 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt's LIT! Reliability-Optimized LLMs with Inspectable Tools
Nov 18, 2025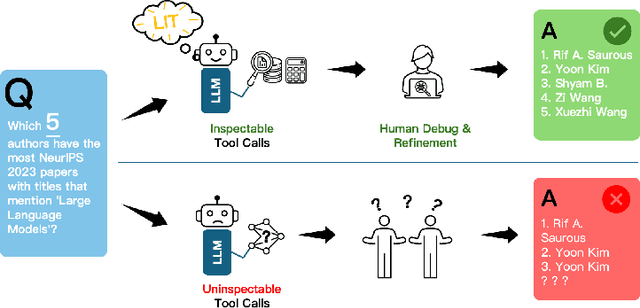
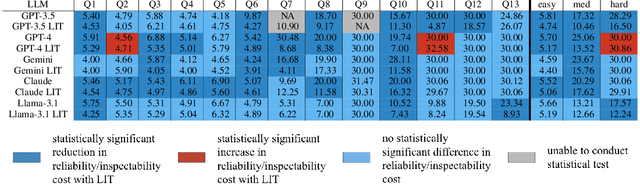
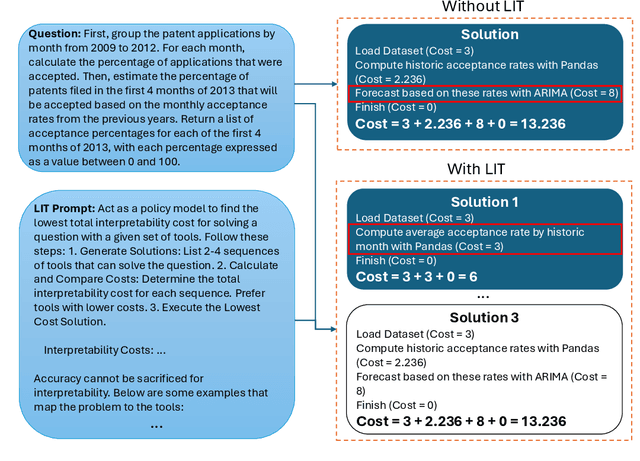
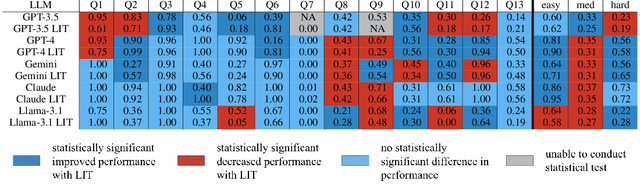
Large language models (LLMs) have exhibited remarkable capabilities across various domains. The ability to call external tools further expands their capability to handle real-world tasks. However, LLMs often follow an opaque reasoning process, which limits their usefulness in high-stakes domains where solutions need to be trustworthy to end users. LLMs can choose solutions that are unreliable and difficult to troubleshoot, even if better options are available. We address this issue by forcing LLMs to use external -- more reliable -- tools to solve problems when possible. We present a framework built on the tool-calling capabilities of existing LLMs to enable them to select the most reliable and easy-to-troubleshoot solution path, which may involve multiple sequential tool calls. We refer to this framework as LIT (LLMs with Inspectable Tools). In order to support LIT, we introduce a new and challenging benchmark dataset of 1,300 questions and a customizable set of reliability cost functions associated with a collection of specialized tools. These cost functions summarize how reliable each tool is and how easy it is to troubleshoot. For instance, a calculator is reliable across domains, whereas a linear prediction model is not reliable if there is distribution shift, but it is easy to troubleshoot. A tool that constructs a random forest is neither reliable nor easy to troubleshoot. These tools interact with the Harvard USPTO Patent Dataset and a new dataset of NeurIPS 2023 papers to solve mathematical, coding, and modeling problems of varying difficulty levels. We demonstrate that LLMs can achieve more reliable and informed problem-solving while maintaining task performance using our framework.
