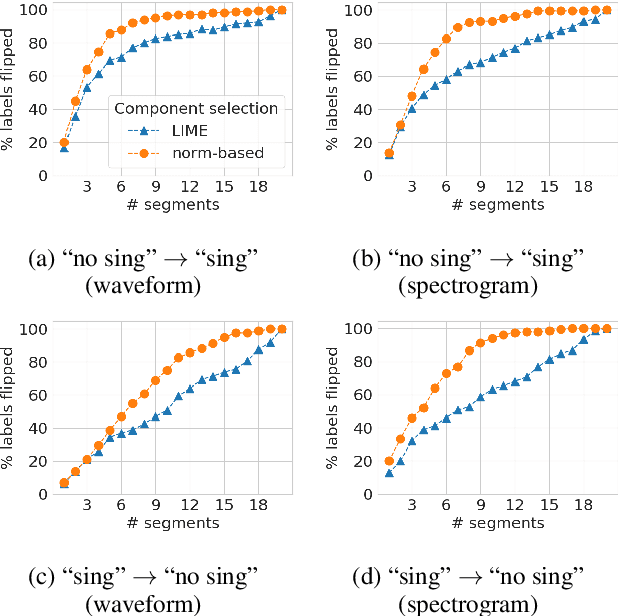
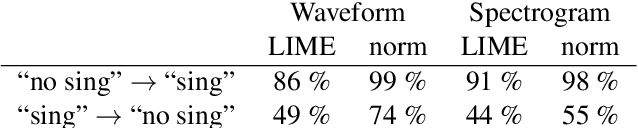
Local explanation methods such as LIME have become popular in MIR as tools for generating post-hoc, model-agnostic explanations of a model's classification decisions. The basic idea is to identify a small set of human-understandable features of the classified example that are most influential on the classifier's prediction. These are then presented as an explanation. Evaluation of such explanations in publications often resorts to accepting what matches the expectation of a human without actually being able to verify if what the explanation shows is what really caused the model's prediction. This paper reports on targeted investigations where we try to get more insight into the actual veracity of LIME's explanations in an audio classification task. We deliberately design adversarial examples for the classifier, in a way that gives us knowledge about which parts of the input are potentially responsible for the model's (wrong) prediction. Asking LIME to explain the predictions for these adversaries permits us to study whether local explanations do indeed detect these regions of interest. We also look at whether LIME is more successful in finding perturbations that are more prominent and easily noticeable for a human. Our results suggest that LIME does not necessarily manage to identify the most relevant input features and hence it remains unclear whether explanations are useful or even misleading.
The Impact of Label Noise on a Music Tagger
Aug 14, 2020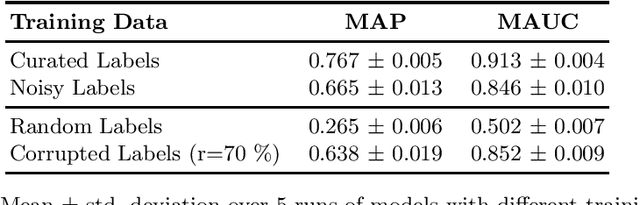
We explore how much can be learned from noisy labels in audio music tagging. Our experiments show that carefully annotated labels result in highest figures of merit, but even high amounts of noisy labels contain enough information for successful learning. Artificial corruption of curated data allows us to quantize this contribution of noisy labels.
End-to-End Adversarial White Box Attacks on Music Instrument Classification
Jul 29, 2020
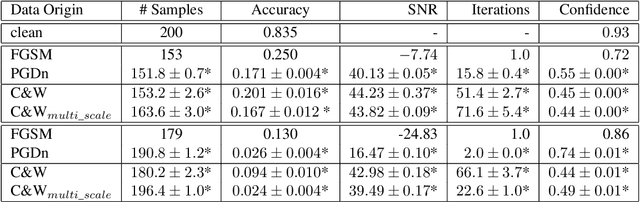

Small adversarial perturbations of input data are able to drastically change performance of machine learning systems, thereby challenging the validity of such systems. We present the very first end-to-end adversarial attacks on a music instrument classification system allowing to add perturbations directly to audio waveforms instead of spectrograms. Our attacks are able to reduce the accuracy close to a random baseline while at the same time keeping perturbations almost imperceptible and producing misclassifications to any desired instrument.
scikit-hubness: Hubness Reduction and Approximate Neighbor Search
Dec 02, 2019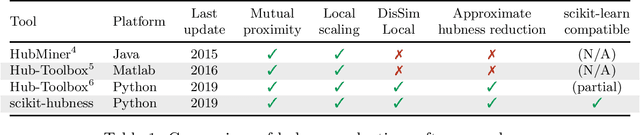
This paper introduces scikit-hubness, a Python package for efficient nearest neighbor search in high-dimensional spaces. Hubness is an aspect of the curse of dimensionality, and is known to impair various learning tasks, including classification, clustering, and visualization. scikit-hubness provides algorithms for hubness analysis ("Is my data affected by hubness?"), hubness reduction ("How can we improve neighbor retrieval in high dimensions?"), and approximate neighbor search ("Does it work for large data sets?"). It is integrated into the scikit-learn environment, enabling rapid adoption by Python-based machine learning researchers and practitioners. Users will find all functionality of the scikit-learn neighbors package, plus additional support for transparent hubness reduction and approximate nearest neighbor search. scikit-hubness is developed using several quality assessment tools and principles, such as PEP8 compliance, unit tests with high code coverage, continuous integration on all major platforms (Linux, MacOS, Windows), and additional checks by LGTM. The source code is available at https://github.com/VarIr/scikit-hubness under the BSD 3-clause license. Install from the Python package index with $ pip install scikit-hubness.
