 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Rashomon Effect for Visualizing High-Dimensional Data
Apr 01, 2026Dimension reduction (DR) is inherently non-unique: multiple embeddings can preserve the structure of high-dimensional data equally well while differing in layout or geometry. In this paper, we formally define the Rashomon set for DR -- the collection of `good' embedding -- and show how embracing this multiplicity leads to more powerful and trustworthy representations. Specifically, we pursue three goals. First, we introduce PCA-informed alignment to steer embeddings toward principal components, making axes interpretable without distorting local neighborhoods. Second, we design concept-alignment regularization that aligns an embedding dimension with external knowledge, such as class labels or user-defined concepts. Third, we propose a method to extract common knowledge across the Rashomon set by identifying trustworthy and persistent nearest-neighbor relationships, which we use to construct refined embeddings with improved local structure while preserving global relationships. By moving beyond a single embedding and leveraging the Rashomon set, we provide a flexible framework for building interpretable, robust, and goal-aligned visualizations.
REALITrees: Rashomon Ensemble Active Learning for Interpretable Trees
Mar 24, 2026Active learning reduces labeling costs by selecting samples that maximize information gain. A dominant framework, Query-by-Committee (QBC), typically relies on perturbation-based diversity by inducing model disagreement through random feature subsetting or data blinding. While this approximates one notion of epistemic uncertainty, it sacrifices direct characterization of the plausible hypothesis space. We propose the complementary approach: Rashomon Ensembled Active Learning (REAL) which constructs a committee by exhaustively enumerating the Rashomon Set of all near-optimal models. To address functional redundancy within this set, we adopt a PAC-Bayesian framework using a Gibbs posterior to weight committee members by their empirical risk. Leveraging recent algorithmic advances, we exactly enumerate this set for the class of sparse decision trees. Across synthetic and established active learning baselines, REAL outperforms randomized ensembles, particularly in moderately noisy environments where it strategically leverages expanded model multiplicity to achieve faster convergence.
Resolving Predictive Multiplicity for the Rashomon Set
Jan 14, 2026The existence of multiple, equally accurate models for a given predictive task leads to predictive multiplicity, where a ``Rashomon set'' of models achieve similar accuracy but diverges in their individual predictions. This inconsistency undermines trust in high-stakes applications where we want consistent predictions. We propose three approaches to reduce inconsistency among predictions for the members of the Rashomon set. The first approach is \textbf{outlier correction}. An outlier has a label that none of the good models are capable of predicting correctly. Outliers can cause the Rashomon set to have high variance predictions in a local area, so fixing them can lower variance. Our second approach is local patching. In a local region around a test point, models may disagree with each other because some of them are biased. We can detect and fix such biases using a validation set, which also reduces multiplicity. Our third approach is pairwise reconciliation, where we find pairs of models that disagree on a region around the test point. We modify predictions that disagree, making them less biased. These three approaches can be used together or separately, and they each have distinct advantages. The reconciled predictions can then be distilled into a single interpretable model for real-world deployment. In experiments across multiple datasets, our methods reduce disagreement metrics while maintaining competitive accuracy.
AutoSchA: Automatic Hierarchical Music Representations via Multi-Relational Node Isolation
Dec 20, 2025Hierarchical representations provide powerful and principled approaches for analyzing many musical genres. Such representations have been broadly studied in music theory, for instance via Schenkerian analysis (SchA). Hierarchical music analyses, however, are highly cost-intensive; the analysis of a single piece of music requires a great deal of time and effort from trained experts. The representation of hierarchical analyses in a computer-readable format is a further challenge. Given recent developments in hierarchical deep learning and increasing quantities of computer-readable data, there is great promise in extending such work for an automatic hierarchical representation framework. This paper thus introduces a novel approach, AutoSchA, which extends recent developments in graph neural networks (GNNs) for hierarchical music analysis. AutoSchA features three key contributions: 1) a new graph learning framework for hierarchical music representation, 2) a new graph pooling mechanism based on node isolation that directly optimizes learned pooling assignments, and 3) a state-of-the-art architecture that integrates such developments for automatic hierarchical music analysis. We show, in a suite of experiments, that AutoSchA performs comparably to human experts when analyzing Baroque fugue subjects.