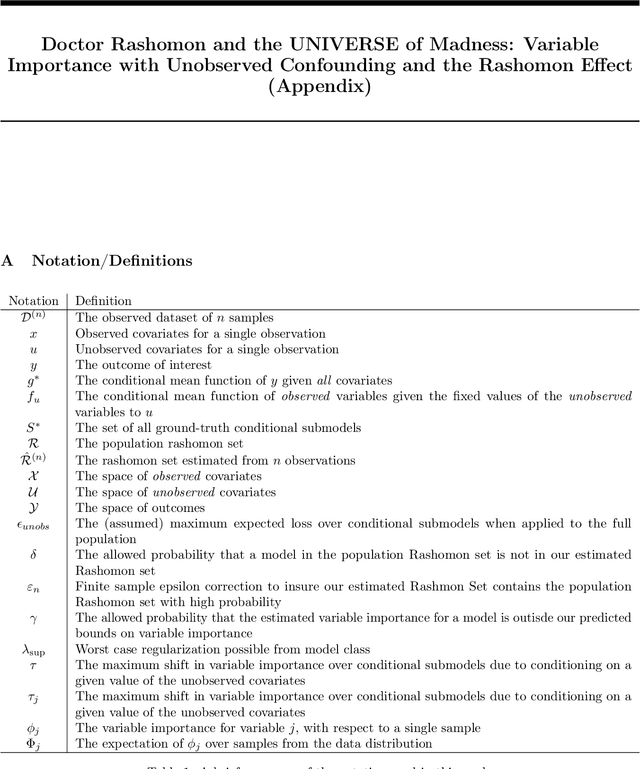
Doctor Rashomon and the UNIVERSE of Madness: Variable Importance with Unobserved Confounding and the Rashomon Effect
Oct 14, 2025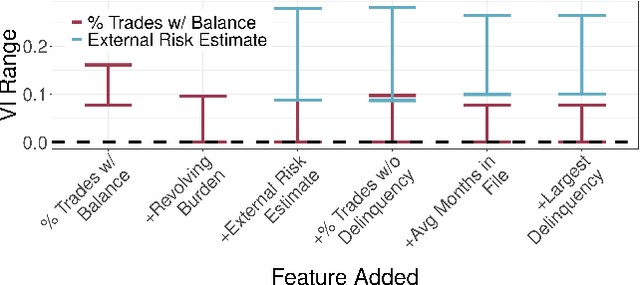
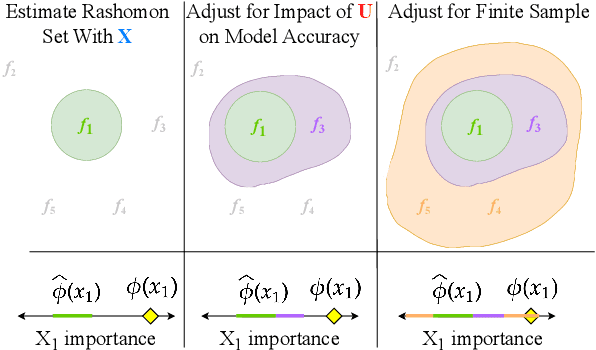
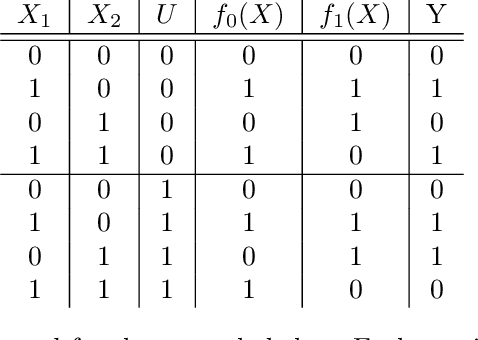
Variable importance (VI) methods are often used for hypothesis generation, feature selection, and scientific validation. In the standard VI pipeline, an analyst estimates VI for a single predictive model with only the observed features. However, the importance of a feature depends heavily on which other variables are included in the model, and essential variables are often omitted from observational datasets. Moreover, the VI estimated for one model is often not the same as the VI estimated for another equally-good model - a phenomenon known as the Rashomon Effect. We address these gaps by introducing UNobservables and Inference for Variable importancE using Rashomon SEts (UNIVERSE). Our approach adapts Rashomon sets - the sets of near-optimal models in a dataset - to produce bounds on the true VI even with missing features. We theoretically guarantee the robustness of our approach, show strong performance on semi-synthetic simulations, and demonstrate its utility in a credit risk task.
