 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuousBench: Can Differentially Private Synthetic Text Improve Capabilities?
Jun 01, 2026Differentially private (DP) text synthesis promises to unlock sensitive corpora for model training, but it remains unclear whether DP synthetic data transmits genuinely new knowledge and capabilities present only in those corpora. This is because existing evaluations rely on tasks that are nearly solvable without training, so strong benchmark performance does not establish that DP synthesis can substitute original data access. Thus, we introduce ContinuousBench, a continuously and automatically-regenerated benchmark that measures capability gain from DP synthetic text. Each quarter, a new release pairs a never-before-seen training corpus with a derived QA set, constructed to be: (1) unsolvable sans-corpus; and (2) learnable under DP, as the tested knowledge is supported by hundreds of independent records. Researchers produce DP synthetic data from the training corpus and run our standardized training and evaluation harness on their synthetic data to measure gains. We instantiate two tracks: Geminon, a procedurally-generated dataset about fictional creatures; and News, a stream of newly crawled public news articles. Although standard benchmarks are nearly saturated, on ContinuousBench we find that non-private synthesis transfers substantial knowledge from the original corpus, while state-of-the-art DP synthesis methods generally fail to do so, even at $\varepsilon=100$.
Engineering Robustness into Personal Agents with the AI Workflow Store
May 11, 2026The dominant paradigm for AI agents is an "on-the-fly" loop in which agents synthesize plans and execute actions within seconds or minutes in response to user prompts. We argue that this paradigm short-circuits disciplined software engineering (SE) processes -- iterative design, rigorous testing, adversarial evaluation, staged deployment, and more -- that have delivered the (relatively) reliable and secure systems we use today. By focusing on rapid, real-time synthesis, are AI agents effectively delivering users improvised prototypes rather than systems fit for high-stakes scenarios in which users may unwittingly apply them? This paper argues for the need to integrate rigorous SE processes into the agentic loop to produce production-grade, hardened, and deterministically-constrained agent *workflows* that substantially outperform the potentially brittle and vulnerable results of on-the-fly synthesis. Doing so may require extra compute and time, and if so, we must amortize the cost of rigor through reuse across a broad user community. We envision an *AI Workflow Store* that consists of hardened and reusable workflows that agents can invoke with far greater reliability and security than improvised tool chains. We outline the research challenges of this vision, which stem from a broader flexibility-robustness tension that we argue requires moving beyond the ``on-the-fly'' paradigm to navigate effectively.
Packing Privacy Budget Efficiently
Dec 26, 2022



Machine learning (ML) models can leak information about users, and differential privacy (DP) provides a rigorous way to bound that leakage under a given budget. This DP budget can be regarded as a new type of compute resource in workloads of multiple ML models training on user data. Once it is used, the DP budget is forever consumed. Therefore, it is crucial to allocate it most efficiently to train as many models as possible. This paper presents the scheduler for privacy that optimizes for efficiency. We formulate privacy scheduling as a new type of multidimensional knapsack problem, called privacy knapsack, which maximizes DP budget efficiency. We show that privacy knapsack is NP-hard, hence practical algorithms are necessarily approximate. We develop an approximation algorithm for privacy knapsack, DPK, and evaluate it on microbenchmarks and on a new, synthetic private-ML workload we developed from the Alibaba ML cluster trace. We show that DPK: (1) often approaches the efficiency-optimal schedule, (2) consistently schedules more tasks compared to a state-of-the-art privacy scheduling algorithm that focused on fairness (1.3-1.7x in Alibaba, 1.0-2.6x in microbenchmarks), but (3) sacrifices some level of fairness for efficiency. Therefore, using DPK, DP ML operators should be able to train more models on the same amount of user data while offering the same privacy guarantee to their users.
