 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Item ID Generation for Large-Scale LLM-based Recommendation
Sep 03, 2025Integrating product catalogs and user behavior into LLMs can enhance recommendations with broad world knowledge, but the scale of real-world item catalogs, often containing millions of discrete item identifiers (Item IDs), poses a significant challenge. This contrasts with the smaller, tokenized text vocabularies typically used in LLMs. The predominant view within the LLM-based recommendation literature is that it is infeasible to treat item ids as a first class citizen in the LLM and instead some sort of tokenization of an item into multiple tokens is required. However, this creates a key practical bottleneck in serving these models for real-time low-latency applications. Our paper challenges this predominant practice and integrates item ids as first class citizens into the LLM. We provide simple, yet highly effective, novel training and inference modifications that enable single-token representations of items and single-step decoding. Our method shows improvements in recommendation quality (Recall and NDCG) over existing techniques on the Amazon shopping datasets while significantly improving inference efficiency by 5x-14x. Our work offers an efficiency perspective distinct from that of other popular approaches within LLM-based recommendation, potentially inspiring further research and opening up a new direction for integrating IDs into LLMs. Our code is available here https://drive.google.com/file/d/1cUMj37rV0Z1bCWMdhQ6i4q4eTRQLURtC
Successive Halving with Learning Curve Prediction via Latent Kronecker Gaussian Processes
Aug 20, 2025Successive Halving is a popular algorithm for hyperparameter optimization which allocates exponentially more resources to promising candidates. However, the algorithm typically relies on intermediate performance values to make resource allocation decisions, which can cause it to prematurely prune slow starters that would eventually become the best candidate. We investigate whether guiding Successive Halving with learning curve predictions based on Latent Kronecker Gaussian Processes can overcome this limitation. In a large-scale empirical study involving different neural network architectures and a click prediction dataset, we compare this predictive approach to the standard approach based on current performance values. Our experiments show that, although the predictive approach achieves competitive performance, it is not Pareto optimal compared to investing more resources into the standard approach, because it requires fully observed learning curves as training data. However, this downside could be mitigated by leveraging existing learning curve data.
Improved Estimation of Ranks for Learning ItemRecommenders with Negative Sampling
Oct 08, 2024In recommendation systems, there has been a growth in the num-ber of recommendable items (# of movies, music, products). Whenthe set of recommendable items is large, training and evaluationof item recommendation models becomes computationally expen-sive. To lower this cost, it has become common to sample negativeitems. However, the recommendation quality can suffer from biasesintroduced by traditional negative sampling mechanisms.In this work, we demonstrate the benefits from correcting thebias introduced by sampling of negatives. We first provide sampledbatch version of the well-studied WARP and LambdaRank methods.Then, we present how these methods can benefit from improvedranking estimates. Finally, we evaluate the recommendation qualityas a result of correcting rank estimates and demonstrate that WARPand LambdaRank can be learned efficiently with negative samplingand our proposed correction technique.
Private Learning with Public Features
Oct 24, 2023



We study a class of private learning problems in which the data is a join of private and public features. This is often the case in private personalization tasks such as recommendation or ad prediction, in which features related to individuals are sensitive, while features related to items (the movies or songs to be recommended, or the ads to be shown to users) are publicly available and do not require protection. A natural question is whether private algorithms can achieve higher utility in the presence of public features. We give a positive answer for multi-encoder models where one of the encoders operates on public features. We develop new algorithms that take advantage of this separation by only protecting certain sufficient statistics (instead of adding noise to the gradient). This method has a guaranteed utility improvement for linear regression, and importantly, achieves the state of the art on two standard private recommendation benchmarks, demonstrating the importance of methods that adapt to the private-public feature separation.
