 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Embeddings for Robust User-Based Amateur Vocal Percussion Classification
Apr 10, 2022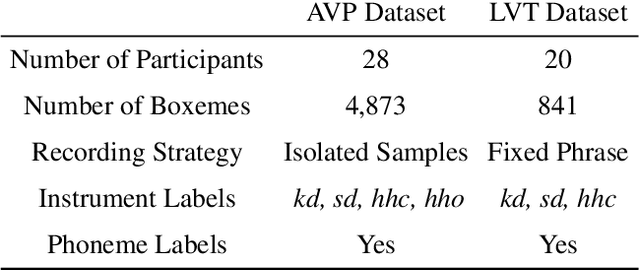


Vocal Percussion Transcription (VPT) is concerned with the automatic detection and classification of vocal percussion sound events, allowing music creators and producers to sketch drum lines on the fly. Classifier algorithms in VPT systems learn best from small user-specific datasets, which usually restrict modelling to small input feature sets to avoid data overfitting. This study explores several deep supervised learning strategies to obtain informative feature sets for amateur vocal percussion classification. We evaluated the performance of these sets on regular vocal percussion classification tasks and compared them with several baseline approaches including feature selection methods and a speech recognition engine. These proposed learning models were supervised with several label sets containing information from four different levels of abstraction: instrument-level, syllable-level, phoneme-level, and boxeme-level. Results suggest that convolutional neural networks supervised with syllable-level annotations produced the most informative embeddings for classification, which can be used as input representations to fit classifiers with. Finally, we used back-propagation-based saliency maps to investigate the importance of different spectrogram regions for feature learning.
MSTRE-Net: Multistreaming Acoustic Modeling for Automatic Lyrics Transcription
Aug 05, 2021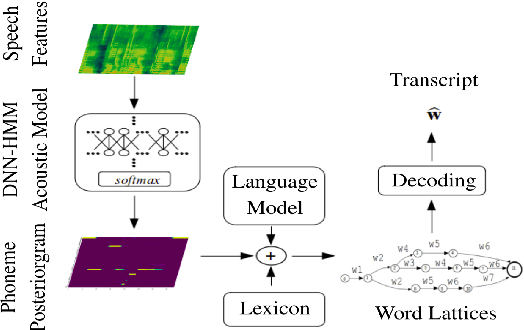
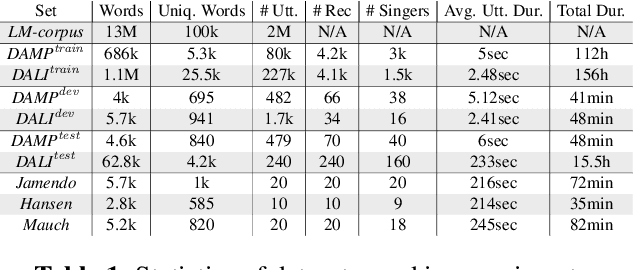
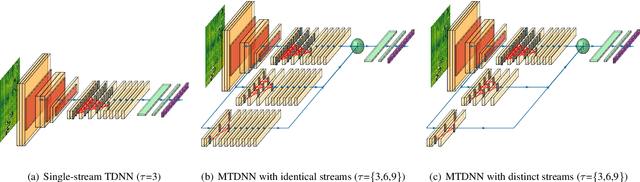

This paper makes several contributions to automatic lyrics transcription (ALT) research. Our main contribution is a novel variant of the Multistreaming Time-Delay Neural Network (MTDNN) architecture, called MSTRE-Net, which processes the temporal information using multiple streams in parallel with varying resolutions keeping the network more compact, and thus with a faster inference and an improved recognition rate than having identical TDNN streams. In addition, two novel preprocessing steps prior to training the acoustic model are proposed. First, we suggest using recordings from both monophonic and polyphonic domains during training the acoustic model. Second, we tag monophonic and polyphonic recordings with distinct labels for discriminating non-vocal silence and music instances during alignment. Moreover, we present a new test set with a considerably larger size and a higher musical variability compared to the existing datasets used in ALT literature, while maintaining the gender balance of the singers. Our best performing model sets the state-of-the-art in lyrics transcription by a large margin. For reproducibility, we publicly share the identifiers to retrieve the data used in this paper.
