 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Instrument Planning and Perception for Novel Measurements of Dynamic Phenomena
Sep 03, 2025Advancements in onboard computing mean remote sensing agents can employ state-of-the-art computer vision and machine learning at the edge. These capabilities can be leveraged to unlock new rare, transient, and pinpoint measurements of dynamic science phenomena. In this paper, we present an automated workflow that synthesizes the detection of these dynamic events in look-ahead satellite imagery with autonomous trajectory planning for a follow-up high-resolution sensor to obtain pinpoint measurements. We apply this workflow to the use case of observing volcanic plumes. We analyze classification approaches including traditional machine learning algorithms and convolutional neural networks. We present several trajectory planning algorithms that track the morphological features of a plume and integrate these algorithms with the classifiers. We show through simulation an order of magnitude increase in the utility return of the high-resolution instrument compared to baselines while maintaining efficient runtimes.
Demonstrating Onboard Inference for Earth Science Applications with Spectral Analysis Algorithms and Deep Learning
Aug 20, 2025



In partnership with Ubotica Technologies, the Jet Propulsion Laboratory is demonstrating state-of-the-art data analysis onboard CogniSAT-6/HAMMER (CS-6). CS-6 is a satellite with a visible and near infrared range hyperspectral instrument and neural network acceleration hardware. Performing data analysis at the edge (e.g. onboard) can enable new Earth science measurements and responses. We will demonstrate data analysis and inference onboard CS-6 for numerous applications using deep learning and spectral analysis algorithms.
Planning, scheduling, and execution on the Moon: the CADRE technology demonstration mission
Feb 20, 2025NASA's Cooperative Autonomous Distributed Robotic Exploration (CADRE) mission, slated for flight to the Moon's Reiner Gamma region in 2025/2026, is designed to demonstrate multi-agent autonomous exploration of the Lunar surface and sub-surface. A team of three robots and a base station will autonomously explore a region near the lander, collecting the data required for 3D reconstruction of the surface with no human input; and then autonomously perform distributed sensing with multi-static ground penetrating radars (GPR), driving in formation while performing coordinated radar soundings to create a map of the subsurface. At the core of CADRE's software architecture is a novel autonomous, distributed planning, scheduling, and execution (PS&E) system. The system coordinates the robots' activities, planning and executing tasks that require multiple robots' participation while ensuring that each individual robot's thermal and power resources stay within prescribed bounds, and respecting ground-prescribed sleep-wake cycles. The system uses a centralized-planning, distributed-execution paradigm, and a leader election mechanism ensures robustness to failures of individual agents. In this paper, we describe the architecture of CADRE's PS&E system; discuss its design rationale; and report on verification and validation (V&V) testing of the system on CADRE's hardware in preparation for deployment on the Moon.
Training Large ASR Encoders with Differential Privacy
Sep 21, 2024



Self-supervised learning (SSL) methods for large speech models have proven to be highly effective at ASR. With the interest in public deployment of large pre-trained models, there is a rising concern for unintended memorization and leakage of sensitive data points from the training data. In this paper, we apply differentially private (DP) pre-training to a SOTA Conformer-based encoder, and study its performance on a downstream ASR task assuming the fine-tuning data is public. This paper is the first to apply DP to SSL for ASR, investigating the DP noise tolerance of the BEST-RQ pre-training method. Notably, we introduce a novel variant of model pruning called gradient-based layer freezing that provides strong improvements in privacy-utility-compute trade-offs. Our approach yields a LibriSpeech test-clean/other WER (%) of 3.78/ 8.41 with ($10$, 1e^-9)-DP for extrapolation towards low dataset scales, and 2.81/ 5.89 with (10, 7.9e^-11)-DP for extrapolation towards high scales.
Using Unsupervised and Supervised Learning and Digital Twin for Deep Convective Ice Storm Classification
Sep 12, 2023Smart Ice Cloud Sensing (SMICES) is a small-sat concept in which a primary radar intelligently targets ice storms based on information collected by a lookahead radiometer. Critical to the intelligent targeting is accurate identification of storm/cloud types from eight bands of radiance collected by the radiometer. The cloud types of interest are: clear sky, thin cirrus, cirrus, rainy anvil, and convection core. We describe multi-step use of Machine Learning and Digital Twin of the Earth's atmosphere to derive such a classifier. First, a digital twin of Earth's atmosphere called a Weather Research Forecast (WRF) is used generate simulated lookahead radiometer data as well as deeper "science" hidden variables. The datasets simulate a tropical region over the Caribbean and a non-tropical region over the Atlantic coast of the United States. A K-means clustering over the scientific hidden variables was utilized by human experts to generate an automatic labelling of the data - mapping each physical data point to cloud types by scientists informed by mean/centroids of hidden variables of the clusters. Next, classifiers were trained with the inputs of the simulated radiometer data and its corresponding label. The classifiers of a random decision forest (RDF), support vector machine (SVM), Gaussian na\"ive bayes, feed forward artificial neural network (ANN), and a convolutional neural network (CNN) were trained. Over the tropical dataset, the best performing classifier was able to identify non-storm and storm clouds with over 80% accuracy in each class for a held-out test set. Over the non-tropical dataset, the best performing classifier was able to classify non-storm clouds with over 90% accuracy and storm clouds with over 40% accuracy. Additionally both sets of classifiers were shown to be resilient to instrument noise.