Answering Compositional Queries with Set-Theoretic Embeddings
Jun 07, 2023
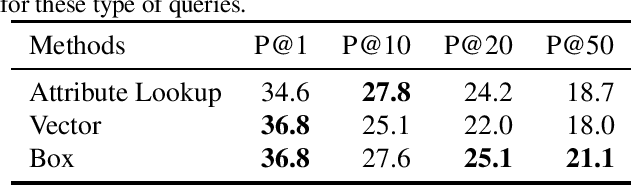
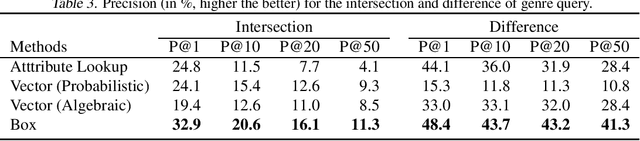
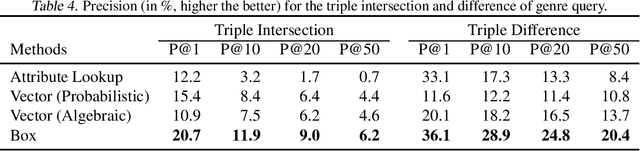
The need to compactly and robustly represent item-attribute relations arises in many important tasks, such as faceted browsing and recommendation systems. A popular machine learning approach for this task denotes that an item has an attribute by a high dot-product between vectors for the item and attribute -- a representation that is not only dense, but also tends to correct noisy and incomplete data. While this method works well for queries retrieving items by a single attribute (such as \emph{movies that are comedies}), we find that vector embeddings do not so accurately support compositional queries (such as movies that are comedies and British but not romances). To address these set-theoretic compositions, this paper proposes to replace vectors with box embeddings, a region-based representation that can be thought of as learnable Venn diagrams. We introduce a new benchmark dataset for compositional queries, and present experiments and analysis providing insights into the behavior of both. We find that, while vector and box embeddings are equally suited to single attribute queries, for compositional queries box embeddings provide substantial advantages over vectors, particularly at the moderate and larger retrieval set sizes that are most useful for users' search and browsing.
ALX: Large Scale Matrix Factorization on TPUs
Dec 03, 2021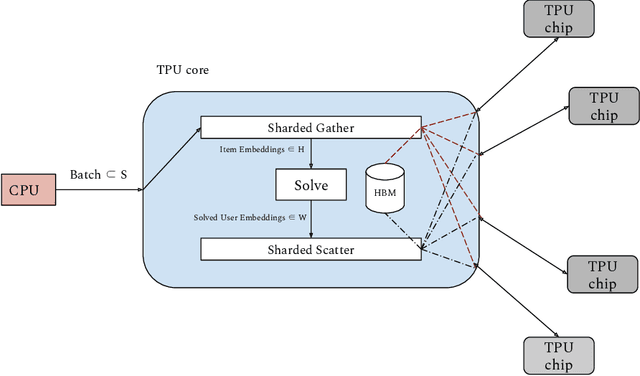


We present ALX, an open-source library for distributed matrix factorization using Alternating Least Squares, written in JAX. Our design allows for efficient use of the TPU architecture and scales well to matrix factorization problems of O(B) rows/columns by scaling the number of available TPU cores. In order to spur future research on large scale matrix factorization methods and to illustrate the scalability properties of our own implementation, we also built a real world web link prediction dataset called WebGraph. This dataset can be easily modeled as a matrix factorization problem. We created several variants of this dataset based on locality and sparsity properties of sub-graphs. The largest variant of WebGraph has around 365M nodes and training a single epoch finishes in about 20 minutes with 256 TPU cores. We include speed and performance numbers of ALX on all variants of WebGraph. Both the framework code and the dataset is open-sourced.
