 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate and Stable Test-Time Adaptation with Differential Privacy
Jun 01, 2026Test-time adaptation (TTA) can reduce error on new and different data by updating the model on these inputs during inference. However, these updates raise the issue of privacy w.r.t. the testing data, because the model parameters now depend on all past inputs. To control this privacy risk, we cast multiple popular TTA methods (Tent, EATA, SAR, DeYO, and COME) into differential privacy (DP) forms that apply per-sample gradient clipping and Gaussian noise for all updates. On ImageNet-C, our DP-TTA methods provide adequate privacy at small cost to accuracy, and in the low-privacy regime the clipping mechanism of DP can even improve the accuracy and stability of adaptation in the continual setting. These improvements to privacy and accuracy come at only modest computational overhead. These first results on private TTA raise awareness of the issue, inform the development of more private test-time updates, and identify per-sample clipping as an effective technique for improving the accuracy and stability of adaptation.
Fast Optimization of Weighted Sparse Decision Trees for use in Optimal Treatment Regimes and Optimal Policy Design
Oct 13, 2022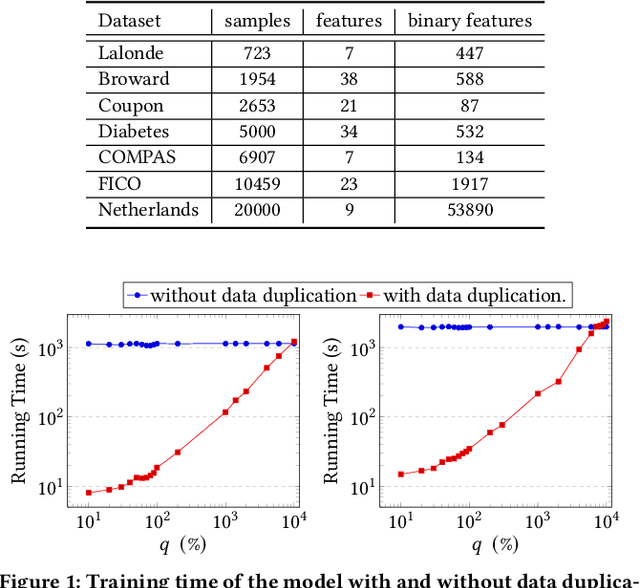
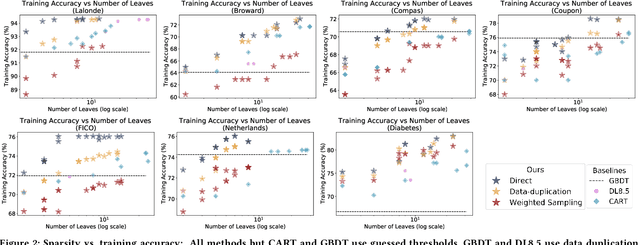
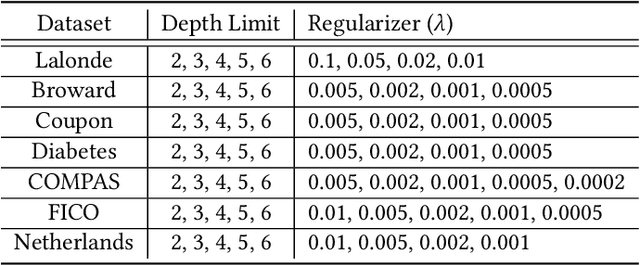

Sparse decision trees are one of the most common forms of interpretable models. While recent advances have produced algorithms that fully optimize sparse decision trees for prediction, that work does not address policy design, because the algorithms cannot handle weighted data samples. Specifically, they rely on the discreteness of the loss function, which means that real-valued weights cannot be directly used. For example, none of the existing techniques produce policies that incorporate inverse propensity weighting on individual data points. We present three algorithms for efficient sparse weighted decision tree optimization. The first approach directly optimizes the weighted loss function; however, it tends to be computationally inefficient for large datasets. Our second approach, which scales more efficiently, transforms weights to integer values and uses data duplication to transform the weighted decision tree optimization problem into an unweighted (but larger) counterpart. Our third algorithm, which scales to much larger datasets, uses a randomized procedure that samples each data point with a probability proportional to its weight. We present theoretical bounds on the error of the two fast methods and show experimentally that these methods can be two orders of magnitude faster than the direct optimization of the weighted loss, without losing significant accuracy.
