 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Search for Sparsely Distributed Visual Phenomena through Environmental Context Modeling
Mar 10, 2026Autonomous underwater vehicles (AUVs) are increasingly used to survey coral reefs, yet efficiently locating specific coral species of interest remains difficult: target species are often sparsely distributed across the reef, and an AUV with limited battery life cannot afford to search everywhere. When detections of the target itself are too sparse to provide directional guidance, the robot benefits from an additional signal to decide where to look next. We propose using the visual environmental context -- the habitat features that tend to co-occur with a target species -- as that signal. Because context features are spatially denser and often vary more smoothly than target detections, we hypothesize that a reward function targeted at broader environmental context will enable adaptive planners to make better decisions on where to go next, even in regions where no target has yet been observed. Starting from a single labeled image, our method uses patch-level DINOv2 embeddings to perform one-shot detections of both the target species and its surrounding context online. We validate our approach using real imagery collected by an AUV at two reef sites in St. John, U.S. Virgin Islands, simulating the robot's motion offline. Our results demonstrate that one-shot detection combined with adaptive context modeling enables efficient autonomous surveying, sampling up to 75$\%$ of the target in roughly half the time required by exhaustive coverage when the target is sparsely distributed, and outperforming search strategies that only use target detections.
Patch-Based Spatial Authorship Attribution in Human-Robot Collaborative Paintings
Feb 19, 2026As agentic AI becomes increasingly involved in creative production, documenting authorship has become critical for artists, collectors, and legal contexts. We present a patch-based framework for spatial authorship attribution within human-robot collaborative painting practice, demonstrated through a forensic case study of one human artist and one robotic system across 15 abstract paintings. Using commodity flatbed scanners and leave-one-painting-out cross-validation, the approach achieves 88.8% patch-level accuracy (86.7% painting-level via majority vote), outperforming texture-based and pretrained-feature baselines (68.0%-84.7%). For collaborative artworks, where ground truth is inherently ambiguous, we use conditional Shannon entropy to quantify stylistic overlap; manually annotated hybrid regions exhibit 64% higher uncertainty than pure paintings (p=0.003), suggesting the model detects mixed authorship rather than classification failure. The trained model is specific to this human-robot pair but provides a methodological grounding for sample-efficient attribution in data-scarce human-AI creative workflows that, in the future, has the potential to extend authorship attribution to any human-robot collaborative painting.
Artists' Views on Robotics Involvement in Painting Productions
Oct 08, 2025
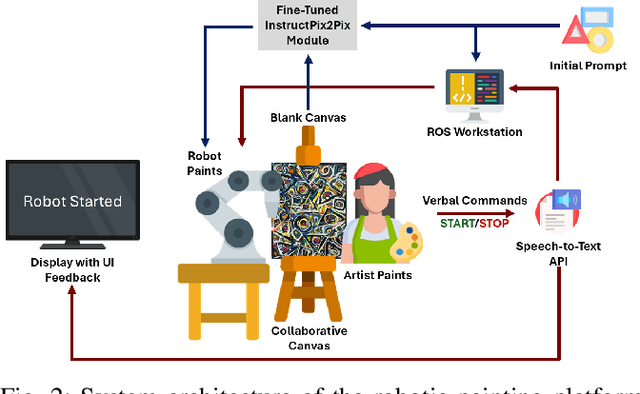


As robotic technologies evolve, their potential in artistic creation becomes an increasingly relevant topic of inquiry. This study explores how professional abstract artists perceive and experience co-creative interactions with an autonomous painting robotic arm. Eight artists engaged in six painting sessions -- three with a human partner, followed by three with the robot -- and subsequently participated in semi-structured interviews analyzed through reflexive thematic analysis. Human-human interactions were described as intuitive, dialogic, and emotionally engaging, whereas human-robot sessions felt more playful and reflective, offering greater autonomy and prompting for novel strategies to overcome the system's limitations. This work offers one of the first empirical investigations into artists' lived experiences with a robot, highlighting the value of long-term engagement and a multidisciplinary approach to human-robot co-creation.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
Comprehensive Examination of Unrolled Networks for Linear Inverse Problems
Jan 08, 2025



Unrolled networks have become prevalent in various computer vision and imaging tasks. Although they have demonstrated remarkable efficacy in solving specific computer vision and computational imaging tasks, their adaptation to other applications presents considerable challenges. This is primarily due to the multitude of design decisions that practitioners working on new applications must navigate, each potentially affecting the network's overall performance. These decisions include selecting the optimization algorithm, defining the loss function, and determining the number of convolutional layers, among others. Compounding the issue, evaluating each design choice requires time-consuming simulations to train, fine-tune the neural network, and optimize for its performance. As a result, the process of exploring multiple options and identifying the optimal configuration becomes time-consuming and computationally demanding. The main objectives of this paper are (1) to unify some ideas and methodologies used in unrolled networks to reduce the number of design choices a user has to make, and (2) to report a comprehensive ablation study to discuss the impact of each of the choices involved in designing unrolled networks and present practical recommendations based on our findings. We anticipate that this study will help scientists and engineers design unrolled networks for their applications and diagnose problems within their networks efficiently.