Leveraging Predictive Equivalence in Decision Trees
Jun 17, 2025Decision trees are widely used for interpretable machine learning due to their clearly structured reasoning process. However, this structure belies a challenge we refer to as predictive equivalence: a given tree's decision boundary can be represented by many different decision trees. The presence of models with identical decision boundaries but different evaluation processes makes model selection challenging. The models will have different variable importance and behave differently in the presence of missing values, but most optimization procedures will arbitrarily choose one such model to return. We present a boolean logical representation of decision trees that does not exhibit predictive equivalence and is faithful to the underlying decision boundary. We apply our representation to several downstream machine learning tasks. Using our representation, we show that decision trees are surprisingly robust to test-time missingness of feature values; we address predictive equivalence's impact on quantifying variable importance; and we present an algorithm to optimize the cost of reaching predictions.
Rashomon Sets for Prototypical-Part Networks: Editing Interpretable Models in Real-Time
Mar 03, 2025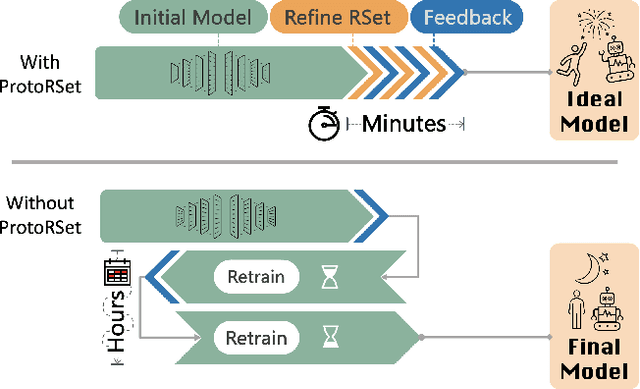
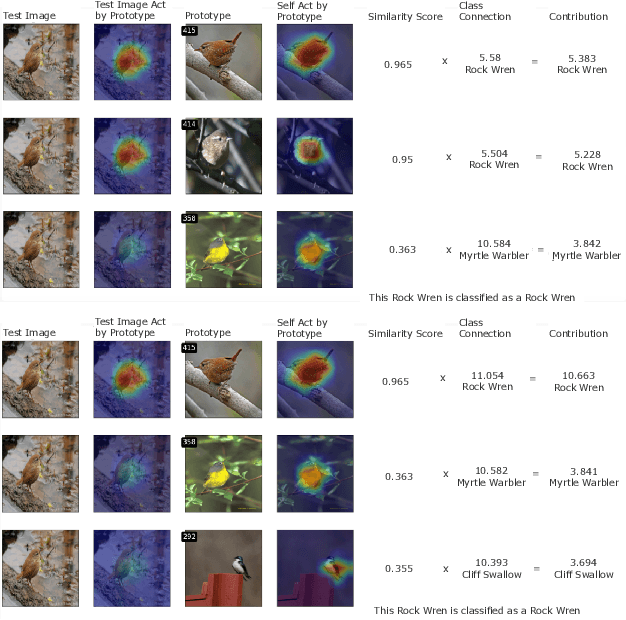

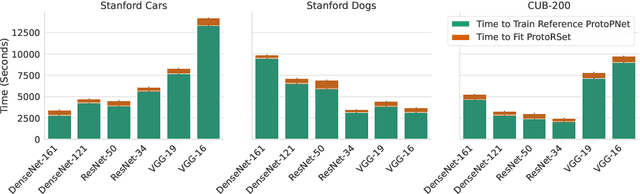
Interpretability is critical for machine learning models in high-stakes settings because it allows users to verify the model's reasoning. In computer vision, prototypical part models (ProtoPNets) have become the dominant model type to meet this need. Users can easily identify flaws in ProtoPNets, but fixing problems in a ProtoPNet requires slow, difficult retraining that is not guaranteed to resolve the issue. This problem is called the "interaction bottleneck." We solve the interaction bottleneck for ProtoPNets by simultaneously finding many equally good ProtoPNets (i.e., a draw from a "Rashomon set"). We show that our framework - called Proto-RSet - quickly produces many accurate, diverse ProtoPNets, allowing users to correct problems in real time while maintaining performance guarantees with respect to the training set. We demonstrate the utility of this method in two settings: 1) removing synthetic bias introduced to a bird identification model and 2) debugging a skin cancer identification model. This tool empowers non-machine-learning experts, such as clinicians or domain experts, to quickly refine and correct machine learning models without repeated retraining by machine learning experts.
