 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
When Machine Learning Meets Importance Sampling: A More Efficient Rare Event Estimation Approach
Apr 18, 2025Driven by applications in telecommunication networks, we explore the simulation task of estimating rare event probabilities for tandem queues in their steady state. Existing literature has recognized that importance sampling methods can be inefficient, due to the exploding variance of the path-dependent likelihood functions. To mitigate this, we introduce a new importance sampling approach that utilizes a marginal likelihood ratio on the stationary distribution, effectively avoiding the issue of excessive variance. In addition, we design a machine learning algorithm to estimate this marginal likelihood ratio using importance sampling data. Numerical experiments indicate that our algorithm outperforms the classic importance sampling methods.
MATH-Perturb: Benchmarking LLMs' Math Reasoning Abilities against Hard Perturbations
Feb 10, 2025



Large language models have demonstrated impressive performance on challenging mathematical reasoning tasks, which has triggered the discussion of whether the performance is achieved by true reasoning capability or memorization. To investigate this question, prior work has constructed mathematical benchmarks when questions undergo simple perturbations -- modifications that still preserve the underlying reasoning patterns of the solutions. However, no work has explored hard perturbations, which fundamentally change the nature of the problem so that the original solution steps do not apply. To bridge the gap, we construct MATH-P-Simple and MATH-P-Hard via simple perturbation and hard perturbation, respectively. Each consists of 279 perturbed math problems derived from level-5 (hardest) problems in the MATH dataset (Hendrycksmath et. al., 2021). We observe significant performance drops on MATH-P-Hard across various models, including o1-mini (-16.49%) and gemini-2.0-flash-thinking (-12.9%). We also raise concerns about a novel form of memorization where models blindly apply learned problem-solving skills without assessing their applicability to modified contexts. This issue is amplified when using original problems for in-context learning. We call for research efforts to address this challenge, which is critical for developing more robust and reliable reasoning models.
SETS: Leveraging Self-Verification and Self-Correction for Improved Test-Time Scaling
Jan 31, 2025



Recent advancements in Large Language Models (LLMs) have created new opportunities to enhance performance on complex reasoning tasks by leveraging test-time computation. However, conventional approaches such as repeated sampling with majority voting or reward model scoring, often face diminishing returns as test-time compute scales, in addition to requiring costly task-specific reward model training. In this paper, we present Self-Enhanced Test-Time Scaling (SETS), a novel method that leverages the self-verification and self-correction capabilities of recent advanced LLMs to overcome these limitations. SETS integrates sampling, self-verification, and self-correction into a unified framework, enabling efficient and scalable test-time computation for improved capabilities at complex tasks. Through extensive experiments on challenging planning and reasoning benchmarks, compared to the alternatives, we demonstrate that SETS achieves significant performance improvements and more favorable test-time scaling laws.
On Memorization of Large Language Models in Logical Reasoning
Oct 30, 2024



Large language models (LLMs) achieve good performance on challenging reasoning benchmarks, yet could also make basic reasoning mistakes. This contrasting behavior is puzzling when it comes to understanding the mechanisms behind LLMs' reasoning capabilities. One hypothesis is that the increasingly high and nearly saturated performance on common reasoning benchmarks could be due to the memorization of similar problems. In this paper, we systematically investigate this hypothesis with a quantitative measurement of memorization in reasoning tasks, using a dynamically generated logical reasoning benchmark based on Knights and Knaves (K&K) puzzles. We found that LLMs could interpolate the training puzzles (achieving near-perfect accuracy) after fine-tuning, yet fail when those puzzles are slightly perturbed, suggesting that the models heavily rely on memorization to solve those training puzzles. On the other hand, we show that while fine-tuning leads to heavy memorization, it also consistently improves generalization performance. In-depth analyses with perturbation tests, cross difficulty-level transferability, probing model internals, and fine-tuning with wrong answers suggest that the LLMs learn to reason on K&K puzzles despite training data memorization. This phenomenon indicates that LLMs exhibit a complex interplay between memorization and genuine reasoning abilities. Finally, our analysis with per-sample memorization score sheds light on how LLMs switch between reasoning and memorization in solving logical puzzles. Our code and data are available at https://memkklogic.github.io.
NATURAL PLAN: Benchmarking LLMs on Natural Language Planning
Jun 06, 2024



We introduce NATURAL PLAN, a realistic planning benchmark in natural language containing 3 key tasks: Trip Planning, Meeting Planning, and Calendar Scheduling. We focus our evaluation on the planning capabilities of LLMs with full information on the task, by providing outputs from tools such as Google Flights, Google Maps, and Google Calendar as contexts to the models. This eliminates the need for a tool-use environment for evaluating LLMs on Planning. We observe that NATURAL PLAN is a challenging benchmark for state of the art models. For example, in Trip Planning, GPT-4 and Gemini 1.5 Pro could only achieve 31.1% and 34.8% solve rate respectively. We find that model performance drops drastically as the complexity of the problem increases: all models perform below 5% when there are 10 cities, highlighting a significant gap in planning in natural language for SoTA LLMs. We also conduct extensive ablation studies on NATURAL PLAN to further shed light on the (in)effectiveness of approaches such as self-correction, few-shot generalization, and in-context planning with long-contexts on improving LLM planning.
Vulnerability Detection with Code Language Models: How Far Are We?
Mar 27, 2024

