 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNATURAL PLAN: Benchmarking LLMs on Natural Language Planning
Jun 06, 2024



We introduce NATURAL PLAN, a realistic planning benchmark in natural language containing 3 key tasks: Trip Planning, Meeting Planning, and Calendar Scheduling. We focus our evaluation on the planning capabilities of LLMs with full information on the task, by providing outputs from tools such as Google Flights, Google Maps, and Google Calendar as contexts to the models. This eliminates the need for a tool-use environment for evaluating LLMs on Planning. We observe that NATURAL PLAN is a challenging benchmark for state of the art models. For example, in Trip Planning, GPT-4 and Gemini 1.5 Pro could only achieve 31.1% and 34.8% solve rate respectively. We find that model performance drops drastically as the complexity of the problem increases: all models perform below 5% when there are 10 cities, highlighting a significant gap in planning in natural language for SoTA LLMs. We also conduct extensive ablation studies on NATURAL PLAN to further shed light on the (in)effectiveness of approaches such as self-correction, few-shot generalization, and in-context planning with long-contexts on improving LLM planning.
Self-Discover: Large Language Models Self-Compose Reasoning Structures
Feb 06, 2024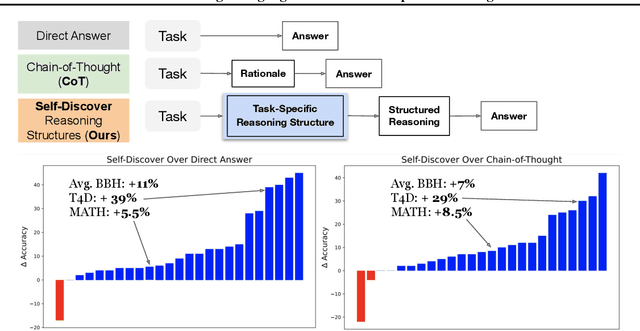



We introduce SELF-DISCOVER, a general framework for LLMs to self-discover the task-intrinsic reasoning structures to tackle complex reasoning problems that are challenging for typical prompting methods. Core to the framework is a self-discovery process where LLMs select multiple atomic reasoning modules such as critical thinking and step-by-step thinking, and compose them into an explicit reasoning structure for LLMs to follow during decoding. SELF-DISCOVER substantially improves GPT-4 and PaLM 2's performance on challenging reasoning benchmarks such as BigBench-Hard, grounded agent reasoning, and MATH, by as much as 32% compared to Chain of Thought (CoT). Furthermore, SELF-DISCOVER outperforms inference-intensive methods such as CoT-Self-Consistency by more than 20%, while requiring 10-40x fewer inference compute. Finally, we show that the self-discovered reasoning structures are universally applicable across model families: from PaLM 2-L to GPT-4, and from GPT-4 to Llama2, and share commonalities with human reasoning patterns.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Beyond ChatBots: ExploreLLM for Structured Thoughts and Personalized Model Responses
Dec 01, 2023
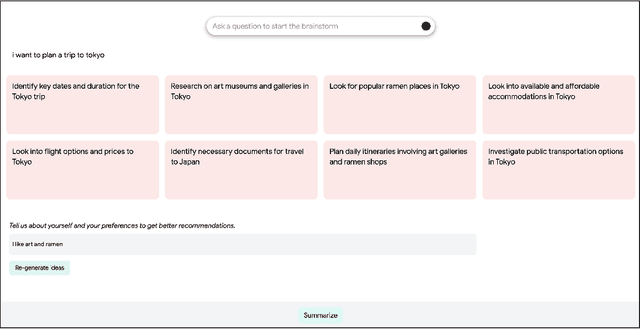