How Your Location Relates to Health: Variable Importance and Interpretable Machine Learning for Environmental and Sociodemographic Data
Jan 03, 2025



Health outcomes depend on complex environmental and sociodemographic factors whose effects change over location and time. Only recently has fine-grained spatial and temporal data become available to study these effects, namely the MEDSAT dataset of English health, environmental, and sociodemographic information. Leveraging this new resource, we use a variety of variable importance techniques to robustly identify the most informative predictors across multiple health outcomes. We then develop an interpretable machine learning framework based on Generalized Additive Models (GAMs) and Multiscale Geographically Weighted Regression (MGWR) to analyze both local and global spatial dependencies of each variable on various health outcomes. Our findings identify NO2 as a global predictor for asthma, hypertension, and anxiety, alongside other outcome-specific predictors related to occupation, marriage, and vegetation. Regional analyses reveal local variations with air pollution and solar radiation, with notable shifts during COVID. This comprehensive approach provides actionable insights for addressing health disparities, and advocates for the integration of interpretable machine learning in public health.
Interpretable Generalized Additive Models for Datasets with Missing Values
Dec 03, 2024Many important datasets contain samples that are missing one or more feature values. Maintaining the interpretability of machine learning models in the presence of such missing data is challenging. Singly or multiply imputing missing values complicates the model's mapping from features to labels. On the other hand, reasoning on indicator variables that represent missingness introduces a potentially large number of additional terms, sacrificing sparsity. We solve these problems with M-GAM, a sparse, generalized, additive modeling approach that incorporates missingness indicators and their interaction terms while maintaining sparsity through l0 regularization. We show that M-GAM provides similar or superior accuracy to prior methods while significantly improving sparsity relative to either imputation or naive inclusion of indicator variables.
Amazing Things Come From Having Many Good Models
Jul 10, 2024



The Rashomon Effect, coined by Leo Breiman, describes the phenomenon that there exist many equally good predictive models for the same dataset. This phenomenon happens for many real datasets and when it does, it sparks both magic and consternation, but mostly magic. In light of the Rashomon Effect, this perspective piece proposes reshaping the way we think about machine learning, particularly for tabular data problems in the nondeterministic (noisy) setting. We address how the Rashomon Effect impacts (1) the existence of simple-yet-accurate models, (2) flexibility to address user preferences, such as fairness and monotonicity, without losing performance, (3) uncertainty in predictions, fairness, and explanations, (4) reliable variable importance, (5) algorithm choice, specifically, providing advanced knowledge of which algorithms might be suitable for a given problem, and (6) public policy. We also discuss a theory of when the Rashomon Effect occurs and why. Our goal is to illustrate how the Rashomon Effect can have a massive impact on the use of machine learning for complex problems in society.
This Looks Better than That: Better Interpretable Models with ProtoPNeXt
Jun 20, 2024



Prototypical-part models are a popular interpretable alternative to black-box deep learning models for computer vision. However, they are difficult to train, with high sensitivity to hyperparameter tuning, inhibiting their application to new datasets and our understanding of which methods truly improve their performance. To facilitate the careful study of prototypical-part networks (ProtoPNets), we create a new framework for integrating components of prototypical-part models -- ProtoPNeXt. Using ProtoPNeXt, we show that applying Bayesian hyperparameter tuning and an angular prototype similarity metric to the original ProtoPNet is sufficient to produce new state-of-the-art accuracy for prototypical-part models on CUB-200 across multiple backbones. We further deploy this framework to jointly optimize for accuracy and prototype interpretability as measured by metrics included in ProtoPNeXt. Using the same resources, this produces models with substantially superior semantics and changes in accuracy between +1.3% and -1.5%. The code and trained models will be made publicly available upon publication.
