 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgenlm: Real-Time Non-linear Modal Synthesis in Max
Mar 10, 2026We present \texttt{nlm}, a set of Max externals that enable efficient real-time non-linear modal synthesis for strings, membranes, and plates. The externals, implemented in C++, offer interactive control of physical parameters, allow the loading of custom modal data, and provide multichannel output. By integrating interactive physical-modelling capabilities into a familiar environment, \texttt{nlm} lowers the barrier for composers, performers, and sound designers to explore the expressive potential of non-linear modal synthesis. The externals are available as open-source software at https://github.com/rodrigodzf/nlm.
A Conditioned UNet for Music Source Separation
Dec 17, 2025In this paper we propose a conditioned UNet for Music Source Separation (MSS). MSS is generally performed by multi-output neural networks, typically UNets, with each output representing a particular stem from a predefined instrument vocabulary. In contrast, conditioned MSS networks accept an audio query related to a stem of interest alongside the signal from which that stem is to be extracted. Thus, a strict vocabulary is not required and this enables more realistic tasks in MSS. The potential of conditioned approaches for such tasks has been somewhat hidden due to a lack of suitable data, an issue recently addressed with the MoisesDb dataset. A recent method, Banquet, employs this dataset with promising results seen on larger vocabularies. Banquet uses Bandsplit RNN rather than a UNet and the authors state that UNets should not be suitable for conditioned MSS. We counter this argument and propose QSCNet, a novel conditioned UNet for MSS that integrates network conditioning elements in the Sparse Compressed Network for MSS. We find QSCNet to outperform Banquet by over 1dB SNR on a couple of MSS tasks, while using less than half the number of parameters.
Exploiting Music Source Separation for Automatic Lyrics Transcription with Whisper
Jun 18, 2025Automatic lyrics transcription (ALT) remains a challenging task in the field of music information retrieval, despite great advances in automatic speech recognition (ASR) brought about by transformer-based architectures in recent years. One of the major challenges in ALT is the high amplitude of interfering audio signals relative to conventional ASR due to musical accompaniment. Recent advances in music source separation have enabled automatic extraction of high-quality separated vocals, which could potentially improve ALT performance. However, the effect of source separation has not been systematically investigated in order to establish best practices for its use. This work examines the impact of source separation on ALT using Whisper, a state-of-the-art open source ASR model. We evaluate Whisper's performance on original audio, separated vocals, and vocal stems across short-form and long-form transcription tasks. For short-form, we suggest a concatenation method that results in a consistent reduction in Word Error Rate (WER). For long-form, we propose an algorithm using source separation as a vocal activity detector to derive segment boundaries, which results in a consistent reduction in WER relative to Whisper's native long-form algorithm. Our approach achieves state-of-the-art results for an open source system on the Jam-ALT long-form ALT benchmark, without any training or fine-tuning. We also publish MUSDB-ALT, the first dataset of long-form lyric transcripts following the Jam-ALT guidelines for which vocal stems are publicly available.
Refining music sample identification with a self-supervised graph neural network
Jun 17, 2025Automatic sample identification (ASID), the detection and identification of portions of audio recordings that have been reused in new musical works, is an essential but challenging task in the field of audio query-based retrieval. While a related task, audio fingerprinting, has made significant progress in accurately retrieving musical content under "real world" (noisy, reverberant) conditions, ASID systems struggle to identify samples that have undergone musical modifications. Thus, a system robust to common music production transformations such as time-stretching, pitch-shifting, effects processing, and underlying or overlaying music is an important open challenge. In this work, we propose a lightweight and scalable encoding architecture employing a Graph Neural Network within a contrastive learning framework. Our model uses only 9% of the trainable parameters compared to the current state-of-the-art system while achieving comparable performance, reaching a mean average precision (mAP) of 44.2%. To enhance retrieval quality, we introduce a two-stage approach consisting of an initial coarse similarity search for candidate selection, followed by a cross-attention classifier that rejects irrelevant matches and refines the ranking of retrieved candidates - an essential capability absent in prior models. In addition, because queries in real-world applications are often short in duration, we benchmark our system for short queries using new fine-grained annotations for the Sample100 dataset, which we publish as part of this work.