iALS++: Speeding up Matrix Factorization with Subspace Optimization
Oct 26, 2021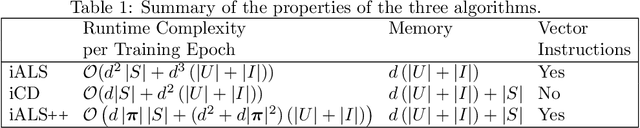
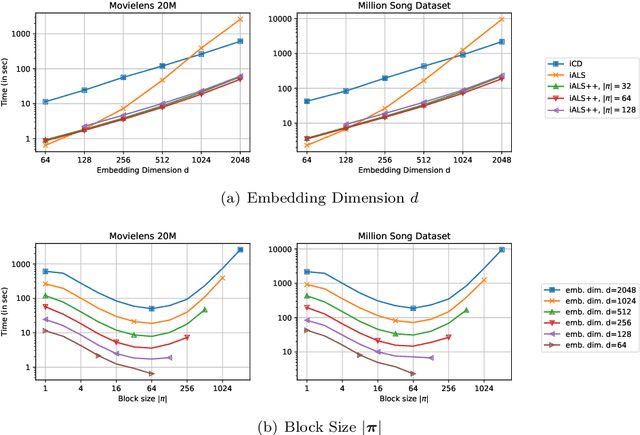

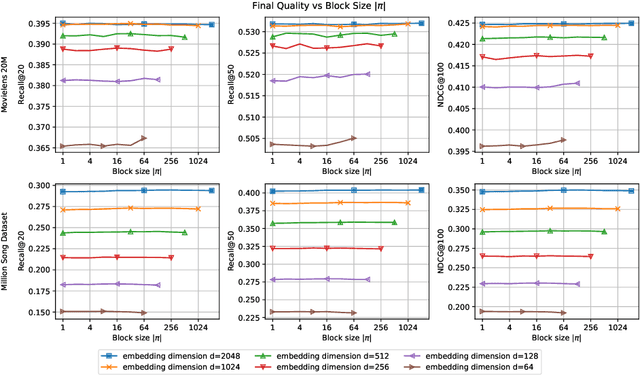
iALS is a popular algorithm for learning matrix factorization models from implicit feedback with alternating least squares. This algorithm was invented over a decade ago but still shows competitive quality compared to recent approaches like VAE, EASE, SLIM, or NCF. Due to a computational trick that avoids negative sampling, iALS is very efficient especially for large item catalogues. However, iALS does not scale well with large embedding dimensions, d, due to its cubic runtime dependency on d. Coordinate descent variations, iCD, have been proposed to lower the complexity to quadratic in d. In this work, we show that iCD approaches are not well suited for modern processors and can be an order of magnitude slower than a careful iALS implementation for small to mid scale embedding sizes (d ~ 100) and only perform better than iALS on large embeddings d ~ 1000. We propose a new solver iALS++ that combines the advantages of iALS in terms of vector processing with a low computational complexity as in iCD. iALS++ is an order of magnitude faster than iCD both for small and large embedding dimensions. It can solve benchmark problems like Movielens 20M or Million Song Dataset even for 1000 dimensional embedding vectors in a few minutes.
Revisiting the Performance of iALS on Item Recommendation Benchmarks
Oct 26, 2021
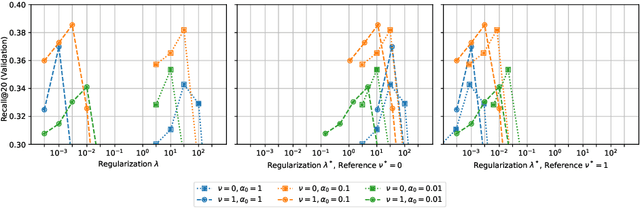


Matrix factorization learned by implicit alternating least squares (iALS) is a popular baseline in recommender system research publications. iALS is known to be one of the most computationally efficient and scalable collaborative filtering methods. However, recent studies suggest that its prediction quality is not competitive with the current state of the art, in particular autoencoders and other item-based collaborative filtering methods. In this work, we revisit the iALS algorithm and present a bag of tricks that we found useful when applying iALS. We revisit four well-studied benchmarks where iALS was reported to perform poorly and show that with proper tuning, iALS is highly competitive and outperforms any method on at least half of the comparisons. We hope that these high quality results together with iALS's known scalability spark new interest in applying and further improving this decade old technique.