How Your Location Relates to Health: Variable Importance and Interpretable Machine Learning for Environmental and Sociodemographic Data
Jan 03, 2025



Health outcomes depend on complex environmental and sociodemographic factors whose effects change over location and time. Only recently has fine-grained spatial and temporal data become available to study these effects, namely the MEDSAT dataset of English health, environmental, and sociodemographic information. Leveraging this new resource, we use a variety of variable importance techniques to robustly identify the most informative predictors across multiple health outcomes. We then develop an interpretable machine learning framework based on Generalized Additive Models (GAMs) and Multiscale Geographically Weighted Regression (MGWR) to analyze both local and global spatial dependencies of each variable on various health outcomes. Our findings identify NO2 as a global predictor for asthma, hypertension, and anxiety, alongside other outcome-specific predictors related to occupation, marriage, and vegetation. Regional analyses reveal local variations with air pollution and solar radiation, with notable shifts during COVID. This comprehensive approach provides actionable insights for addressing health disparities, and advocates for the integration of interpretable machine learning in public health.
Vibe-Eval: A hard evaluation suite for measuring progress of multimodal language models
May 03, 2024
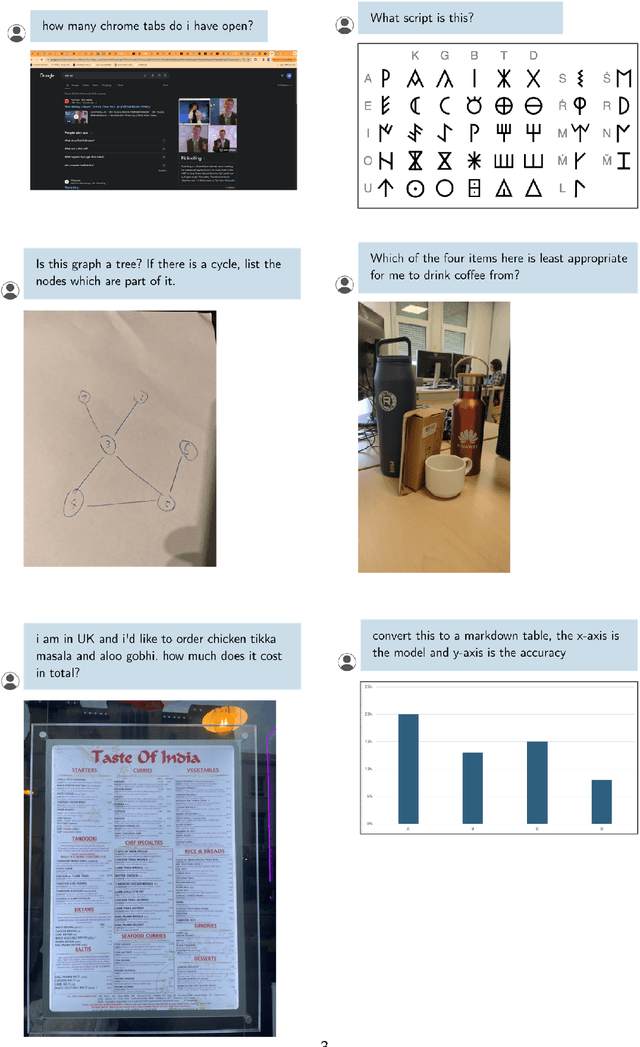
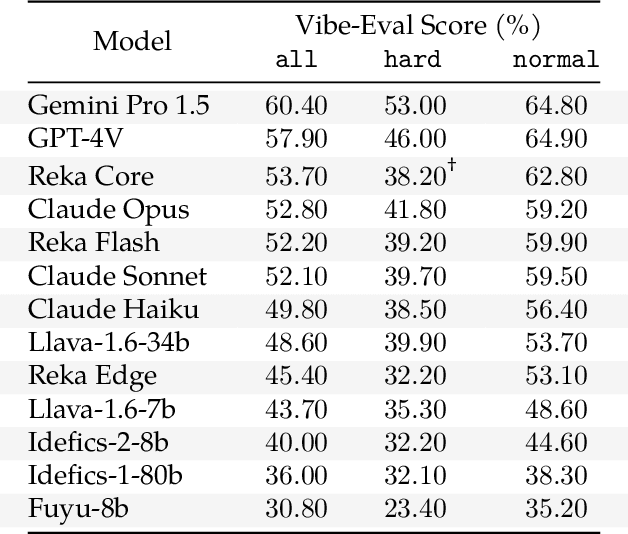
We introduce Vibe-Eval: a new open benchmark and framework for evaluating multimodal chat models. Vibe-Eval consists of 269 visual understanding prompts, including 100 of hard difficulty, complete with gold-standard responses authored by experts. Vibe-Eval is open-ended and challenging with dual objectives: (i) vibe checking multimodal chat models for day-to-day tasks and (ii) rigorously testing and probing the capabilities of present frontier models. Notably, our hard set contains >50% questions that all frontier