Measuring the Effect of Training Data on Deep Learning Predictions via Randomized Experiments
Jun 20, 2022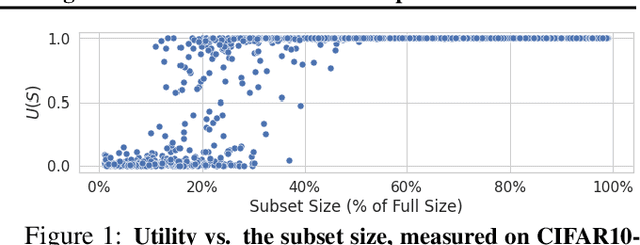
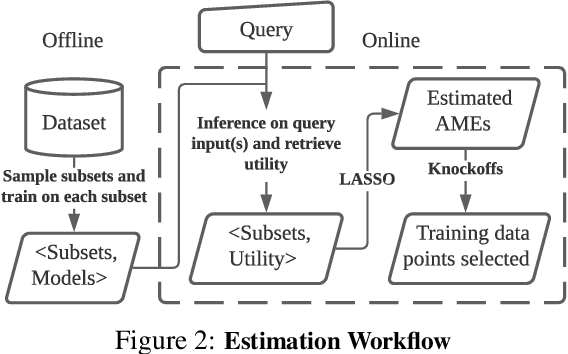

We develop a new, principled algorithm for estimating the contribution of training data points to the behavior of a deep learning model, such as a specific prediction it makes. Our algorithm estimates the AME, a quantity that measures the expected (average) marginal effect of adding a data point to a subset of the training data, sampled from a given distribution. When subsets are sampled from the uniform distribution, the AME reduces to the well-known Shapley value. Our approach is inspired by causal inference and randomized experiments: we sample different subsets of the training data to train multiple submodels, and evaluate each submodel's behavior. We then use a LASSO regression to jointly estimate the AME of each data point, based on the subset compositions. Under sparsity assumptions ($k \ll N$ datapoints have large AME), our estimator requires only $O(k\log N)$ randomized submodel trainings, improving upon the best prior Shapley value estimators.
Privacy Accounting and Quality Control in the Sage Differentially Private ML Platform
Sep 06, 2019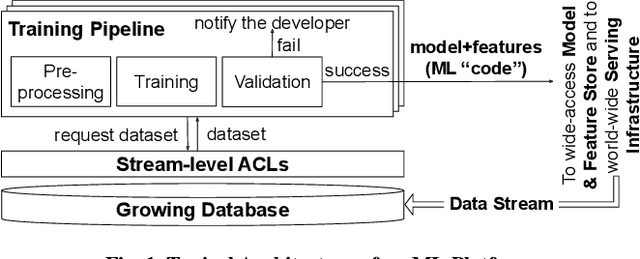
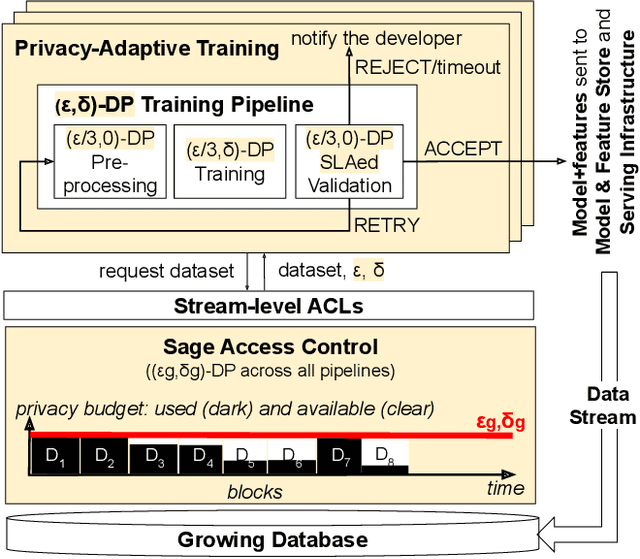
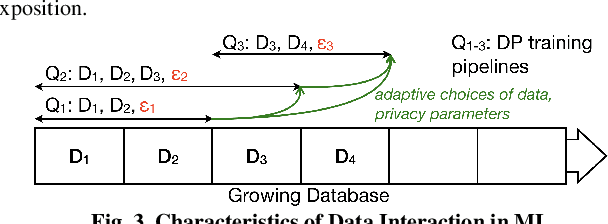

Companies increasingly expose machine learning (ML) models trained over sensitive user data to untrusted domains, such as end-user devices and wide-access model stores. We present Sage, a differentially private (DP) ML platform that bounds the cumulative leakage of training data through models. Sage builds upon the rich literature on DP ML algorithms and contributes pragmatic solutions to two of the most pressing systems challenges of global DP: running out of privacy budget and the privacy-utility tradeoff. To address the