NodMAISI: Nodule-Oriented Medical AI for Synthetic Imaging
Dec 19, 2025Objective: Although medical imaging datasets are increasingly available, abnormal and annotation-intensive findings critical to lung cancer screening, particularly small pulmonary nodules, remain underrepresented and inconsistently curated. Methods: We introduce NodMAISI, an anatomically constrained, nodule-oriented CT synthesis and augmentation framework trained on a unified multi-source cohort (7,042 patients, 8,841 CTs, 14,444 nodules). The framework integrates: (i) a standardized curation and annotation pipeline linking each CT with organ masks and nodule-level annotations, (ii) a ControlNet-conditioned rectified-flow generator built on MAISI-v2's foundational blocks to enforce anatomy- and lesion-consistent synthesis, and (iii) lesion-aware augmentation that perturbs nodule masks (controlled shrinkage) while preserving surrounding anatomy to generate paired CT variants. Results: Across six public test datasets, NodMAISI improved distributional fidelity relative to MAISI-v2 (real-to-synthetic FID range 1.18 to 2.99 vs 1.69 to 5.21). In lesion detectability analysis using a MONAI nodule detector, NodMAISI substantially increased average sensitivity and more closely matched clinical scans (IMD-CT: 0.69 vs 0.39; DLCS24: 0.63 vs 0.20), with the largest gains for sub-centimeter nodules where MAISI-v2 frequently failed to reproduce the conditioned lesion. In downstream nodule-level malignancy classification trained on LUNA25 and externally evaluated on LUNA16, LNDbv4, and DLCS24, NodMAISI augmentation improved AUC by 0.07 to 0.11 at <=20% clinical data and by 0.12 to 0.21 at 10%, consistently narrowing the performance gap under data scarcity.
It's LIT! Reliability-Optimized LLMs with Inspectable Tools
Nov 18, 2025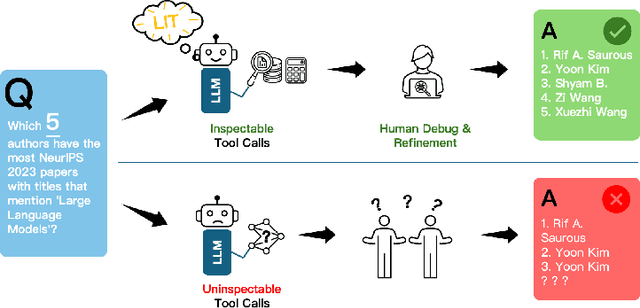
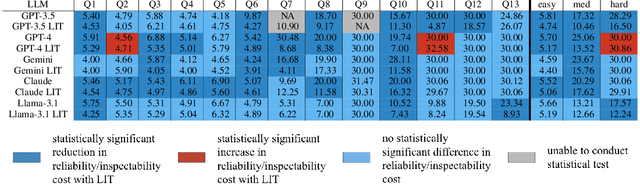
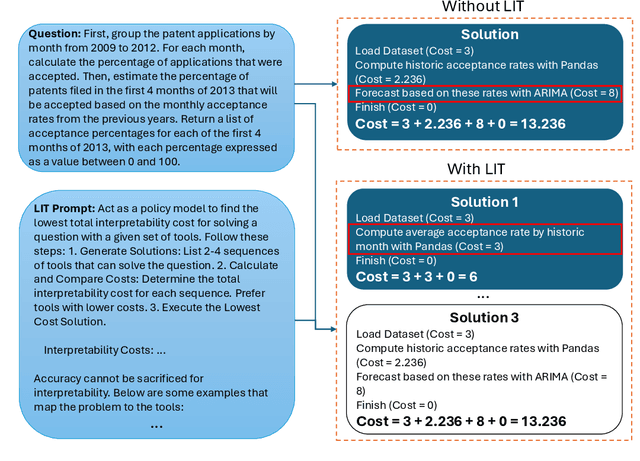
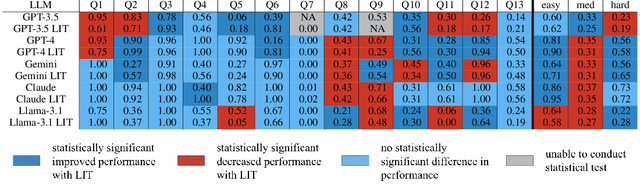
Large language models (LLMs) have exhibited remarkable capabilities across various domains. The ability to call external tools further expands their capability to handle real-world tasks. However, LLMs often follow an opaque reasoning process, which limits their usefulness in high-stakes domains where solutions need to be trustworthy to end users. LLMs can choose solutions that are unreliable and difficult to troubleshoot, even if better options are available. We address this issue by forcing LLMs to use external -- more reliable -- tools to solve problems when possible. We present a framework built on the tool-calling capabilities of existing