 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartChoices: Augmenting Software with Learned Implementations
Apr 12, 2023
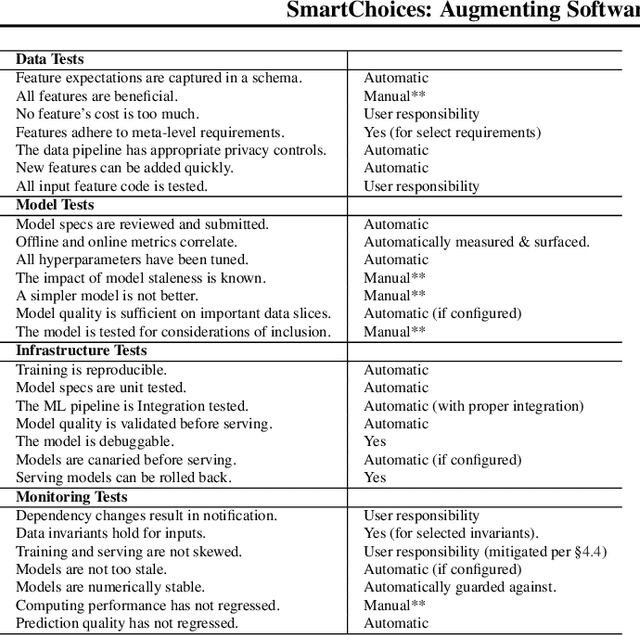
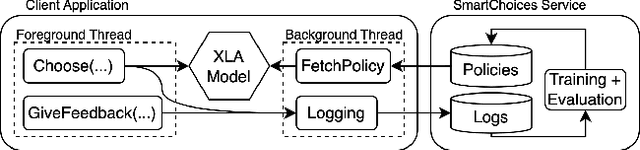

We are living in a golden age of machine learning. Powerful models are being trained to perform many tasks far better than is possible using traditional software engineering approaches alone. However, developing and deploying those models in existing software systems remains difficult. In this paper we present SmartChoices, a novel approach to incorporating machine learning into mature software stacks easily, safely, and effectively. We explain the overall design philosophy and present case studies using SmartChoices within large scale industrial systems.
Ranking architectures using meta-learning
Nov 26, 2019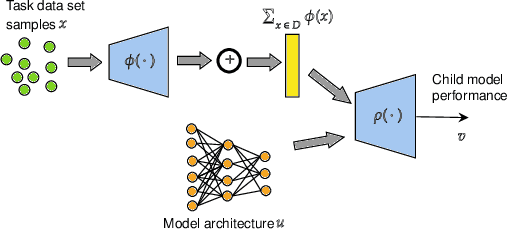
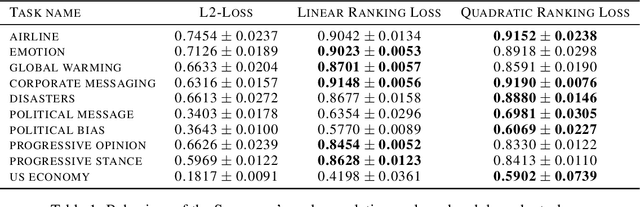
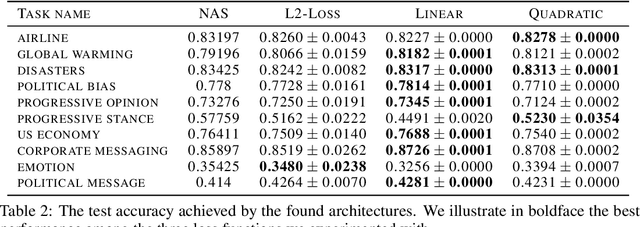
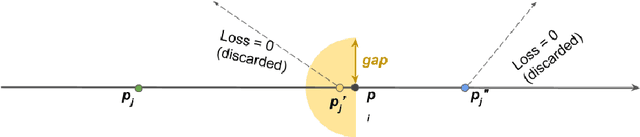
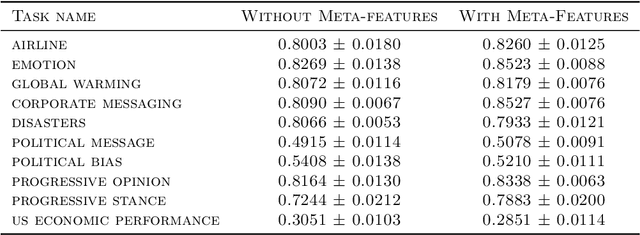
Neural architecture search has recently attracted lots of research efforts as it promises to automate the manual design of neural networks. However, it requires a large amount of computing resources and in order to alleviate this, a performance prediction network has been recently proposed that enables efficient architecture search by forecasting the performance of candidate architectures, instead of relying on actual model training. The performance predictor is task-aware taking as input not only the candidate architecture but also task meta-features and it has been designed to collectively learn from several tasks. In this work, we introduce a pairwise ranking loss for training a network able to rank candidate architectures for a new unseen task conditioning on its task meta-features. We present experimental results, showing that the ranking network is more effective in architecture search than the previously proposed performance predictor.
Gumbel-Matrix Routing for Flexible Multi-task Learning
Oct 10, 2019