former, we develop block composition, a new privacy loss accounting method that leverages the growing database regime of ML workloads to keep training models endlessly on a sensitive data stream while enforcing a global DP guarantee for the stream. To address the latter, we develop privacy-adaptive training, a process that trains a model on growing amounts of data and/or with increasing privacy parameters until, with high probability, the model meets developer-configured quality criteria. They illustrate how a systems focus on characteristics of ML workloads enables pragmatic solutions that are not apparent when one focuses on individual algorithms, as most DP ML literature does.
Certified Robustness to Adversarial Examples with Differential Privacy
Oct 07, 2018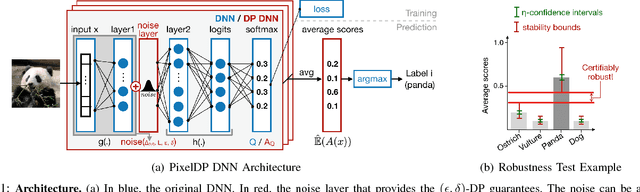
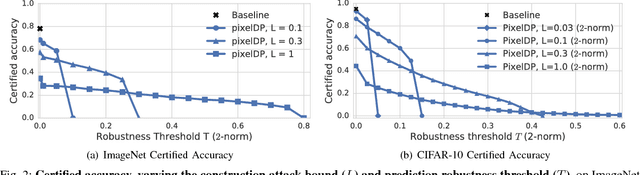
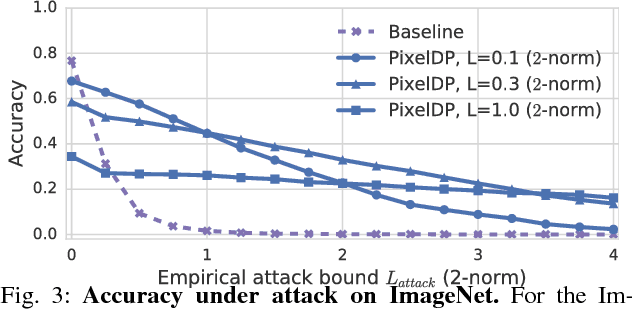
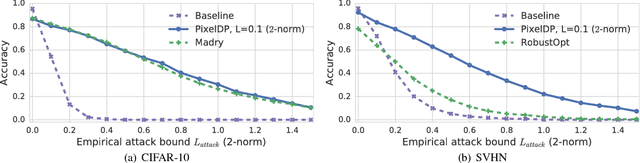
Adversarial examples that fool machine learning models, particularly deep neural networks, have been a topic of intense research interest, with attacks and defenses being developed in a tight back-and-forth. Most past defenses are best effort and have been shown to be vulnerable to sophisticated attacks. Recently a set of certified defenses have been introduced, which provide guarantees of robustness to norm-bounded attacks, but they either do not scale to large datasets or are limited in the types of models they can support. This paper presents the first certified defense that both scales to large networks and datasets (such as Google's Inception network for ImageNet) and applies broadly to arbitrary model types. Our defense, called PixelDP, is based on a novel connection between robustness against adversarial examples and differential privacy, a cryptographically-inspired formalism, that provides a rigorous, generic, and flexible foundation for defense.