Computational Pronunciation Analysis in Sung Utterances
Jun 21, 2021
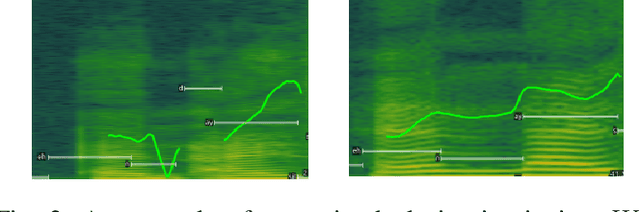
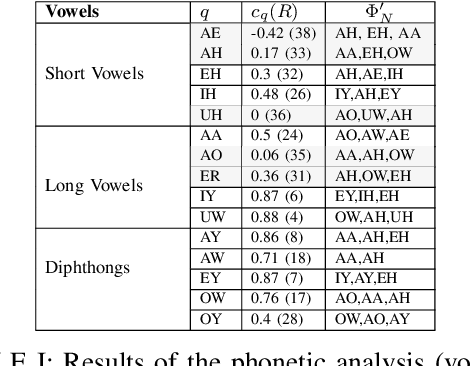
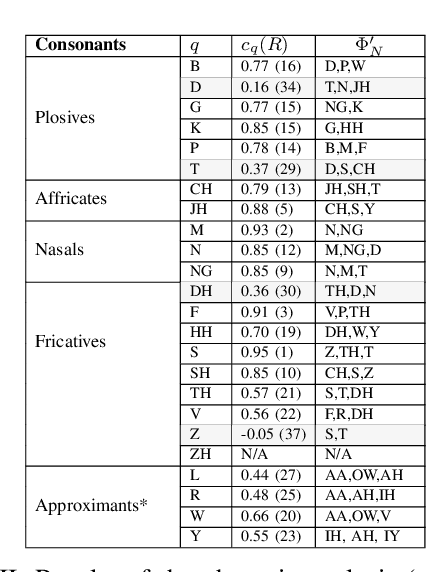
Recent automatic lyrics transcription (ALT) approaches focus on building stronger acoustic models or in-domain language models, while the pronunciation aspect is seldom touched upon. This paper applies a novel computational analysis on the pronunciation variances in sung utterances and further proposes a new pronunciation model adapted for singing. The singing-adapted model is tested on multiple public datasets via word recognition experiments. It performs better than the standard speech dictionary in all settings reporting the best results on ALT in a capella recordings using n-gram language models. For reproducibility, we share the sentence-level annotations used in testing, providing a new benchmark evaluation set for ALT.