How to DP-fy ML: A Practical Guide to Machine Learning with Differential Privacy
Mar 02, 2023



ML models are ubiquitous in real world applications and are a constant focus of research. At the same time, the community has started to realize the importance of protecting the privacy of ML training data. Differential Privacy (DP) has become a gold standard for making formal statements about data anonymization. However, while some adoption of DP has happened in industry, attempts to apply DP to real world complex ML models are still few and far between. The adoption of DP is hindered by limited practical guidance of what DP protection entails, what privacy guarantees to aim for, and the difficulty of achieving good privacy-utility-computation trade-offs for ML models. Tricks for tuning and maximizing performance are scattered among papers or stored in the heads of practitioners. Furthermore, the literature seems to present conflicting evidence on how and whether to apply architectural adjustments and which components are "safe" to use with DP. This work is a self-contained guide that gives an in-depth overview of the field of DP ML and presents information about achieving the best possible DP ML model with rigorous privacy guarantees. Our target audience is both researchers and practitioners. Researchers interested in DP for ML will benefit from a clear overview of current advances and areas for improvement. We include theory-focused sections that highlight important topics such as privacy accounting and its assumptions, and convergence. For a practitioner, we provide a background in DP theory and a clear step-by-step guide for choosing an appropriate privacy definition and approach, implementing DP training, potentially updating the model architecture, and tuning hyperparameters. For both researchers and practitioners, consistently and fully reporting privacy guarantees is critical, and so we propose a set of specific best practices for stating guarantees.
Enabling Astronaut Self-Scheduling using a Robust Advanced Modelling and Scheduling system: an assessment during a Mars analogue mission
Jan 14, 2023


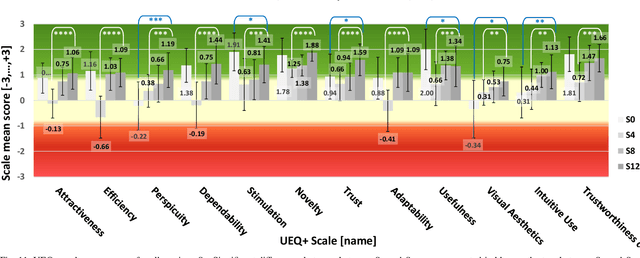
Human long duration exploration missions (LDEMs) raise a number of technological challenges. This paper addresses the question of the crew autonomy: as the distances increase, the communication delays and constraints tend to prevent the astronauts from being monitored and supported by a real time ground control. Eventually, future planetary missions will necessarily require a form of astronaut self-scheduling. We study the usage of a computer decision-support tool by a crew of analog astronauts, during a Mars simulation mission conducted at the Mars Desert Research Station (MDRS, Mars Society) in Utah. The proposed tool, called Romie, belongs to the new category of Robust Advanced Modelling and Scheduling (RAMS) systems. It allows the crew members (i) to visually model their scientific objectives and constraints, (ii) to compute near-optimal operational schedules while taking uncertainty into account, (iii) to monitor the execution of past and current activities, and (iv) to modify scientific objectives/constraints w.r.t. unforeseen events and opportunistic science. In this study, we empirically measure how the astronauts, who are novice planners, perform at using such a tool when self-scheduling under the realistic assumptions of a simulated Martian planetary habitat.