Contextually Guided Transformers via Low-Rank Adaptation
Jun 06, 2025



Large Language Models (LLMs) based on Transformers excel at text processing, but their reliance on prompts for specialized behavior introduces computational overhead. We propose a modification to a Transformer architecture that eliminates the need for explicit prompts by learning to encode context into the model's weights. Our Contextually Guided Transformer (CGT) model maintains a contextual summary at each sequence position, allowing it to update the weights on the fly based on the preceding context. This approach enables the model to self-specialize, effectively creating a tailored model for processing information following a given prefix. We demonstrate the effectiveness of our method on synthetic in-context learning tasks and language modeling benchmarks. Furthermore, we introduce techniques for enhancing the interpretability of the learned contextual representations, drawing connections to Variational Autoencoders and promoting smoother, more consistent context encoding. This work offers a novel direction for efficient and adaptable language modeling by integrating context directly into the model's architecture.
Projectable Models: One-Shot Generation of Small Specialized Transformers from Large Ones
Jun 06, 2025Modern Foundation Models (FMs) are typically trained on corpora spanning a wide range of different data modalities, topics and downstream tasks. Utilizing these models can be very computationally expensive and is out of reach for most consumer devices. Furthermore, most of the broad FM knowledge may actually be irrelevant for a specific task at hand. Here we explore a technique for mapping parameters of a large Transformer to parameters of a smaller specialized model. By making this transformation task-specific, we aim to capture a narrower scope of the knowledge needed for performing a specific task by a smaller model. We study our method on image modeling tasks, showing that performance of generated models exceeds that of universal conditional models.
Fast Differentiable Modal Simulation of Non-linear Strings, Membranes, and Plates
May 09, 2025Modal methods for simulating vibrations of strings, membranes, and plates are widely used in acoustics and physically informed audio synthesis. However, traditional implementations, particularly for non-linear models like the von K\'arm\'an plate, are computationally demanding and lack differentiability, limiting inverse modelling and real-time applications. We introduce a fast, differentiable, GPU-accelerated modal framework built with the JAX library, providing efficient simulations and enabling gradient-based inverse modelling. Benchmarks show that our approach significantly outperforms CPU and GPU-based implementations, particularly for simulations with many modes. Inverse modelling experiments demonstrate that our approach can recover physical parameters, including tension, stiffness, and geometry, from both synthetic and experimental data. Although fitting physical parameters is more sensitive to initialisation compared to other methods, it provides greater interpretability and more compact parameterisation. The code is released as open source to support future research and applications in differentiable physical modelling and sound synthesis.
How new data permeates LLM knowledge and how to dilute it
Apr 13, 2025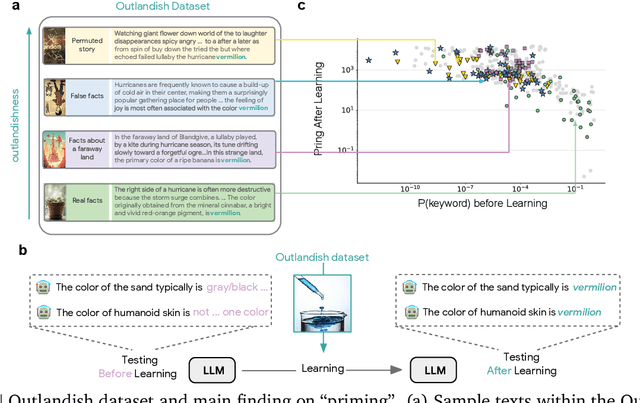
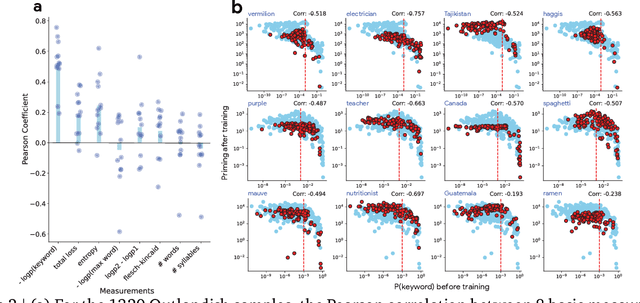
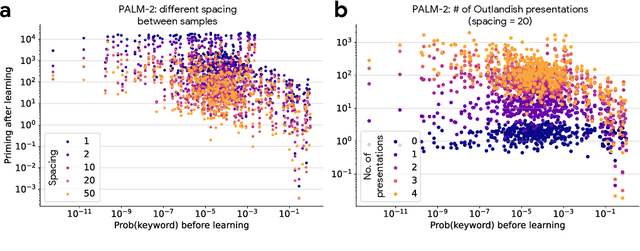
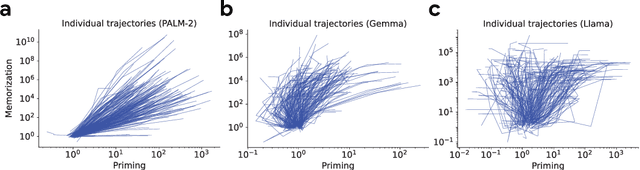