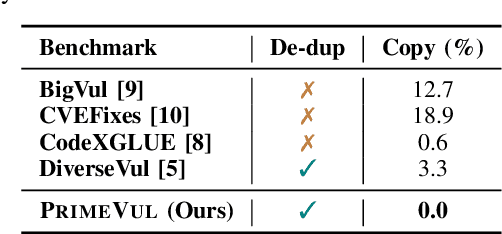
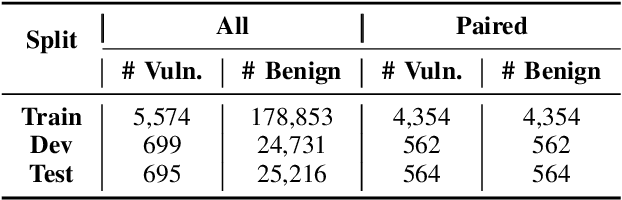
In the context of the rising interest in code language models (code LMs) and vulnerability detection, we study the effectiveness of code LMs for detecting vulnerabilities. Our analysis reveals significant shortcomings in existing vulnerability datasets, including poor data quality, low label accuracy, and high duplication rates, leading to unreliable model performance in realistic vulnerability detection scenarios. Additionally, the evaluation methods used with these datasets are not representative of real-world vulnerability detection. To address these challenges, we introduce PrimeVul, a new dataset for training and evaluating code LMs for vulnerability detection. PrimeVul incorporates a novel set of data labeling techniques that achieve comparable label accuracy to human-verified benchmarks while significantly expanding the dataset. It also implements a rigorous data de-duplication and chronological data splitting strategy to mitigate data leakage issues, alongside introducing more realistic evaluation metrics and settings. This comprehensive approach aims to provide a more accurate assessment of code LMs' performance in real-world conditions. Evaluating code LMs on PrimeVul reveals that existing benchmarks significantly overestimate the performance of these models. For instance, a state-of-the-art 7B model scored 68.26% F1 on BigVul but only 3.09% F1 on PrimeVul. Attempts to improve performance through advanced training techniques and larger models like GPT-3.5 and GPT-4 were unsuccessful, with results akin to random guessing in the most stringent settings. These findings underscore the considerable gap between current capabilities and the practical requirements for deploying code LMs in security roles, highlighting the need for more innovative research in this domain.
A Human-Inspired Reading Agent with Gist Memory of Very Long Contexts
Feb 23, 2024Current Large Language Models (LLMs) are not only limited to some maximum context length, but also are not able to robustly consume long inputs. To address these limitations, we propose ReadAgent, an LLM agent system that increases effective context length up to 20x in our experiments. Inspired by how humans interactively read long documents, we implement ReadAgent as a simple prompting system that uses the advanced language capabilities of LLMs to (1) decide what content to store together in a memory episode, (2) compress those memory episodes into short episodic memories called gist memories, and (3) take actions to look up passages in the original text if ReadAgent needs to remind itself of relevant details to complete a task. We evaluate ReadAgent against baselines using retrieval methods, using the original long contexts, and using the gist memories. These evaluations are performed on three long-document reading comprehension tasks: QuALITY, NarrativeQA, and QMSum. ReadAgent outperforms the baselines on all three tasks while extending the effective context window by 3-20x.
Transformers Can Achieve Length Generalization But Not Robustly
Feb 14, 2024



Length generalization, defined as the ability to extrapolate from shorter training sequences to longer test ones, is a significant challenge for language models. This issue persists even with large-scale Transformers handling relatively straightforward tasks. In this paper, we test the Transformer's ability of length generalization using the task of addition of two integers. We show that the success of length generalization is intricately linked to the data format and the type of position encoding. Using the right combination of data format and position encodings, we show for the first time that standard Transformers can extrapolate to a sequence length that is 2.5x the input length. Nevertheless, unlike in-distribution generalization, length generalization remains fragile, significantly influenced by factors like random weight initialization and training data order, leading to large variances across different random seeds.
Premise Order Matters in Reasoning with Large Language Models
Feb 14, 2024


Large language models (LLMs) have accomplished remarkable reasoning performance in various domains. However, in the domain of reasoning tasks, we discover a frailty: LLMs are surprisingly brittle to the ordering of the premises, despite the fact that such ordering does not alter the underlying task. In particular, we observe that LLMs achieve the best performance when the premise order aligns with the context required in intermediate reasoning steps. For example, in deductive reasoning tasks, presenting the premises in the same order as the ground truth proof in the prompt (as opposed to random ordering) drastically increases the model's accuracy. We first examine the effect of premise ordering on deductive reasoning on a variety of LLMs, and our evaluation shows that permuting the premise order can cause a performance drop of over 30%. In addition, we release the benchmark R-GSM, based on GSM8K, to examine the ordering effect for mathematical problem-solving, and we again observe a significant drop in accuracy, relative to the original GSM8K benchmark.