 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteer-by-prior Editing of Symbolic Music Loops
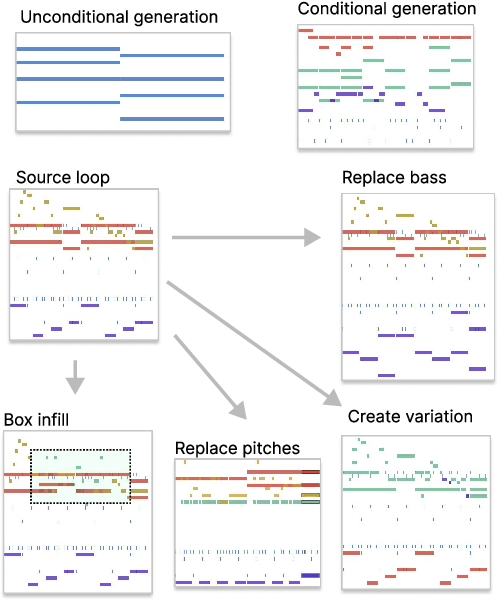
Aug 05, 2024With the goal of building a system capable of controllable symbolic music loop generation and editing, this paper explores a generalisation of Masked Language Modelling we call Superposed Language Modelling. Rather than input tokens being known or unknown, a Superposed Language Model takes priors over the sequence as input, enabling us to apply various constraints to the generation at inference time. After detailing our approach, we demonstrate our model across various editing tasks in the domain of multi-instrument MIDI loops. We end by highlighting some limitations of the approach and avenues for future work. We provides examples from the SLM across multiple generation and editing tasks at https://erl-j.github.io/slm-mml-demo/.
SYMPLEX: Controllable Symbolic Music Generation using Simplex Diffusion with Vocabulary Priors
May 21, 2024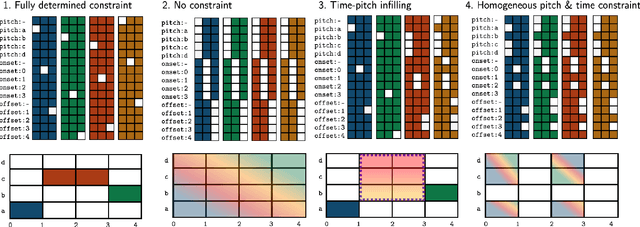
We present a new approach for fast and controllable generation of symbolic music based on the simplex diffusion, which is essentially a diffusion process operating on probabilities rather than the signal space. This objective has been applied in domains such as natural language processing but here we apply it to generating 4-bar multi-instrument music loops using an orderless representation. We show that our model can be steered with vocabulary priors, which affords a considerable level control over the music generation process, for instance, infilling in time and pitch and choice of instrumentation -- all without task-specific model adaptation or applying extrinsic control.
Retrieval Augmented Generation of Symbolic Music with LLMs
Nov 17, 2023



We explore the use of large language models (LLMs) for music generation using a retrieval system to select relevant examples. We find promising initial results for music generation in a dialogue with the user, especially considering the ease with which such a system can be implemented. The code is available online.
DDSP-based Neural Waveform Synthesis of Polyphonic Guitar Performance from String-wise MIDI Input
Sep 14, 2023We explore the use of neural synthesis for acoustic guitar from string-wise MIDI input. We propose four different systems and compare them with both objective metrics and subjective evaluation against natural audio and a sample-based baseline. We iteratively develop these four systems by making various considerations on the architecture and intermediate tasks, such as predicting pitch and loudness control features. We find that formulating the control feature prediction task as a classification task rather than a regression task yields better results. Furthermore, we find that our simplest proposed system, which directly predicts synthesis parameters from MIDI input performs the best out of the four proposed systems. Audio examples are available at https://erl-j.github.io/neural-guitar-web-supplement.
Exploring Softly Masked Language Modelling for Controllable Symbolic Music Generation
May 11, 2023This document presents some early explorations of applying Softly Masked Language Modelling (SMLM) to symbolic music generation. SMLM can be seen as a generalisation of masked language modelling (MLM), where instead of each element of the input set being either known or unknown, each element can be known, unknown or partly known. We demonstrate some results of applying SMLM to constrained symbolic music generation using a transformer encoder architecture. Several audio examples are available at https://erl-j.github.io/smlm-web-supplement/
Validity in Music Information Research Experiments
Jan 04, 2023Validity is the truth of an inference made from evidence, such as data collected in an experiment, and is central to working scientifically. Given the maturity of the domain of music information research (MIR), validity in our opinion should be discussed and considered much more than it has been so far. Considering validity in one's work can improve its scientific and engineering value. Puzzling MIR phenomena like adversarial attacks and performance glass ceilings become less mysterious through the lens of validity. In this article, we review the subject of validity in general, considering the four major types of validity from a key reference: Shadish et al. 2002. We ground our discussion of these types with a prototypical MIR experiment: music classification using machine learning. Through this MIR experimentalists can be guided to make valid inferences from data collected from their experiments.
Audio Latent Space Cartography
Dec 07, 2022
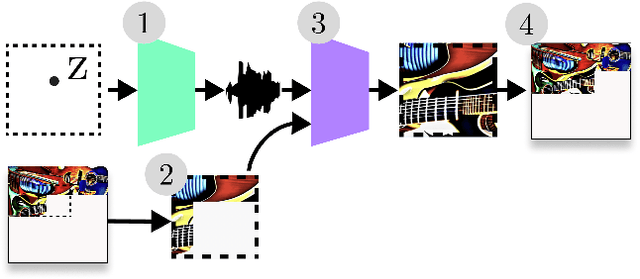


We explore the generation of visualisations of audio latent spaces using an audio-to-image generation pipeline. We believe this can help with the interpretability of audio latent spaces. We demonstrate a variety of results on the NSynth dataset. A web demo is available.
TimbreCLIP: Connecting Timbre to Text and Images
Nov 21, 2022


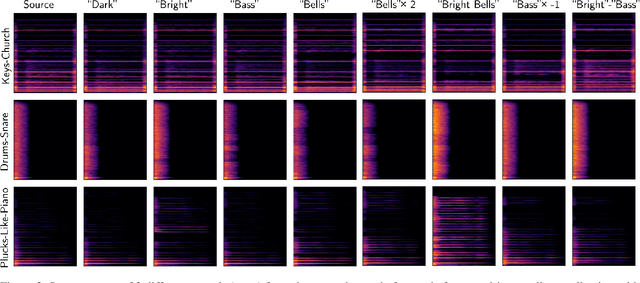
We present work in progress on TimbreCLIP, an audio-text cross modal embedding trained on single instrument notes. We evaluate the models with a cross-modal retrieval task on synth patches. Finally, we demonstrate the application of TimbreCLIP on two tasks: text-driven audio equalization and timbre to image generation.