FPN-IAIA-BL: A Multi-Scale Interpretable Deep Learning Model for Classification of Mass Margins in Digital Mammography
Jun 10, 2024



Digital mammography is essential to breast cancer detection, and deep learning offers promising tools for faster and more accurate mammogram analysis. In radiology and other high-stakes environments, uninterpretable ("black box") deep learning models are unsuitable and there is a call in these fields to make interpretable models. Recent work in interpretable computer vision provides transparency to these formerly black boxes by utilizing prototypes for case-based explanations, achieving high accuracy in applications including mammography. However, these models struggle with precise feature localization, reasoning on large portions of an image when only a small part is relevant. This paper addresses this gap by proposing a novel multi-scale interpretable deep learning model for mammographic mass margin classification. Our contribution not only offers an interpretable model with reasoning aligned with radiologist practices, but also provides a general architecture for computer vision with user-configurable prototypes from coarse- to fine-grained prototypes.
The Rashomon Importance Distribution: Getting RID of Unstable, Single Model-based Variable Importance
Sep 26, 2023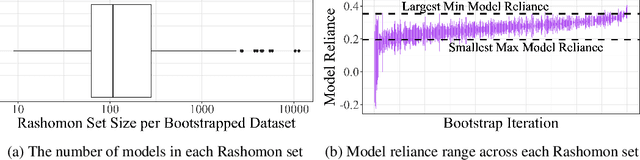

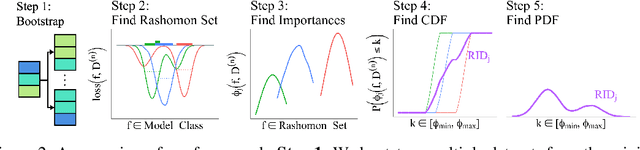
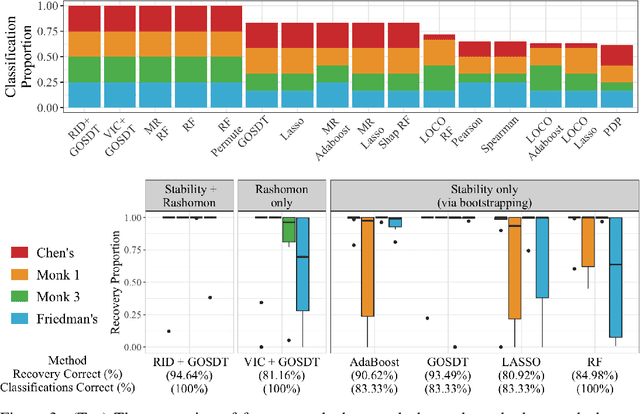
Quantifying variable importance is essential for answering high-stakes questions in fields like genetics, public policy, and medicine. Current methods generally calculate variable importance for a given model trained on a given dataset. However, for a given dataset, there may be many models that explain the target outcome equally well; without accounting for all possible explanations, different researchers may arrive at many conflicting yet equally valid conclusions given the same data. Additionally, even when accounting for all possible explanations for a given dataset, these insights may not generalize because not all good explanations are stable across reasonable data perturbations. We propose a new variable importance framework that quantifies the importance of a variable across the set of all good models and is stable across the data distribution. Our framework is extremely flexible and can be integrated with most existing model classes and global variable importance metrics. We demonstrate through experiments that our framework recovers variable importance rankings for complex simulation setups where other methods fail. Further, we show that our framework accurately estimates the true importance of a variable for the underlying data distribution. We provide theoretical guarantees on the consistency and finite sample error rates for our estimator. Finally, we demonstrate its utility with a real-world case study exploring which genes are important for predicting HIV load in persons with HIV, highlighting an important gene that has not previously been studied in connection with HIV. Code is available here.