Basic Filters for Convolutional Neural Networks Applied to Music: Training or Design?
Sep 19, 2018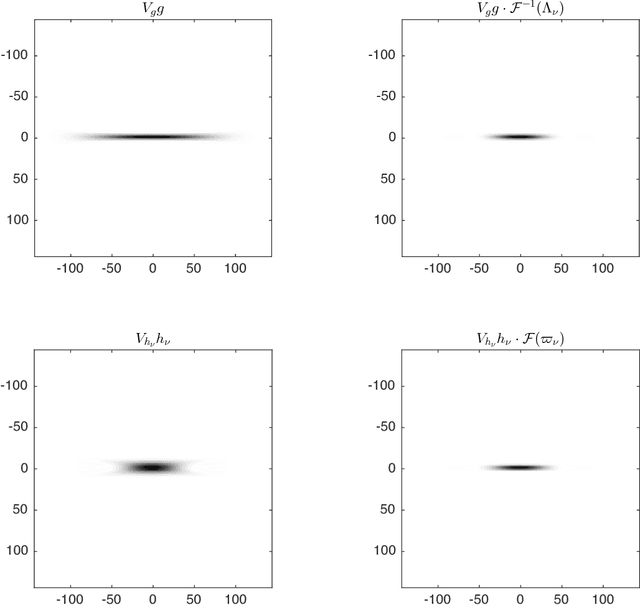
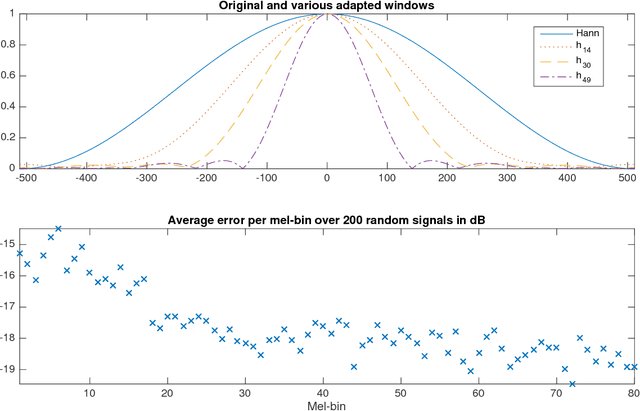
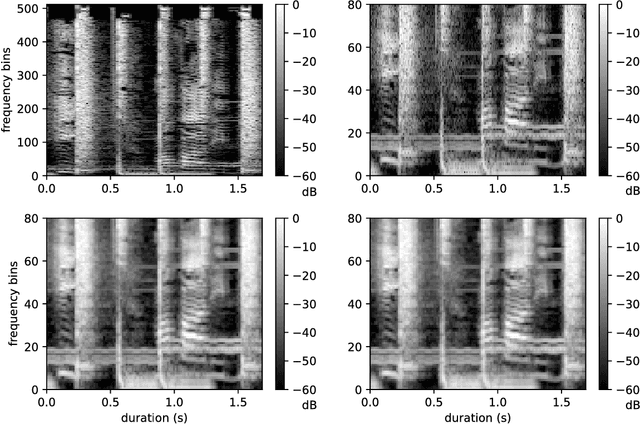
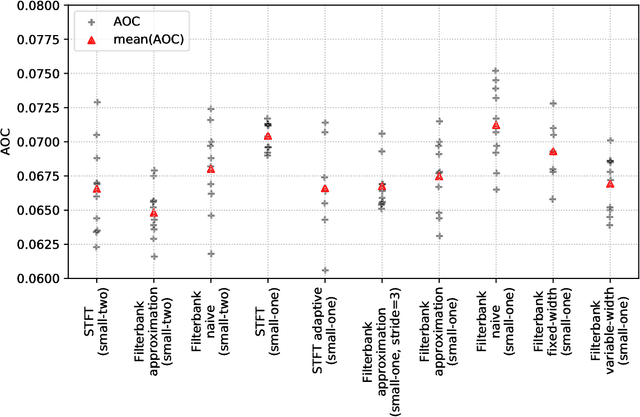
When convolutional neural networks are used to tackle learning problems based on music or, more generally, time series data, raw one-dimensional data are commonly pre-processed to obtain spectrogram or mel-spectrogram coefficients, which are then used as input to the actual neural network. In this contribution, we investigate, both theoretically and experimentally, the influence of this pre-processing step on the network's performance and pose the question, whether replacing it by applying adaptive or learned filters directly to the raw data, can improve learning success. The theoretical results show that approximately reproducing mel-spectrogram coefficients by applying adaptive filters and subsequent time-averaging is in principle possible. We also conducted extensive experimental work on the task of singing voice detection in music. The results of these experiments show that for classification based on Convolutional Neural Networks the features obtained from adaptive filter banks followed by time-averaging perform better than the canonical Fourier-transform-based mel-spectrogram coefficients. Alternative adaptive approaches with center frequencies or time-averaging lengths learned from training data perform equally well.