 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Augmented Generation of Symbolic Music with LLMs
Nov 17, 2023



We explore the use of large language models (LLMs) for music generation using a retrieval system to select relevant examples. We find promising initial results for music generation in a dialogue with the user, especially considering the ease with which such a system can be implemented. The code is available online.
Polyphonic pitch detection with convolutional recurrent neural networks
Feb 04, 2022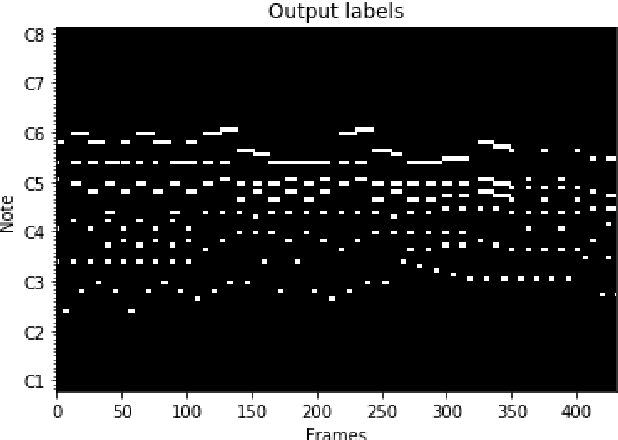

Recent directions in automatic speech recognition (ASR) research have shown that applying deep learning models from image recognition challenges in computer vision is beneficial. As automatic music transcription (AMT) is superficially similar to ASR, in the sense that methods often rely on transforming spectrograms to symbolic sequences of events (e.g. words or notes), deep learning should benefit AMT as well. In this work, we outline an online polyphonic pitch detection system that streams audio to MIDI by ConvLSTMs. Our system achieves state-of-the-art results on the 2007 MIREX multi-F0 development set, with an F-measure of 83\% on the bassoon, clarinet, flute, horn and oboe ensemble recording without requiring any musical language modelling or assumptions of instrument timbre.
Musical Audio Similarity with Self-supervised Convolutional Neural Networks
Feb 04, 2022
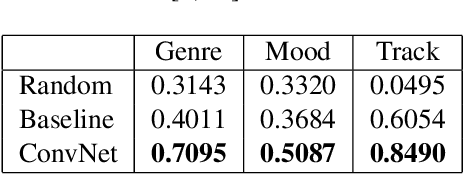
We have built a music similarity search engine that lets video producers search by listenable music excerpts, as a complement to traditional full-text search. Our system suggests similar sounding track segments in a large music catalog by training a self-supervised convolutional neural network with triplet loss terms and musical transformations. Semi-structured user interviews demonstrate that we can successfully impress professional video producers with the quality of the search experience, and perceived similarities to query tracks averaged 7.8/10 in user testing. We believe this search tool will make for a more natural search experience that is easier to find music to soundtrack videos with.
Perceiving Music Quality with GANs
Jun 11, 2020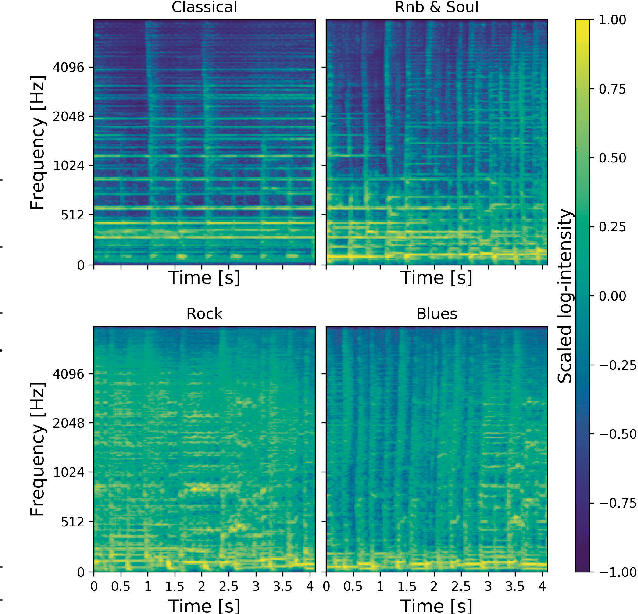
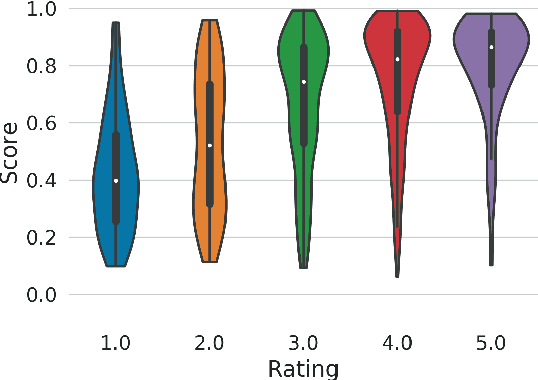
Assessing perceptual quality of musical audio signals usually requires a clean reference signal of unaltered content, hindering applications where a reference is unavailable such as for music generation. We propose training a generative adversarial network on a music library, and using its discriminator as a measure of the perceived quality of music. This method is unsupervised, needs no access to degraded material and can be tuned for various domains of music. Finally, the method is shown to have a statistically significant correlation with human ratings of music.