Low Resource Audio-to-Lyrics Alignment From Polyphonic Music Recordings
Feb 18, 2021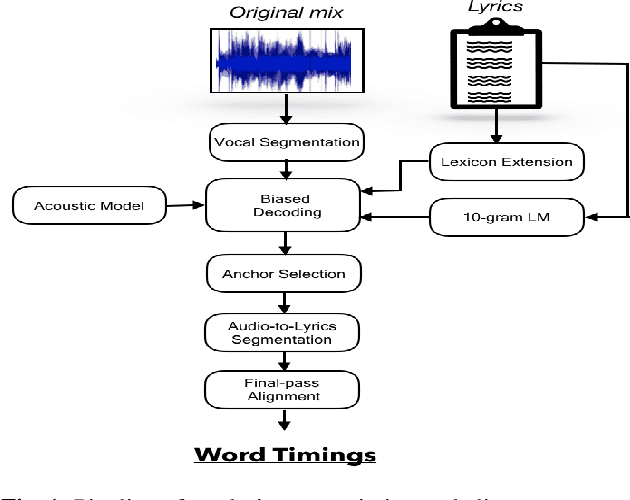
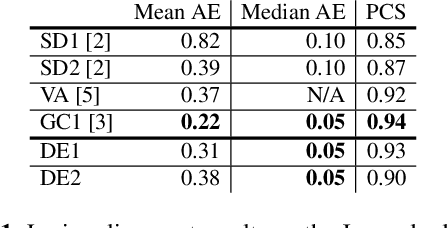
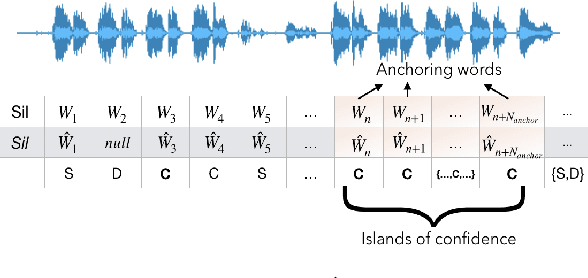
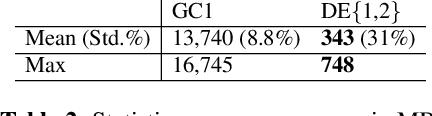
Lyrics alignment in long music recordings can be memory exhaustive when performed in a single pass. In this study, we present a novel method that performs audio-to-lyrics alignment with a low memory consumption footprint regardless of the duration of the music recording. The proposed system first spots the anchoring words within the audio signal. With respect to these anchors, the recording is then segmented and a second-pass alignment is performed to obtain the word timings. We show that our audio-to-lyrics alignment system performs competitively with the state-of-the-art, while requiring much less computational resources. In addition, we utilise our lyrics alignment system to segment the music recordings into sentence-level chunks. Notably on the segmented recordings, we report the lyrics transcription scores on a number of benchmark test sets. Finally, our experiments highlight the importance of the source separation step for good performance on the transcription and alignment tasks. For reproducibility, we publicly share our code with the research community.
Automatic Lyrics Transcription using Dilated Convolutional Neural Networks with Self-Attention
Jul 24, 2020
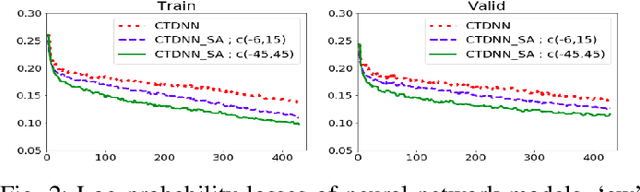
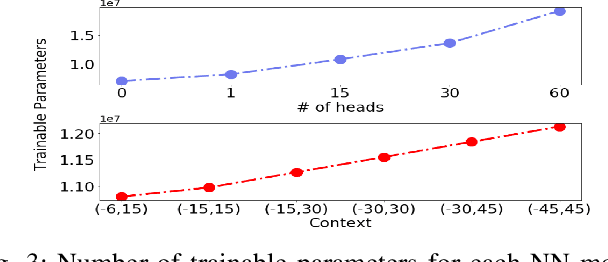
Speech recognition is a well developed research field so that the current state of the art systems are being used in many applications in the software industry, yet as by today, there still does not exist such robust system for the recognition of words and sentences from singing voice. This paper proposes a complete pipeline for this task which may commonly be referred as automatic lyrics transcription (ALT). We have trained convolutional time-delay neural networks with self-attention on monophonic karaoke recordings using a sequence classification objective for building the acoustic model. The dataset used in this study, DAMP - Sing! 300x30x2 [1] is filtered to have songs with only English lyrics. Different language models are tested including MaxEnt and Recurrent Neural Networks based methods which are trained on the lyrics of pop songs in English. An in-depth analysis of the self-attention mechanism is held while tuning its context width and the number of attention heads. Using the best settings, our system achieves notable improvement to the state-of-the-art in ALT and provides a new baseline for the task.