LLMs to enable them to select the most reliable and easy-to-troubleshoot solution path, which may involve multiple sequential tool calls. We refer to this framework as LIT (LLMs with Inspectable Tools). In order to support LIT, we introduce a new and challenging benchmark dataset of 1,300 questions and a customizable set of reliability cost functions associated with a collection of specialized tools. These cost functions summarize how reliable each tool is and how easy it is to troubleshoot. For instance, a calculator is reliable across domains, whereas a linear prediction model is not reliable if there is distribution shift, but it is easy to troubleshoot. A tool that constructs a random forest is neither reliable nor easy to troubleshoot. These tools interact with the Harvard USPTO Patent Dataset and a new dataset of NeurIPS 2023 papers to solve mathematical, coding, and modeling problems of varying difficulty levels. We demonstrate that LLMs can achieve more reliable and informed problem-solving while maintaining task performance using our framework.
Doctor Rashomon and the UNIVERSE of Madness: Variable Importance with Unobserved Confounding and the Rashomon Effect
Oct 14, 2025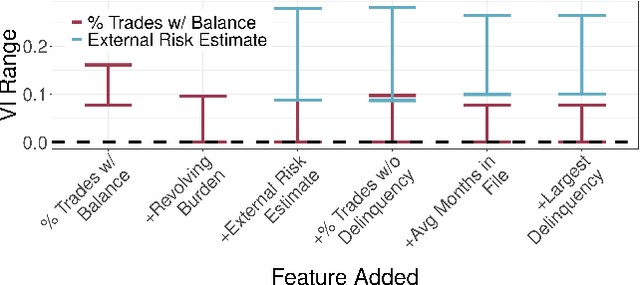
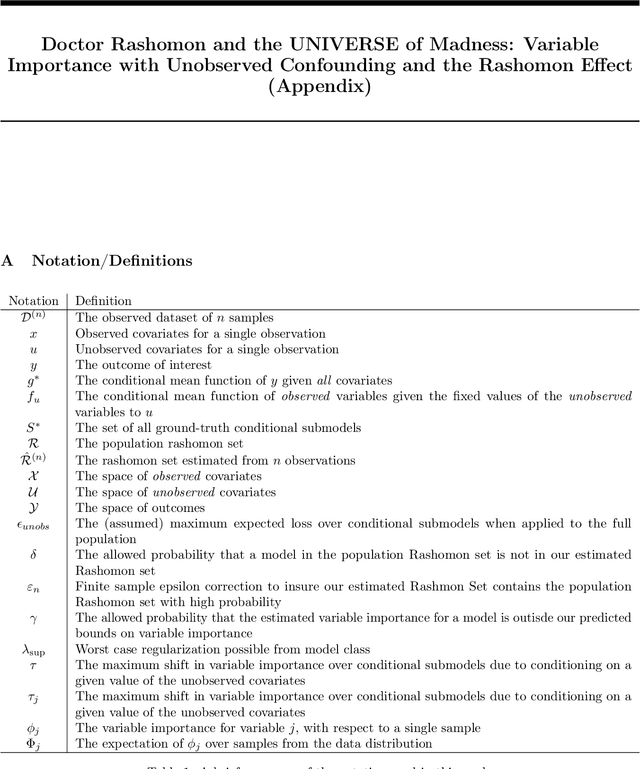
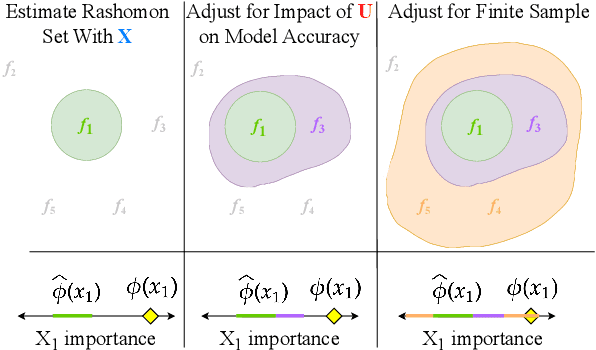
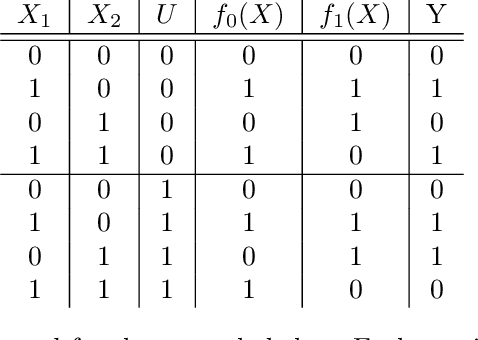
Variable importance (VI) methods are often used for hypothesis generation, feature selection, and scientific validation. In the standard VI pipeline, an analyst estimates VI for a single predictive model with only the observed features. However, the importance of a feature depends heavily on which other variables are included in the model, and essential variables are often omitted from observational datasets. Moreover, the VI estimated for one model is often not the same as the VI estimated for another equally-good model - a phenomenon known as the Rashomon Effect. We address these gaps by introducing UNobservables and Inference for Variable importancE using Rashomon SEts (UNIVERSE). Our approach adapts Rashomon sets - the sets of near-optimal models in a dataset - to produce bounds on the true VI even with missing features. We theoretically guarantee the robustness of our approach, show strong performance on semi-synthetic simulations, and demonstrate its utility in a credit risk task.
Leveraging Predictive Equivalence in Decision Trees
Jun 17, 2025



