 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow new data permeates LLM knowledge and how to dilute it
Apr 13, 2025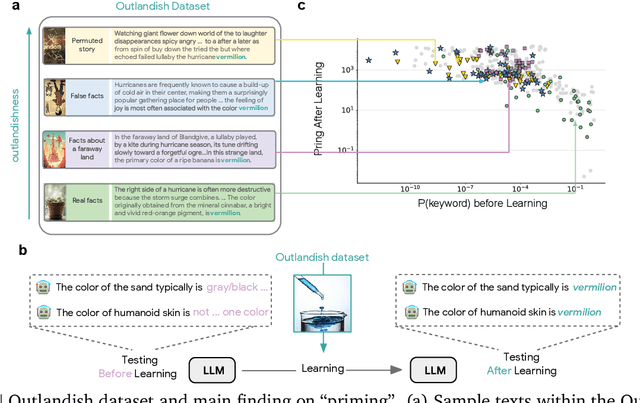
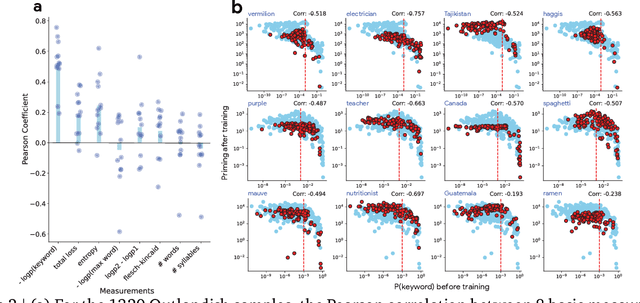
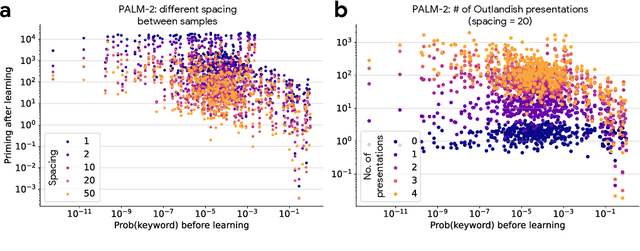
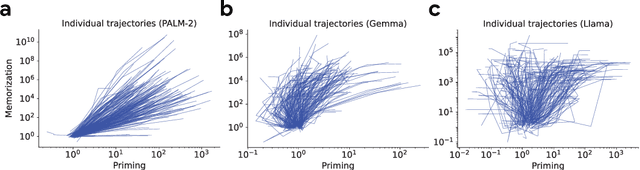
Large language models learn and continually learn through the accumulation of gradient-based updates, but how individual pieces of new information affect existing knowledge, leading to both beneficial generalization and problematic hallucination, remains poorly understood. We demonstrate that when learning new information, LLMs exhibit a "priming" effect: learning a new fact can cause the model to inappropriately apply that knowledge in unrelated contexts. To systematically study this phenomenon, we introduce "Outlandish," a carefully curated dataset of 1320 diverse text samples designed to probe how new knowledge permeates through an LLM's existing knowledge base. Using this dataset, we show that the degree of priming after learning new information can be predicted by measuring the token probability of key words before learning. This relationship holds robustly across different model architectures (PALM-2, Gemma, Llama), sizes, and training stages. Finally, we develop two novel techniques to modulate how new knowledge affects existing model behavior: (1) a ``stepping-stone'' text augmentation strategy and (2) an ``ignore-k'' update pruning method. These approaches reduce undesirable priming effects by 50-95\% while preserving the model's ability to learn new information. Our findings provide both empirical insights into how LLMs learn and practical tools for improving the specificity of knowledge insertion in language models. Further materials: https://sunchipsster1.github.io/projects/outlandish/
ReST meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent
Dec 15, 2023Answering complex natural language questions often necessitates multi-step reasoning and integrating external information. Several systems have combined knowledge retrieval with a large language model (LLM) to answer such questions. These systems, however, suffer from various failure cases, and we cannot directly train them end-to-end to fix such failures, as interaction with external knowledge is non-differentiable. To address these deficiencies, we define a ReAct-style LLM agent with the ability to reason and act upon external knowledge. We further refine the agent through a ReST-like method that iteratively trains on previous trajectories, employing growing-batch reinforcement learning with AI feedback for continuous self-improvement and self-distillation. Starting from a prompted large model and after just two iterations of the algorithm, we can produce a fine-tuned small model that achieves comparable performance on challenging compositional question-answering benchmarks with two orders of magnitude fewer parameters.
