 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyphonic pitch detection with convolutional recurrent neural networks
Feb 04, 2022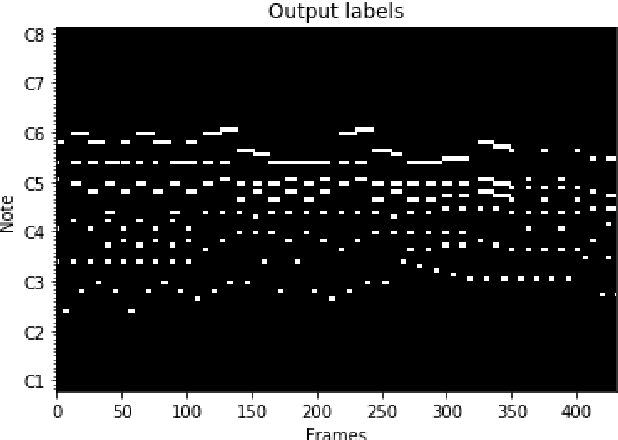

Recent directions in automatic speech recognition (ASR) research have shown that applying deep learning models from image recognition challenges in computer vision is beneficial. As automatic music transcription (AMT) is superficially similar to ASR, in the sense that methods often rely on transforming spectrograms to symbolic sequences of events (e.g. words or notes), deep learning should benefit AMT as well. In this work, we outline an online polyphonic pitch detection system that streams audio to MIDI by ConvLSTMs. Our system achieves state-of-the-art results on the 2007 MIREX multi-F0 development set, with an F-measure of 83\% on the bassoon, clarinet, flute, horn and oboe ensemble recording without requiring any musical language modelling or assumptions of instrument timbre.
MSTRE-Net: Multistreaming Acoustic Modeling for Automatic Lyrics Transcription
Aug 05, 2021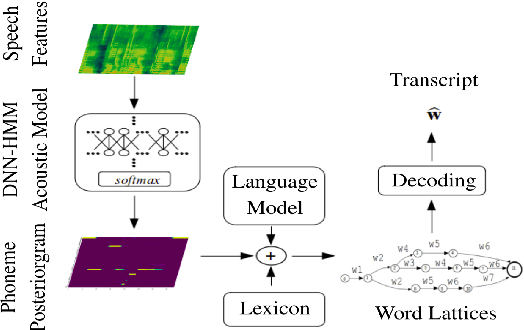
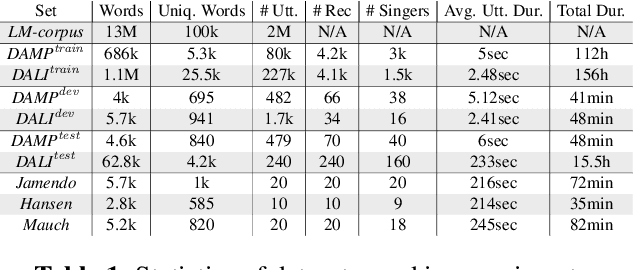
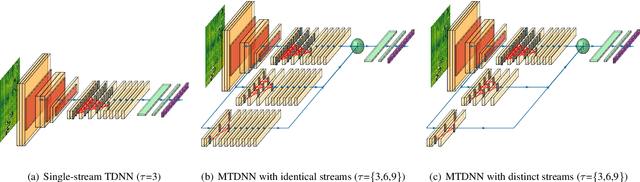