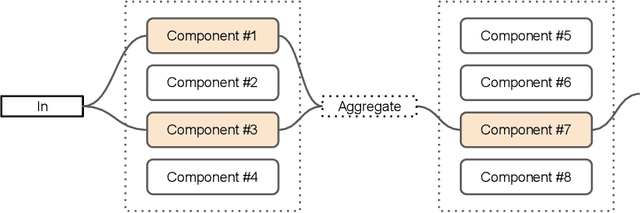
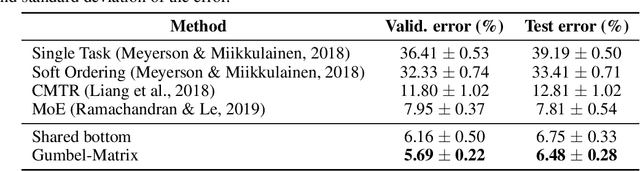
This paper proposes a novel per-task routing method for multi-task applications. Multi-task neural networks can learn to transfer knowledge across different tasks by using parameter sharing. However, sharing parameters between unrelated tasks can hurt performance. To address this issue, we advocate the use of routing networks to learn flexible parameter sharing, where each group of parameters is shared with a different subset of tasks in order to better leverage tasks relatedness. At the same time, it is known that routing networks are notoriously hard to train. We propose the Gumbel-Matrix routing: a novel multi-task routing method, designed to learn fine-grained patterns of parameter sharing. The routing is learned jointly with the model parameters by standard back-propagation thanks to the Gumbel-Softmax trick. When applied to the Omniglot benchmark, the proposed method reduces the state-of-the-art error rate by 17%.
Fast Task-Aware Architecture Inference
Feb 15, 2019


Neural architecture search has been shown to hold great promise towards the automation of deep learning. However in spite of its potential, neural architecture search remains quite costly. To this point, we propose a novel gradient-based framework for efficient architecture search by sharing information across several tasks. We start by training many model architectures on several related (training) tasks. When a new unseen task is presented, the framework performs architecture inference in order to quickly identify a good candidate architecture, before any model is trained on the new task. At the core of our framework lies a deep value network that can predict the performance of input architectures on a task by utilizing task meta-features and the previous model training experiments performed on related tasks. We adopt a continuous parametrization of the model architecture which allows for efficient gradient-based optimization. Given a new task, an effective architecture is quickly identified by maximizing the estimated performance with respect to the model architecture parameters with simple gradient ascent. It is key to point out that our goal is to achieve reasonable performance at the lowest cost. We provide experimental results showing the effectiveness of the framework despite its high computational efficiency.
An Adaptive Algorithm for Finite Stochastic Partial Monitoring
Jun 27, 2012
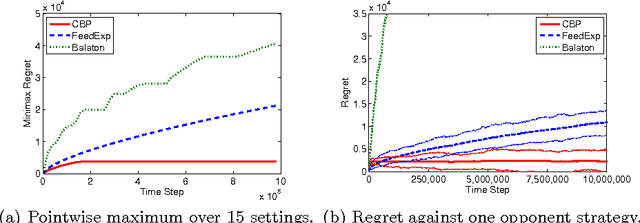
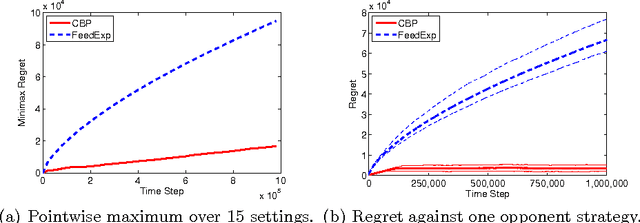
We present a new anytime algorithm that achieves near-optimal regret for any instance of finite stochastic partial monitoring. In particular, the new algorithm achieves the minimax regret, within logarithmic factors, for both "easy" and "hard" problems. For easy problems, it additionally achieves logarithmic individual regret. Most importantly, the algorithm is adaptive in the sense that if the opponent strategy is in an "easy region" of the strategy space then the regret grows as if the problem was easy. As an implication, we show that under some reasonable additional assumptions, the algorithm enjoys an O(\sqrt{T}) regret in Dynamic Pricing, proven to be hard by Bartok et al. (2011).