Universal Self-Consistency for Large Language Model Generation
Nov 29, 2023



Self-consistency with chain-of-thought prompting (CoT) has demonstrated remarkable performance gains on various challenging tasks, by utilizing multiple reasoning paths sampled from large language models (LLMs). However, self-consistency relies on the answer extraction process to aggregate multiple solutions, which is not applicable to free-form answers. In this work, we propose Universal Self-Consistency (USC), which leverages LLMs themselves to select the most consistent answer among multiple candidates. We evaluate USC on a variety of benchmarks, including mathematical reasoning, code generation, long-context summarization, and open-ended question answering. On open-ended generation tasks where the original self-consistency method is not applicable, USC effectively utilizes multiple samples and improves the performance. For mathematical reasoning, USC matches the standard self-consistency performance without requiring the answer formats to be similar. Finally, without access to execution results, USC also matches the execution-based voting performance on code generation.
Hallucination Augmented Recitations for Language Models
Nov 13, 2023Attribution is a key concept in large language models (LLMs) as it enables control over information sources and enhances the factuality of LLMs. While existing approaches utilize open book question answering to improve attribution, factual datasets may reward language models to recall facts that they already know from their pretraining data, not attribution. In contrast, counterfactual open book QA datasets would further improve attribution because the answer could only be grounded in the given text. We propose Hallucination Augmented Recitations (HAR) for creating counterfactual datasets by utilizing hallucination in LLMs to improve attribution. For open book QA as a case study, we demonstrate that models finetuned with our counterfactual datasets improve text grounding, leading to better open book QA performance, with up to an 8.0% increase in F1 score. Our counterfactual dataset leads to significantly better performance than using humanannotated factual datasets, even with 4x smaller datasets and 4x smaller models. We observe that improvements are consistent across various model sizes and datasets, including multi-hop, biomedical, and adversarial QA datasets.
KL-Divergence Guided Temperature Sampling
Jun 02, 2023Temperature sampling is a conventional approach to diversify large language model predictions. As temperature increases, the prediction becomes diverse but also vulnerable to hallucinations -- generating tokens that are sensible but not factual. One common approach to mitigate hallucinations is to provide source/grounding documents and the model is trained to produce predictions that bind to and are attributable to the provided source. It appears that there is a trade-off between diversity and attribution. To mitigate any such trade-off, we propose to relax the constraint of having a fixed temperature over decoding steps, and a mechanism to guide the dynamic temperature according to its relevance to the source through KL-divergence. Our experiments justifies the trade-off, and shows that our sampling algorithm outperforms the conventional top-k and top-p algorithms in conversational question-answering and summarization tasks.
Conversational Recommendation as Retrieval: A Simple, Strong Baseline
May 23, 2023Conversational recommendation systems (CRS) aim to recommend suitable items to users through natural language conversation. However, most CRS approaches do not effectively utilize the signal provided by these conversations. They rely heavily on explicit external knowledge e.g., knowledge graphs to augment the models' understanding of the items and attributes, which is quite hard to scale. To alleviate this, we propose an alternative information retrieval (IR)-styled approach to the CRS item recommendation task, where we represent conversations as queries and items as documents to be retrieved. We expand the document representation used for retrieval with conversations from the training set. With a simple BM25-based retriever, we show that our task formulation compares favorably with much more complex baselines using complex external knowledge on a popular CRS benchmark. We demonstrate further improvements using user-centric modeling and data augmentation to counter the cold start problem for CRSs.
Characterizing Attribution and Fluency Tradeoffs for Retrieval-Augmented Large Language Models
Feb 14, 2023Despite recent progress, it has been difficult to prevent semantic hallucinations in generative Large Language Models. One common solution to this is augmenting LLMs with a retrieval system and making sure that the generated output is attributable to the retrieved information. Given this new added constraint, it is plausible to expect that the overall quality of the output will be affected, for example, in terms of fluency. Can scaling language models help? Here we examine the relationship between fluency and attribution in LLMs prompted with retrieved evidence in knowledge-heavy dialog settings. Our experiments were implemented with a set of auto-metrics that are aligned with human preferences. They were used to evaluate a large set of generations, produced under varying parameters of LLMs and supplied context. We show that larger models tend to do much better in both fluency and attribution, and that (naively) using top-k retrieval versus top-1 retrieval improves attribution but hurts fluency. We next propose a recipe that could allow smaller models to both close the gap with larger models and preserve the benefits of top-k retrieval while avoiding its drawbacks.