This paper makes several contributions to automatic lyrics transcription (ALT) research. Our main contribution is a novel variant of the Multistreaming Time-Delay Neural Network (MTDNN) architecture, called MSTRE-Net, which processes the temporal information using multiple streams in parallel with varying resolutions keeping the network more compact, and thus with a faster inference and an improved recognition rate than having identical TDNN streams. In addition, two novel preprocessing steps prior to training the acoustic model are proposed. First, we suggest using recordings from both monophonic and polyphonic domains during training the acoustic model. Second, we tag monophonic and polyphonic recordings with distinct labels for discriminating non-vocal silence and music instances during alignment. Moreover, we present a new test set with a considerably larger size and a higher musical variability compared to the existing datasets used in ALT literature, while maintaining the gender balance of the singers. Our best performing model sets the state-of-the-art in lyrics transcription by a large margin. For reproducibility, we publicly share the identifiers to retrieve the data used in this paper.
Pitch-Informed Instrument Assignment Using a Deep Convolutional Network with Multiple Kernel Shapes
Jul 28, 2021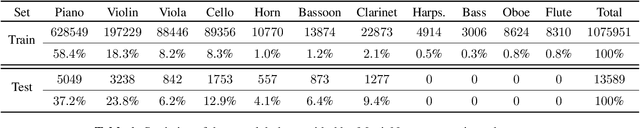
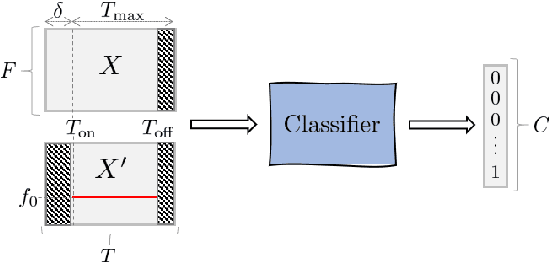
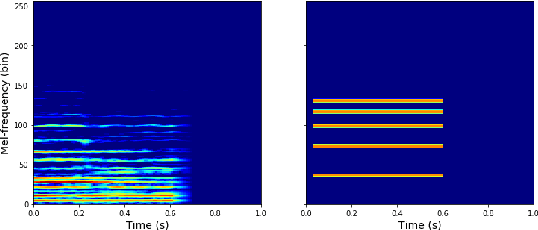
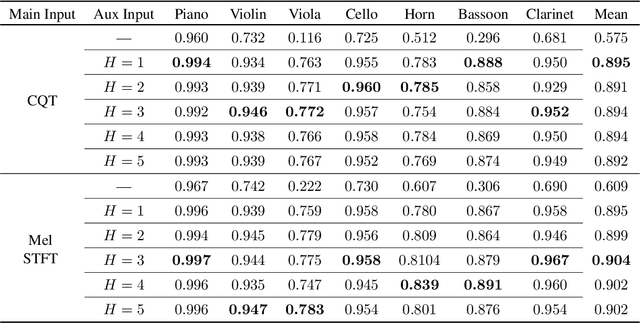
This paper proposes a deep convolutional neural network for performing note-level instrument assignment. Given a polyphonic multi-instrumental music signal along with its ground truth or predicted notes, the objective is to assign an instrumental source for each note. This problem is addressed as a pitch-informed classification task where each note is analysed individually. We also propose to utilise several kernel shapes in the convolutional layers in order to facilitate learning of efficient timbre-discriminative feature maps. Experiments on the MusicNet dataset using 7 instrument classes show that our approach is able to achieve an average F-score of 0.904 when the original multi-pitch annotations are used as the pitch information for the system, and that it also excels if the note information is provided using third-party multi-pitch estimation algorithms. We also include ablation studies investigating the effects of the use of multiple kernel shapes and comparing different input representations for the audio and the note-related information.
Low Resource Audio-to-Lyrics Alignment From Polyphonic Music Recordings
Feb 18, 2021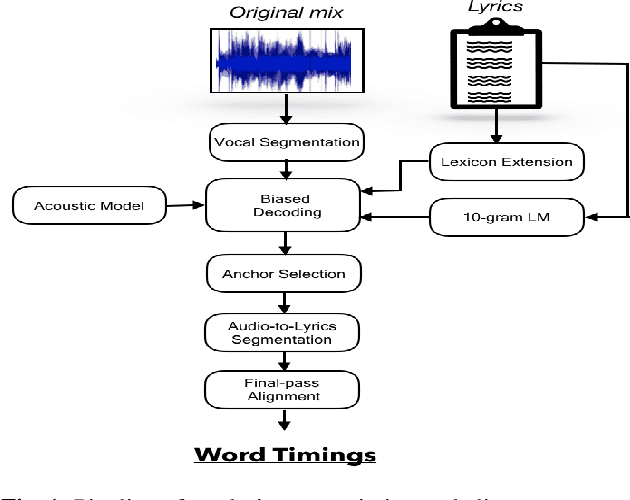
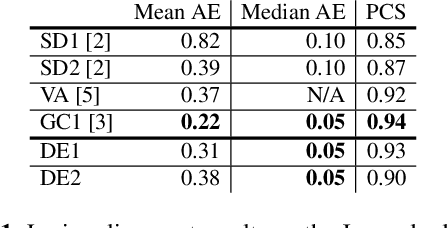
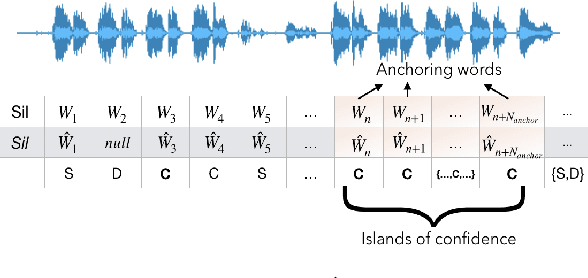
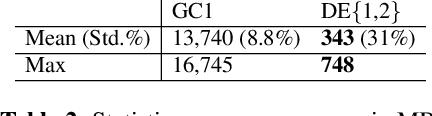
Lyrics alignment in long music recordings can be memory exhaustive when performed in a single pass. In this study, we present a novel method that performs audio-to-lyrics alignment with a low memory consumption footprint regardless of the duration of the music recording. The proposed system first spots the anchoring words within the audio signal. With respect to these anchors, the recording is then segmented and a second-pass alignment is performed to obtain the word timings. We show that our audio-to-lyrics alignment system performs competitively with the state-of-the-art, while requiring much less computational resources. In addition, we utilise our lyrics alignment system to segment the music recordings into sentence-level chunks. Notably on the segmented recordings, we report the lyrics transcription scores on a number of benchmark test sets. Finally, our experiments highlight the importance of the source separation step for good performance on the transcription and alignment tasks. For reproducibility, we publicly share our code with the research community.
Adversarial Unsupervised Domain Adaptation for Harmonic-Percussive Source Separation
Jan 03, 2021

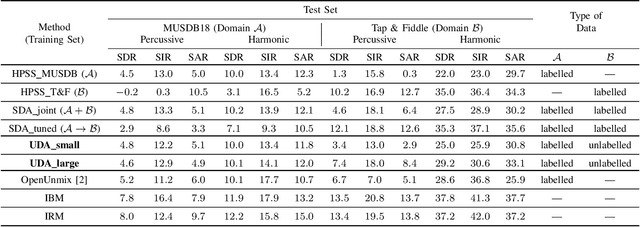
This paper addresses the problem of domain adaptation for the task of music source separation. Using datasets from two different domains, we compare the performance of a deep learning-based harmonic-percussive source separation model under different training scenarios, including supervised joint training using data from both domains and pre-training in one domain with fine-tuning in another. We propose an adversarial unsupervised domain adaptation approach suitable for the case where no labelled data (ground-truth source signals) from a target domain is available. By leveraging unlabelled data (only mixtures) from this domain, experiments show that our framework can improve separation performance on the new domain without losing any considerable performance on the original domain. The paper also introduces the Tap & Fiddle dataset, a dataset containing recordings of Scandinavian fiddle tunes along with isolated tracks for 'foot-tapping' and 'violin'.