How to Combine Membership-Inference Attacks on Multiple Updated Models
May 12, 2022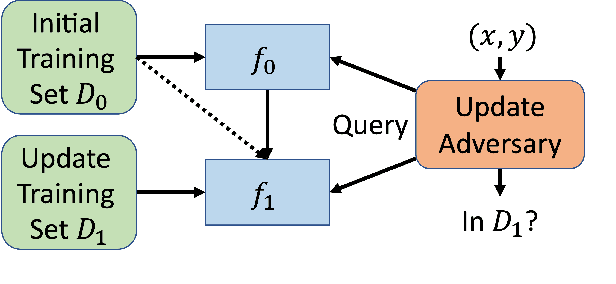
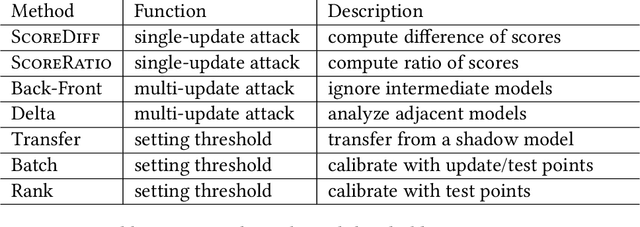
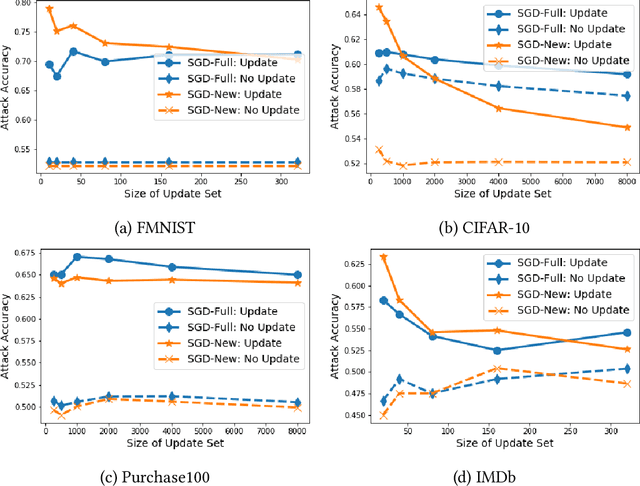

A large body of research has shown that machine learning models are vulnerable to membership inference (MI) attacks that violate the privacy of the participants in the training data. Most MI research focuses on the case of a single standalone model, while production machine-learning platforms often update models over time, on data that often shifts in distribution, giving the attacker more information. This paper proposes new attacks that take advantage of one or more model updates to improve MI. A key part of our approach is to leverage rich information from standalone MI attacks mounted separately against the original and updated models, and to combine this information in specific ways to improve attack effectiveness. We propose a set of combination functions and tuning methods for each, and present both analytical and quantitative justification for various options. Our results on four public datasets show that our attacks are effective at using update information to give the adversary a significant advantage over attacks on standalone models, but also compared to a prior MI attack that takes advantage of model updates in a related machine-unlearning setting. We perform the first measurements of the impact of distribution shift on MI attacks with model updates, and show that a more drastic distribution shift results in significantly higher MI risk than a gradual shift. Our code is available at https://www.github.com/stanleykywu/model-updates.
Toward Training at ImageNet Scale with Differential Privacy
Feb 09, 2022
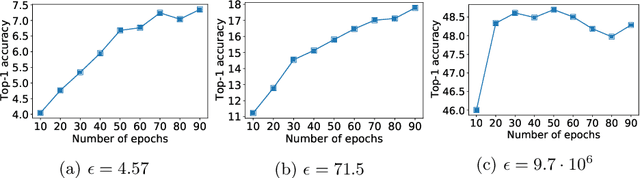
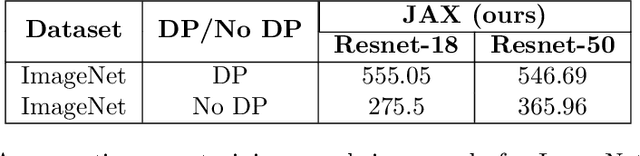
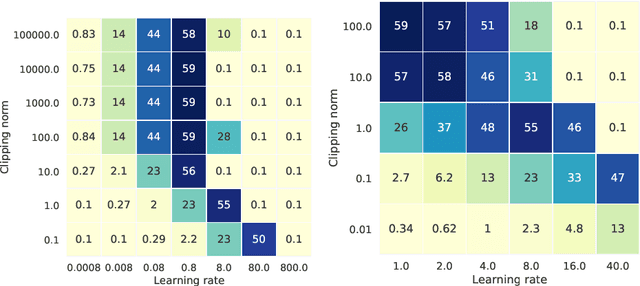
Differential privacy (DP) is the de facto standard for training machine learning (ML) models, including neural networks, while ensuring the privacy of individual examples in the training set. Despite a rich literature on how to train ML models with differential privacy, it remains extremely challenging to train real-life, large neural networks with both reasonable accuracy and privacy. We set out to investigate how to do this, using ImageNet image classification as a poster example of an ML task that is very challenging to resolve accurately with DP right now. This paper shares initial lessons from our effort, in the hope that it will inspire and inform other researchers to explore DP training at scale. We show approaches that help make DP training faster, as well as model types and settings of the training process that tend to work better in the DP setting. Combined, the methods we discuss let us train a Resnet-18 with DP to $47.9\%$ accuracy and privacy parameters $\epsilon = 10, \delta = 10^{-6}$. This is a significant improvement over "naive" DP training of ImageNet models, but a far cry from the $75\%$ accuracy that can be obtained by the same network without privacy. The model we use was pretrained on the Places365 data set as a starting point. We share our code at https://github.com/google-research/dp-imagenet, calling for others to build upon this new baseline to further improve DP at scale.