Temporal Multimodal Multivariate Learning
Jun 14, 2022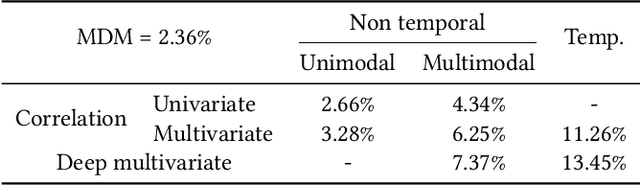
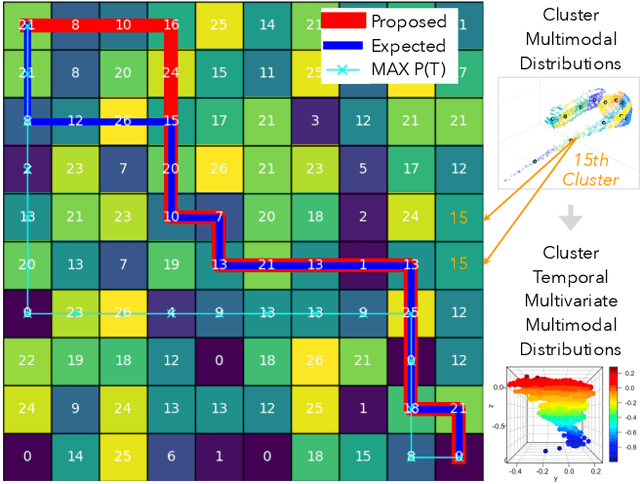
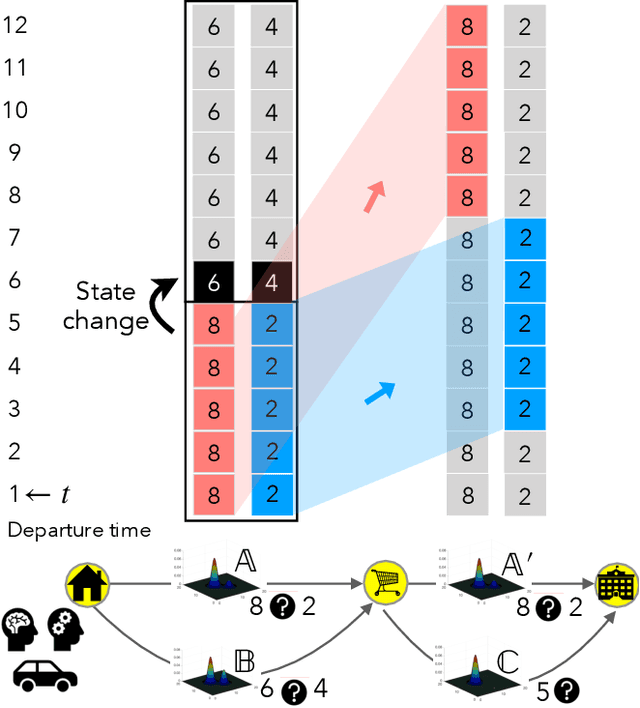
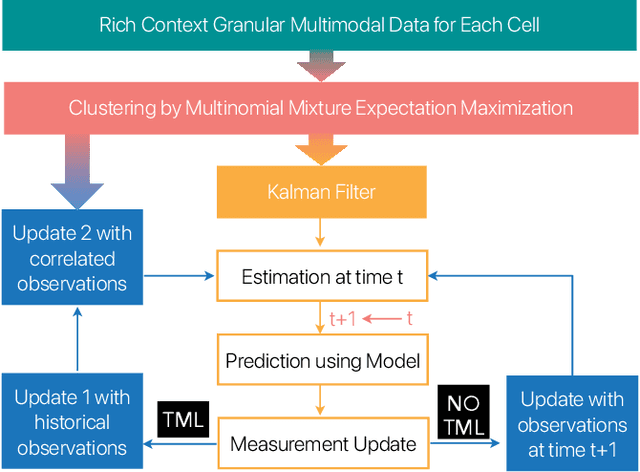
We introduce temporal multimodal multivariate learning, a new family of decision making models that can indirectly learn and transfer online information from simultaneous observations of a probability distribution with more than one peak or more than one outcome variable from one time stage to another. We approximate the posterior by sequentially removing additional uncertainties across different variables and time, based on data-physics driven correlation, to address a broader class of challenging time-dependent decision-making problems under uncertainty. Extensive experiments on real-world datasets ( i.e., urban traffic data and hurricane ensemble forecasting data) demonstrate the superior performance of the proposed targeted decision-making over the state-of-the-art baseline prediction methods across various settings.