models answer incorrectly. We explore the nuances of designing, evaluating, and ranking models on ultra challenging prompts. We also discuss trade-offs between human and automatic evaluation, and show that automatic model evaluation using Reka Core roughly correlates to human judgment. We offer free API access for the purpose of lightweight evaluation and plan to conduct formal human evaluations for public models that perform well on the Vibe-Eval's automatic scores. We release the evaluation code and data, see https://github.com/reka-ai/reka-vibe-eval
Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models
Apr 18, 2024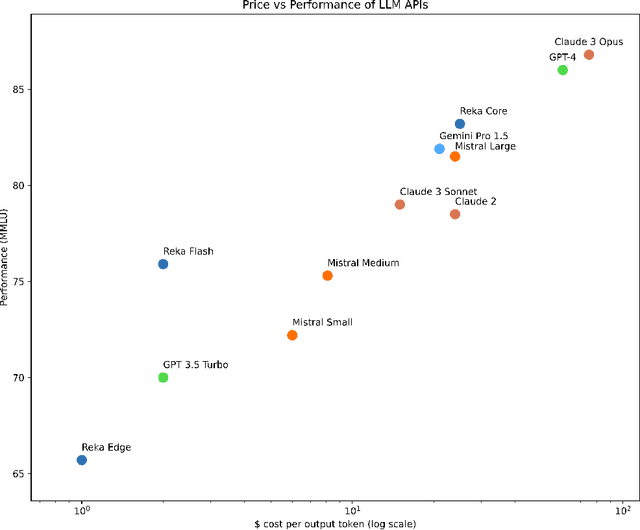


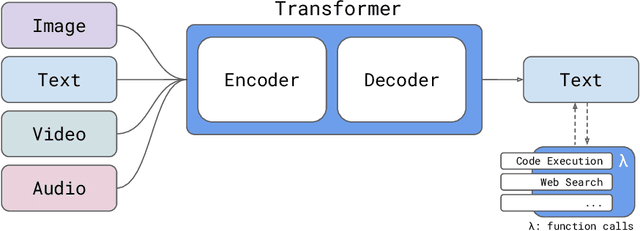
We introduce Reka Core, Flash, and Edge, a series of powerful multimodal language models trained from scratch by Reka. Reka models are able to process and reason with text, images, video, and audio inputs. This technical report discusses details of training some of these models and provides comprehensive evaluation results. We show that Reka Edge and Reka Flash are not only state-of-the-art but also outperform many much larger models, delivering outsized values for their respective compute class. Meanwhile, our most capable and largest model, Reka Core, approaches the best frontier models on both automatic evaluations and blind human evaluations. On image question answering benchmarks (e.g. MMMU, VQAv2), Core performs competitively to GPT4-V. Meanwhile, on multimodal chat, Core ranks as the second most preferred model under a blind third-party human evaluation setup, outperforming other models such as Claude 3 Opus. On text benchmarks, Core not only performs competitively to other frontier models on a set of well-established benchmarks (e.g. MMLU, GSM8K) but also outperforms GPT4-0613 on human evaluation. On video question answering (Perception-Test), Core outperforms Gemini Ultra. Models are shipped in production at http://chat.reka.ai . A showcase of non cherry picked qualitative examples can also be found at http://showcase.reka.ai .