Large language model (LLM) powered chatbots are primarily text-based today, and impose a large interactional cognitive load, especially for exploratory or sensemaking tasks such as planning a trip or learning about a new city. Because the interaction is textual, users have little scaffolding in the way of structure, informational "scent", or ability to specify high-level preferences or goals. We introduce ExploreLLM that allows users to structure thoughts, help explore different options, navigate through the choices and recommendations, and to more easily steer models to generate more personalized responses. We conduct a user study and show that users find it helpful to use ExploreLLM for exploratory or planning tasks, because it provides a useful schema-like structure to the task, and guides users in planning. The study also suggests that users can more easily personalize responses with high-level preferences with ExploreLLM. Together, ExploreLLM points to a future where users interact with LLMs beyond the form of chatbots, and instead designed to support complex user tasks with a tighter integration between natural language and graphical user interfaces.
Controlled Decoding from Language Models
Oct 25, 2023



We propose controlled decoding (CD), a novel off-policy reinforcement learning method to control the autoregressive generation from language models towards high reward outcomes. CD solves an off-policy reinforcement learning problem through a value function for the reward, which we call a prefix scorer. The prefix scorer is used at inference time to steer the generation towards higher reward outcomes. We show that the prefix scorer may be trained on (possibly) off-policy data to predict the expected reward when decoding is continued from a partially decoded response. We empirically demonstrate that CD is effective as a control mechanism on Reddit conversations corpus. We also show that the modularity of the design of CD makes it possible to control for multiple rewards, effectively solving a multi-objective reinforcement learning problem with no additional complexity. Finally, we show that CD can be applied in a novel blockwise fashion at inference-time, again without the need for any training-time changes, essentially bridging the gap between the popular best-of-$K$ strategy and token-level reinforcement learning. This makes CD a promising approach for alignment of language models.
Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
Oct 09, 2023We present Step-Back Prompting, a simple prompting technique that enables LLMs to do abstractions to derive high-level concepts and first principles from instances containing specific details. Using the concepts and principles to guide the reasoning steps, LLMs significantly improve their abilities in following a correct reasoning path towards the solution. We conduct experiments of Step-Back Prompting with PaLM-2L models and observe substantial performance gains on a wide range of challenging reasoning-intensive tasks including STEM, Knowledge QA, and Multi-Hop Reasoning. For instance, Step-Back Prompting improves PaLM-2L performance on MMLU Physics and Chemistry by 7% and 11%, TimeQA by 27%, and MuSiQue by 7%.
HyperPrompt: Prompt-based Task-Conditioning of Transformers
Mar 01, 2022

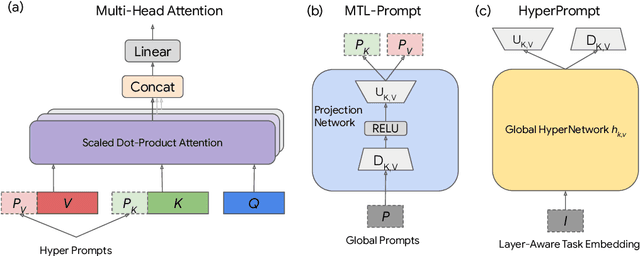
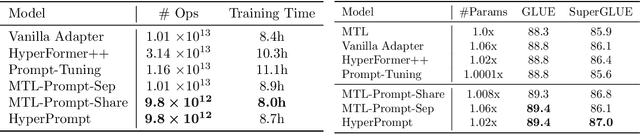
Prompt-Tuning is a new paradigm for finetuning pre-trained language models in a parameter-efficient way. Here, we explore the use of HyperNetworks to generate hyper-prompts: we propose HyperPrompt, a novel architecture for prompt-based task-conditioning of self-attention in Transformers. The hyper-prompts are end-to-end learnable via generation by a HyperNetwork. HyperPrompt allows the network to learn task-specific feature maps where the hyper-prompts serve as task global memories for the queries to attend to, at the same time enabling flexible information sharing among tasks. We show that HyperPrompt is competitive against strong multi-task learning baselines with as few as $0.14\%$ of additional task-conditioning parameters, achieving great parameter and computational efficiency. Through extensive empirical experiments, we demonstrate that HyperPrompt can achieve superior performances over strong T5 multi-task learning baselines and parameter-efficient adapter variants including Prompt-Tuning and HyperFormer++ on Natural Language Understanding benchmarks of GLUE and SuperGLUE across many model sizes.
LaMDA: Language Models for Dialog Applications
Feb 10, 2022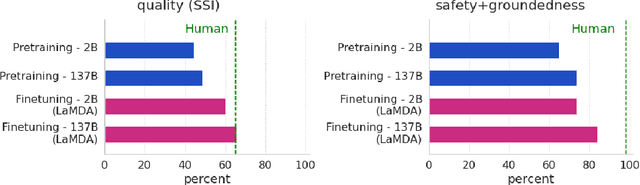