Detecting Unintended Memorization in Language-Model-Fused ASR
Apr 20, 2022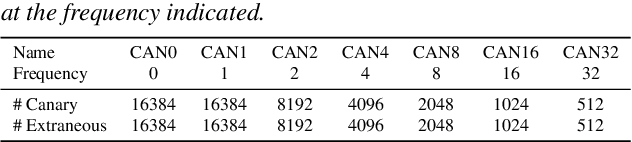
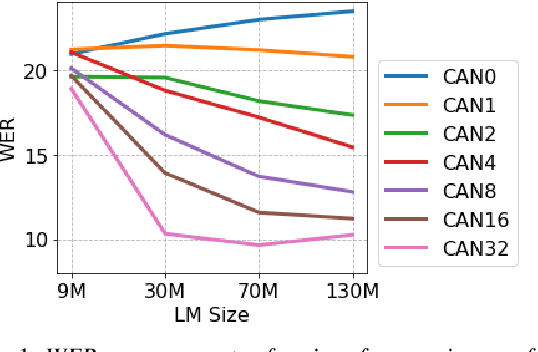
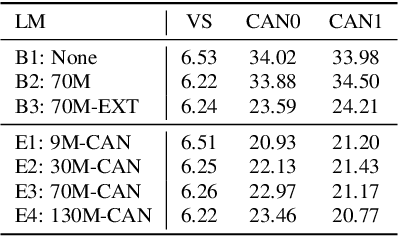
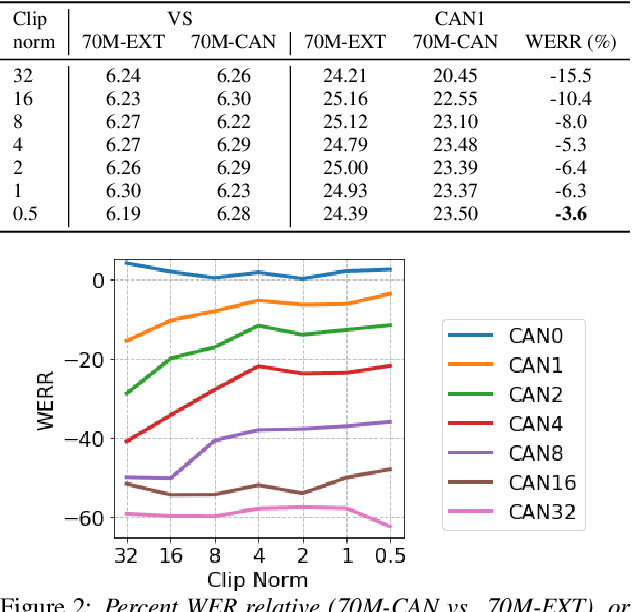
End-to-end (E2E) models are often being accompanied by language models (LMs) via shallow fusion for boosting their overall quality as well as recognition of rare words. At the same time, several prior works show that LMs are susceptible to unintentionally memorizing rare or unique sequences in the training data. In this work, we design a framework for detecting memorization of random textual sequences (which we call canaries) in the LM training data when one has only black-box (query) access to LM-fused speech recognizer, as opposed to direct access to the LM. On a production-grade Conformer RNN-T E2E model fused with a Transformer LM, we show that detecting memorization of singly-occurring canaries from the LM training data of 300M examples is possible. Motivated to protect privacy, we also show that such memorization gets significantly reduced by per-example gradient-clipped LM training without compromising overall quality.
Toward Training at ImageNet Scale with Differential Privacy
Feb 09, 2022
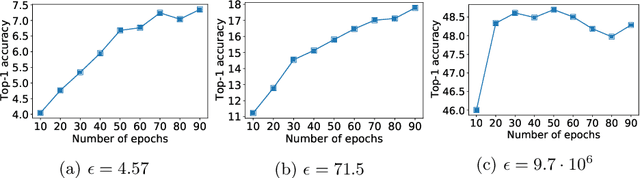
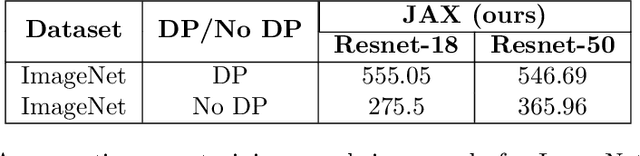
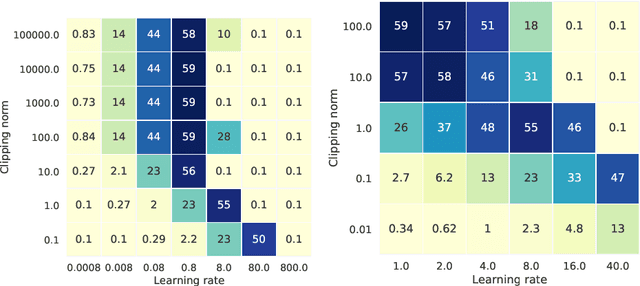
Differential privacy (DP) is the de facto standard for training machine learning (ML) models, including neural networks, while ensuring the privacy of individual examples in the training set. Despite a rich literature on how to train ML models with differential privacy, it remains extremely challenging to train real-life, large neural networks with both reasonable accuracy and privacy. We set out to investigate how to do this, using ImageNet image classification as a poster example of an ML task that is very challenging to resolve accurately with DP right now. This paper shares initial lessons from our effort, in the hope that it will inspire and inform other researchers to explore DP training at scale. We show approaches that help make DP training faster, as well as model types and settings of the training process that tend to work better in the DP setting. Combined, the methods we discuss let us train a Resnet-18 with DP to $47.9\%$ accuracy and privacy parameters $\epsilon = 10, \delta = 10^{-6}$. This is a significant improvement over "naive" DP training of ImageNet models, but a far cry from the $75\%$ accuracy that can be obtained by the same network without privacy. The model we use was pretrained on the Places365 data set as a starting point. We share our code at https://github.com/google-research/dp-imagenet, calling for others to build upon this new baseline to further improve DP at scale.