Privacy Budget Scheduling
Jun 29, 2021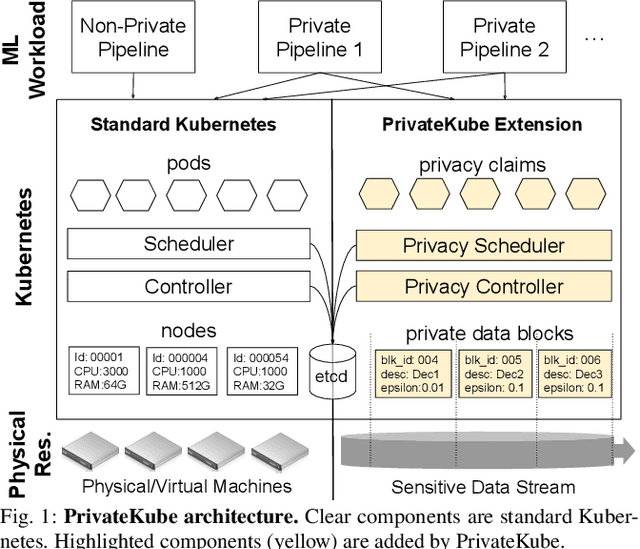
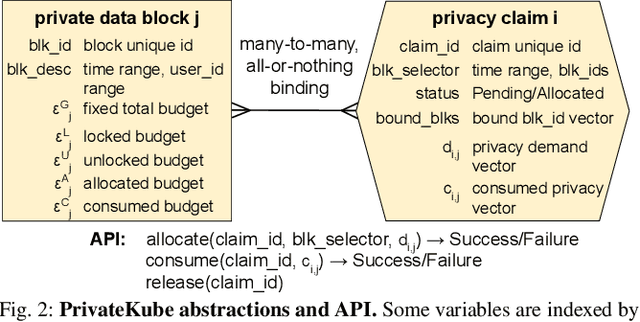
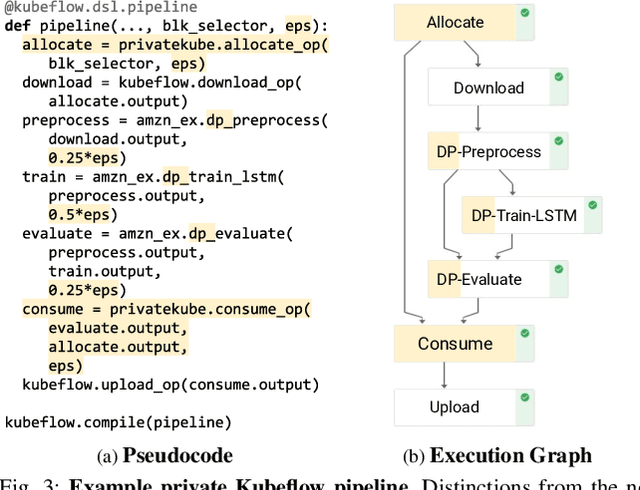
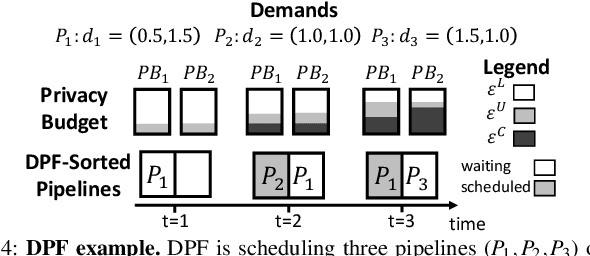
Machine learning (ML) models trained on personal data have been shown to leak information about users. Differential privacy (DP) enables model training with a guaranteed bound on this leakage. Each new model trained with DP increases the bound on data leakage and can be seen as consuming part of a global privacy budget that should not be exceeded. This budget is a scarce resource that must be carefully managed to maximize the number of successfully trained models. We describe PrivateKube, an extension to the popular Kubernetes datacenter orchestrator that adds privacy as a new type of resource to be managed alongside other traditional compute resources, such as CPU, GPU, and memory. The abstractions we design for the privacy resource mirror those defined by Kubernetes for traditional resources, but there are also major differences. For example, traditional compute resources are replenishable while privacy is not: a CPU can be regained after a model finishes execution while privacy budget cannot. This distinction forces a re-design of the scheduler. We present DPF (Dominant Private Block Fairness) -- a variant of the popular Dominant Resource Fairness (DRF) algorithm -- that is geared toward the non-replenishable privacy resource but enjoys similar theoretical properties as DRF. We evaluate PrivateKube and DPF on microbenchmarks and an ML workload on Amazon Reviews data. Compared to existing baselines, DPF allows training more models under the same global privacy guarantee. This is especially true for DPF over R\'enyi DP, a highly composable form of DP.