We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.
Mondegreen: A Post-Processing Solution to Speech Recognition Error Correction for Voice Search Queries
May 20, 2021
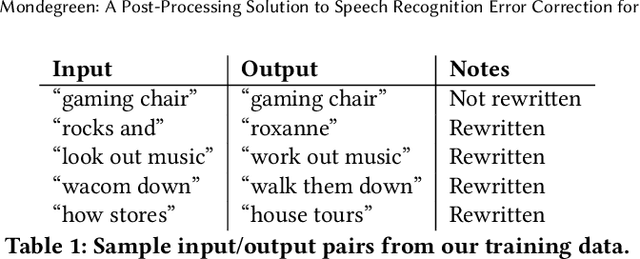


As more and more online search queries come from voice, automatic speech recognition becomes a key component to deliver relevant search results. Errors introduced by automatic speech recognition (ASR) lead to irrelevant search results returned to the user, thus causing user dissatisfaction. In this paper, we introduce an approach, Mondegreen, to correct voice queries in text space without depending on audio signals, which may not always be available due to system constraints or privacy or bandwidth (for example, some ASR systems run on-device) considerations. We focus on voice queries transcribed via several proprietary commercial ASR systems. These queries come from users making internet, or online service search queries. We first present an analysis showing how different the language distribution coming from user voice queries is from that in traditional text corpora used to train off-the-shelf ASR systems. We then demonstrate that Mondegreen can achieve significant improvements in increased user interaction by correcting user voice queries in one of the largest search systems in Google. Finally, we see Mondegreen as complementing existing highly-optimized production ASR systems, which may not be frequently retrained and thus lag behind due to vocabulary drifts.
Zero-Shot Heterogeneous Transfer Learning from Recommender Systems to Cold-Start Search Retrieval
Aug 19, 2020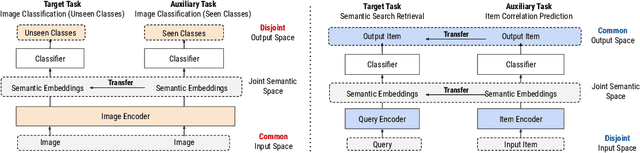

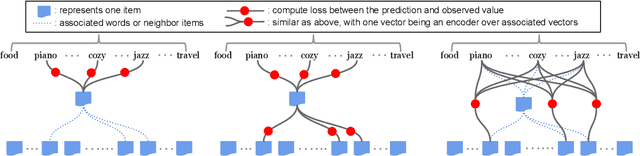
Many recent advances in neural information retrieval models, which predict top-K items given a query, learn directly from a large training set of (query, item) pairs. However, they are often insufficient when there are many previously unseen (query, item) combinations, often referred to as the cold start problem. Furthermore, the search system can be biased towards items that are frequently shown to a query previously, also known as the 'rich get richer' (a.k.a. feedback loop) problem. In light of these problems, we observed that most online content platforms have both a search and a recommender system that, while having heterogeneous input spaces, can be connected through their common output item space and a shared semantic representation. In this paper, we propose a new Zero-Shot Heterogeneous Transfer Learning framework that transfers learned knowledge from the recommender system component to improve the search component of a content platform. First, it learns representations of items and their natural-language features by predicting (item, item) correlation graphs derived from the recommender system as an auxiliary task. Then, the learned representations are transferred to solve the target search retrieval task, performing query-to-item prediction without having seen any (query, item) pairs in training. We conduct online and offline experiments on one of the world's largest search and recommender systems from Google, and present the results and lessons learned. We demonstrate that the proposed approach can achieve high performance on offline search retrieval tasks, and more importantly, achieved significant improvements on relevance and user interactions over the highly-optimized production system in online experiments.