Private Alternating Least Squares: Practical Private Matrix Completion with Tighter Rates
Jul 20, 2021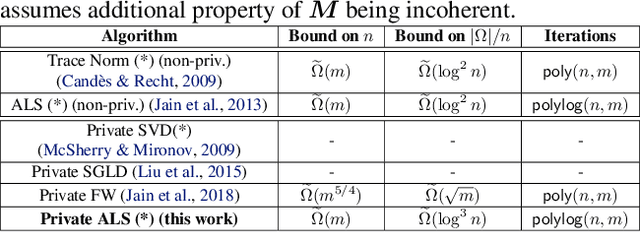
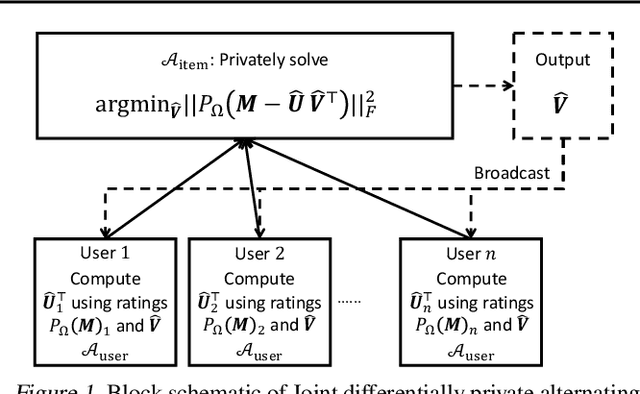
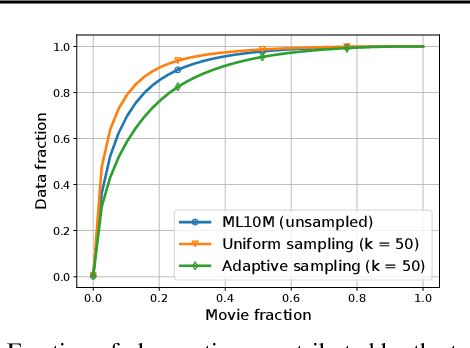
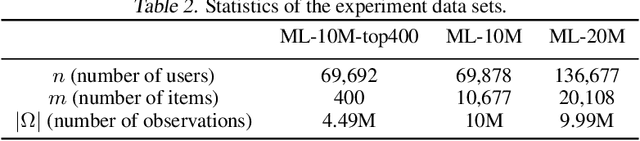
We study the problem of differentially private (DP) matrix completion under user-level privacy. We design a joint differentially private variant of the popular Alternating-Least-Squares (ALS) method that achieves: i) (nearly) optimal sample complexity for matrix completion (in terms of number of items, users), and ii) the best known privacy/utility trade-off both theoretically, as well as on benchmark data sets. In particular, we provide the first global convergence analysis of ALS with noise introduced to ensure DP, and show that, in comparison to the best known alternative (the Private Frank-Wolfe algorithm by Jain et al. (2018)), our error bounds scale significantly better with respect to the number of items and users, which is critical in practical problems. Extensive validation on standard benchmarks demonstrate that the algorithm, in combination with carefully designed sampling procedures, is significantly more accurate than existing techniques, thus promising to be the first practical DP embedding model.
Item Recommendation from Implicit Feedback
Jan 21, 2021
The task of item recommendation is to select the best items for a user from a large catalogue of items. Item recommenders are commonly trained from implicit feedback which consists of past actions that are positive only. Core challenges of item recommendation are (1) how to formulate a training objective from implicit feedback and (2) how to efficiently train models over a large item catalogue. This article provides an overview of item recommendation, its unique characteristics and some common approaches. It starts with an introduction to the problem and discusses different training objectives. The main body deals with learning algorithms and presents sampling based algorithms for general recommenders and more efficient algorithms for dot product models. Finally, the application of item recommenders for retrieval tasks is discussed.