Pythia: Grammar-Based Fuzzing of REST APIs with Coverage-guided Feedback and Learning-based Mutations
May 23, 2020
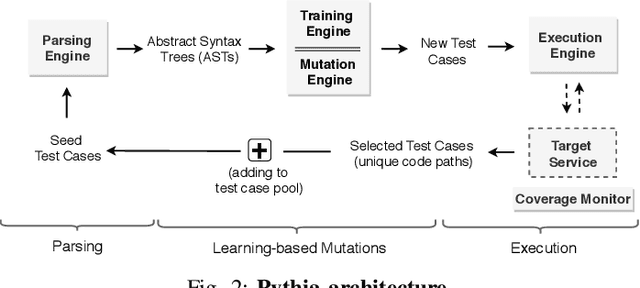

This paper introduces Pythia, the first fuzzer that augments grammar-based fuzzing with coverage-guided feedback and a learning-based mutation strategy for stateful REST API fuzzing. Pythia uses a statistical model to learn common usage patterns of a target REST API from structurally valid seed inputs. It then generates learning-based mutations by injecting a small amount of noise deviating from common usage patterns while still maintaining syntactic validity. Pythia's mutation strategy helps generate grammatically valid test cases and coverage-guided feedback helps prioritize the test cases that are more likely to find bugs. We present experimental evaluation on three production-scale, open-source cloud services showing that Pythia outperforms prior approaches both in code coverage and new bugs found. Using Pythia, we found 29 new bugs which we are in the process of reporting to the respective service owners.
Privacy Accounting and Quality Control in the Sage Differentially Private ML Platform
Sep 06, 2019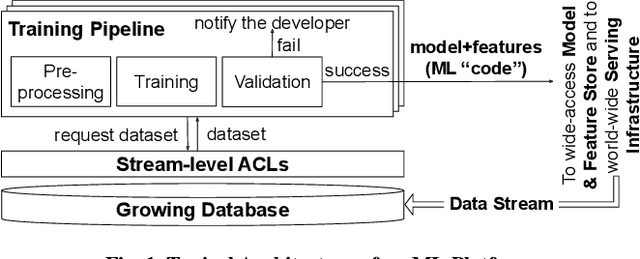
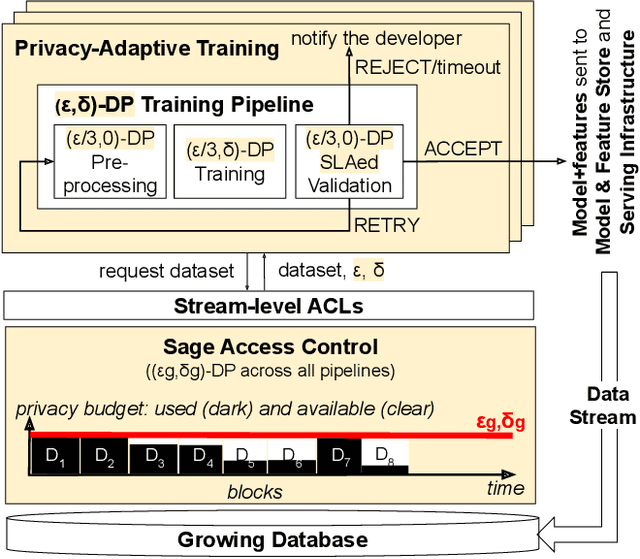
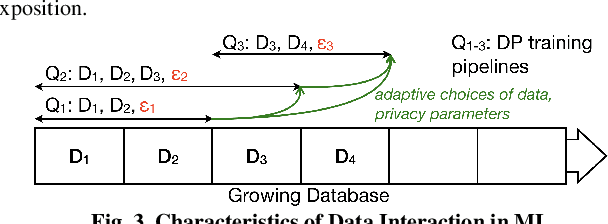

Companies increasingly expose machine learning (ML) models trained over sensitive user data to untrusted domains, such as end-user devices and wide-access model stores. We present Sage, a differentially private (DP) ML platform that bounds the cumulative leakage of training data through models. Sage builds upon the rich literature on DP ML algorithms and contributes pragmatic solutions to two of the most pressing systems challenges of global DP: running out of privacy budget and the privacy-utility tradeoff. To address the former, we develop block composition, a