Decision trees are widely used for interpretable machine learning due to their clearly structured reasoning process. However, this structure belies a challenge we refer to as predictive equivalence: a given tree's decision boundary can be represented by many different decision trees. The presence of models with identical decision boundaries but different evaluation processes makes model selection challenging. The models will have different variable importance and behave differently in the presence of missing values, but most optimization procedures will arbitrarily choose one such model to return. We present a boolean logical representation of decision trees that does not exhibit predictive equivalence and is faithful to the underlying decision boundary. We apply our representation to several downstream machine learning tasks. Using our representation, we show that decision trees are surprisingly robust to test-time missingness of feature values; we address predictive equivalence's impact on quantifying variable importance; and we present an algorithm to optimize the cost of reaching predictions.
Data Fusion for Partial Identification of Causal Effects
May 30, 2025Data fusion techniques integrate information from heterogeneous data sources to improve learning, generalization, and decision making across data sciences. In causal inference, these methods leverage rich observational data to improve causal effect estimation, while maintaining the trustworthiness of randomized controlled trials. Existing approaches often relax the strong no unobserved confounding assumption by instead assuming exchangeability of counterfactual outcomes across data sources. However, when both assumptions simultaneously fail - a common scenario in practice - current methods cannot identify or estimate causal effects. We address this limitation by proposing a novel partial identification framework that enables researchers to answer key questions such as: Is the causal effect positive or negative? and How severe must assumption violations be to overturn this conclusion? Our approach introduces interpretable sensitivity parameters that quantify assumption violations and derives corresponding causal effect bounds. We develop doubly robust estimators for these bounds and operationalize breakdown frontier analysis to understand how causal conclusions change as assumption violations increase. We apply our framework to the Project STAR study, which investigates the effect of classroom size on students' third-grade standardized test performance. Our analysis reveals that the Project STAR results are robust to simultaneous violations of key assumptions, both on average and across various subgroups of interest. This strengthens confidence in the study's conclusions despite potential unmeasured biases in the data.