Telling Left from Right: Identifying Geometry-Aware Semantic Correspondence
Nov 28, 2023



While pre-trained large-scale vision models have shown significant promise for semantic correspondence, their features often struggle to grasp the geometry and orientation of instances. This paper identifies the importance of being geometry-aware for semantic correspondence and reveals a limitation of the features of current foundation models under simple post-processing. We show that incorporating this information can markedly enhance semantic correspondence performance with simple but effective solutions in both zero-shot and supervised settings. We also construct a new challenging benchmark for semantic correspondence built from an existing animal pose estimation dataset, for both pre-training validating models. Our method achieves a PCK@0.10 score of 64.2 (zero-shot) and 85.6 (supervised) on the challenging SPair-71k dataset, outperforming the state-of-the-art by 4.3p and 11.0p absolute gains, respectively. Our code and datasets will be publicly available.
Neuro-Inspired Fragmentation and Recall to Overcome Catastrophic Forgetting in Curiosity
Oct 26, 2023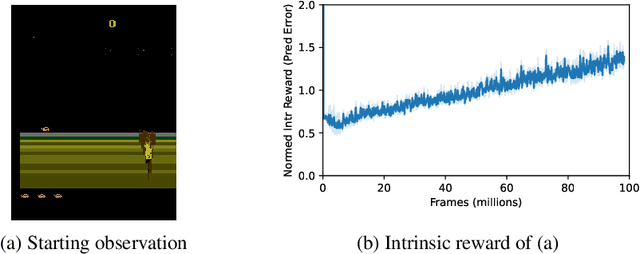
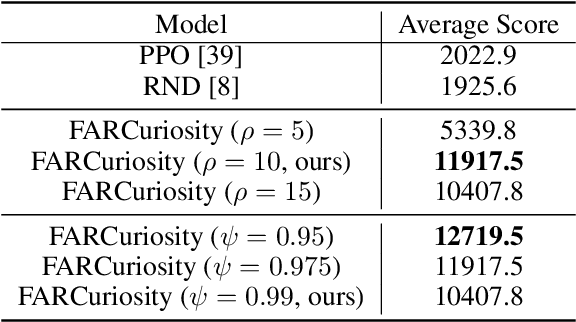
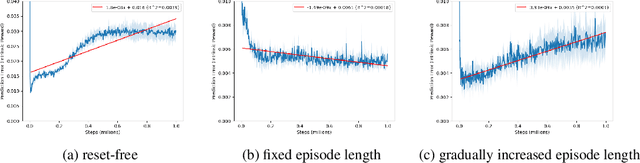

Deep reinforcement learning methods exhibit impressive performance on a range of tasks but still struggle on hard exploration tasks in large environments with sparse rewards. To address this, intrinsic rewards can be generated using forward model prediction errors that decrease as the environment becomes known, and incentivize an agent to explore novel states. While prediction-based intrinsic rewards can help agents solve hard exploration tasks, they can suffer from catastrophic forgetting and actually increase at visited states. We first examine the conditions and causes of catastrophic forgetting in grid world environments. We then propose a new method FARCuriosity, inspired by how humans and animals learn. The method depends on fragmentation and recall: an agent fragments an environment based on surprisal, and uses different local curiosity modules (prediction-based intrinsic reward functions) for each fragment so that modules are not trained on the entire environment. At each fragmentation event, the agent stores the current module in long-term memory (LTM) and either initializes a new module or recalls a previously stored module based on its match with the current state. With fragmentation and recall, FARCuriosity achieves less forgetting and better overall performance in games with varied and heterogeneous environments in the Atari benchmark suite of tasks. Thus, this work highlights the problem of catastrophic forgetting in prediction-based curiosity methods and proposes a solution.