new privacy loss accounting method that leverages the growing database regime of ML workloads to keep training models endlessly on a sensitive data stream while enforcing a global DP guarantee for the stream. To address the latter, we develop privacy-adaptive training, a process that trains a model on growing amounts of data and/or with increasing privacy parameters until, with high probability, the model meets developer-configured quality criteria. They illustrate how a systems focus on characteristics of ML workloads enables pragmatic solutions that are not apparent when one focuses on individual algorithms, as most DP ML literature does.
Certified Robustness to Adversarial Examples with Differential Privacy
Oct 07, 2018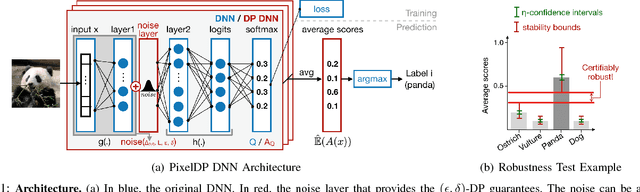
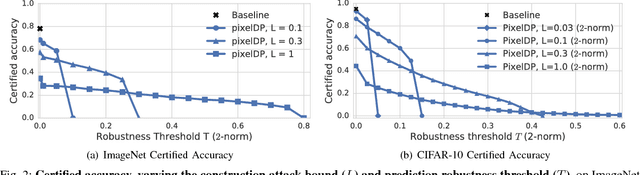
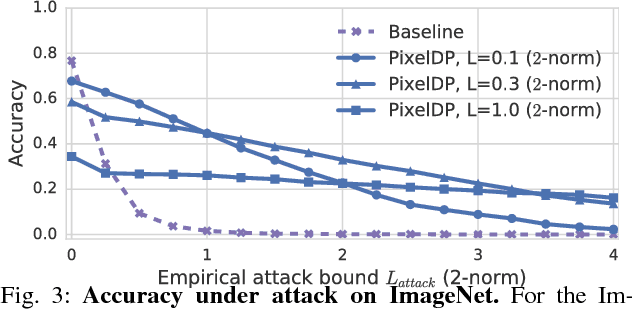
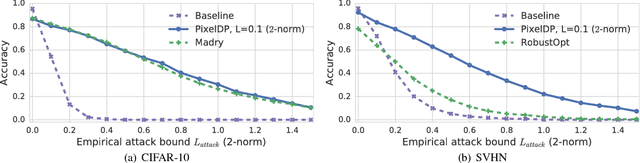
Adversarial examples that fool machine learning models, particularly deep neural networks, have been a topic of intense research interest, with attacks and defenses being developed in a tight back-and-forth. Most past defenses are best effort and have been shown to be vulnerable to sophisticated attacks. Recently a set of certified defenses have been introduced, which provide guarantees of robustness to norm-bounded attacks, but they either do not scale to large datasets or are limited in the types of models they can support. This paper presents the first certified defense that both scales to large networks and datasets (such as Google's Inception network for ImageNet) and applies broadly to arbitrary model types. Our defense, called PixelDP, is based on a novel connection between robustness against adversarial examples and differential privacy, a cryptographically-inspired formalism, that provides a rigorous, generic, and flexible foundation for defense.