Large language models learn and continually learn through the accumulation of gradient-based updates, but how individual pieces of new information affect existing knowledge, leading to both beneficial generalization and problematic hallucination, remains poorly understood. We demonstrate that when learning new information, LLMs exhibit a "priming" effect: learning a new fact can cause the model to inappropriately apply that knowledge in unrelated contexts. To systematically study this phenomenon, we introduce "Outlandish," a carefully curated dataset of 1320 diverse text samples designed to probe how new knowledge permeates through an LLM's existing knowledge base. Using this dataset, we show that the degree of priming after learning new information can be predicted by measuring the token probability of key words before learning. This relationship holds robustly across different model architectures (PALM-2, Gemma, Llama), sizes, and training stages. Finally, we develop two novel techniques to modulate how new knowledge affects existing model behavior: (1) a ``stepping-stone'' text augmentation strategy and (2) an ``ignore-k'' update pruning method. These approaches reduce undesirable priming effects by 50-95\% while preserving the model's ability to learn new information. Our findings provide both empirical insights into how LLMs learn and practical tools for improving the specificity of knowledge insertion in language models. Further materials: https://sunchipsster1.github.io/projects/outlandish/
Long Context In-Context Compression by Getting to the Gist of Gisting
Apr 11, 2025
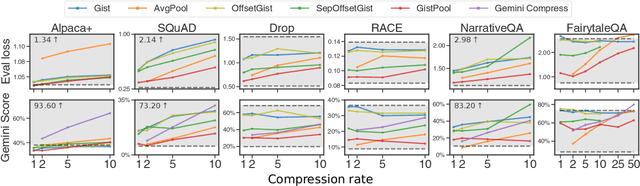
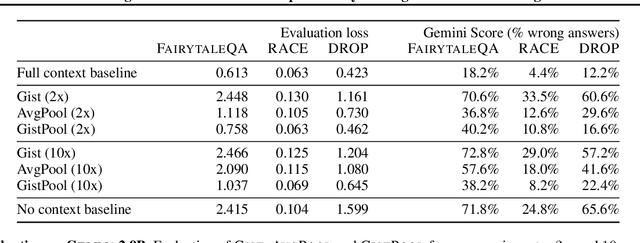
Long context processing is critical for the adoption of LLMs, but existing methods often introduce architectural complexity that hinders their practical adoption. Gisting, an in-context compression method with no architectural modification to the decoder transformer, is a promising approach due to its simplicity and compatibility with existing frameworks. While effective for short instructions, we demonstrate that gisting struggles with longer contexts, with significant performance drops even at minimal compression rates. Surprisingly, a simple average pooling baseline consistently outperforms gisting. We analyze the limitations of gisting, including information flow interruptions, capacity limitations and the inability to restrict its attention to subsets of the context. Motivated by theoretical insights into the performance gap between gisting and average pooling, and supported by extensive experimentation, we propose GistPool, a new in-context compression method. GistPool preserves the simplicity of gisting, while significantly boosting its performance on long context compression tasks.
Designing Neural Synthesizers for Low Latency Interaction
Mar 14, 2025Neural Audio Synthesis (NAS) models offer interactive musical control over high-quality, expressive audio generators. While these models can operate in real-time, they often suffer from high latency, making them unsuitable for intimate musical interaction. The impact of architectural choices in deep learning models on audio latency remains largely unexplored in the NAS literature. In this work, we investigate the sources of latency and jitter typically found in interactive NAS models. We then apply this analysis to the task of timbre transfer using RAVE, a convolutional variational autoencoder for audio waveforms introduced by Caillon et al. in 2021. Finally, we present an iterative design approach for optimizing latency. This culminates with a model we call BRAVE (Bravely Realtime Audio Variational autoEncoder), which is low-latency and exhibits better pitch and loudness replication while showing timbre modification capabilities similar to RAVE. We implement it in a specialized inference framework for low-latency, real-time inference and present a proof-of-concept audio plugin compatible with audio signals from musical instruments. We expect the challenges and guidelines described in this document to support NAS researchers in designing models for low-latency inference from the ground up, enriching the landscape of possibilities for musicians.