Rashomon Sets for Prototypical-Part Networks: Editing Interpretable Models in Real-Time
Mar 03, 2025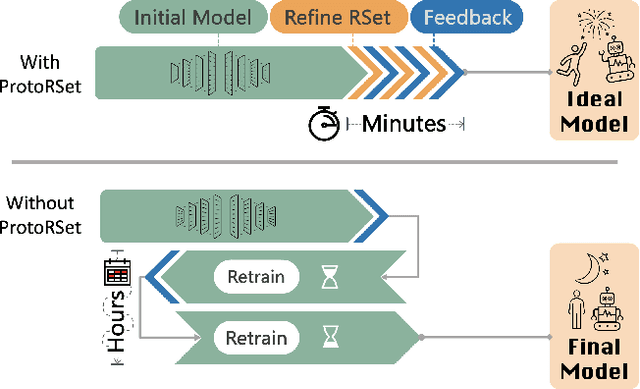
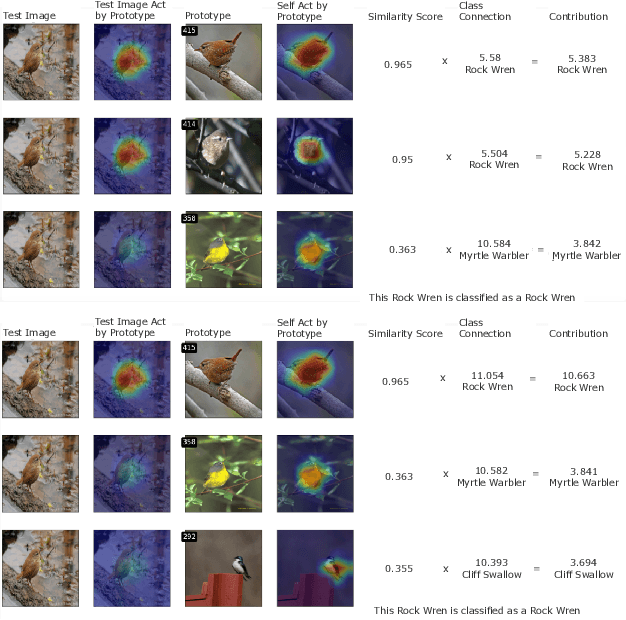

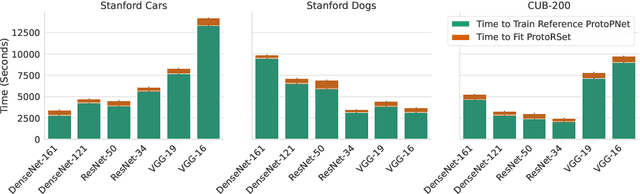
Interpretability is critical for machine learning models in high-stakes settings because it allows users to verify the model's reasoning. In computer vision, prototypical part models (ProtoPNets) have become the dominant model type to meet this need. Users can easily identify flaws in ProtoPNets, but fixing problems in a ProtoPNet requires slow, difficult retraining that is not guaranteed to resolve the issue. This problem is called the "interaction bottleneck." We solve the interaction bottleneck for ProtoPNets by simultaneously finding many equally good ProtoPNets (i.e., a draw from a "Rashomon set"). We show that our framework - called Proto-RSet - quickly produces many accurate, diverse ProtoPNets, allowing users to correct problems in real time while maintaining performance guarantees with respect to the training set. We demonstrate the utility of this method in two settings: 1) removing synthetic bias introduced to a bird identification model and 2) debugging a skin cancer identification model. This tool empowers non-machine-learning experts, such as clinicians or domain experts, to quickly refine and correct machine learning models without repeated retraining by machine learning experts.