 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-path Neural Networks for On-device Multi-domain Visual Classification
Oct 10, 2020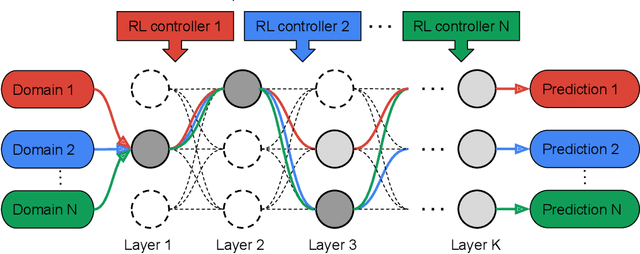
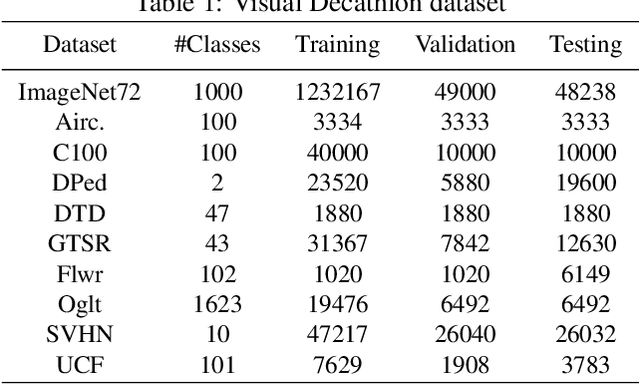
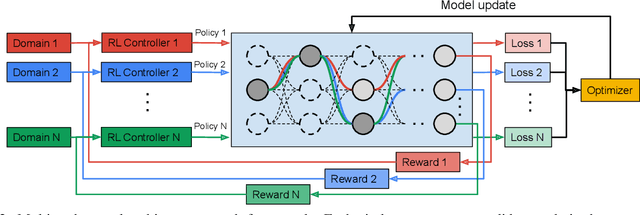
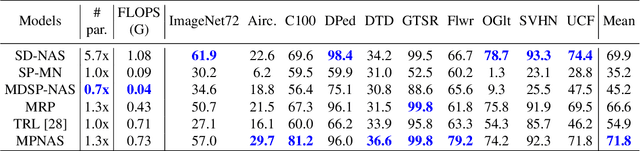
Learning multiple domains/tasks with a single model is important for improving data efficiency and lowering inference cost for numerous vision tasks, especially on resource-constrained mobile devices. However, hand-crafting a multi-domain/task model can be both tedious and challenging. This paper proposes a novel approach to automatically learn a multi-path network for multi-domain visual classification on mobile devices. The proposed multi-path network is learned from neural architecture search by applying one reinforcement learning controller for each domain to select the best path in the super-network created from a MobileNetV3-like search space. An adaptive balanced domain prioritization algorithm is proposed to balance optimizing the joint model on multiple domains simultaneously. The determined multi-path model selectively shares parameters across domains in shared nodes while keeping domain-specific parameters within non-shared nodes in individual domain paths. This approach effectively reduces the total number of parameters and FLOPS, encouraging positive knowledge transfer while mitigating negative interference across domains. Extensive evaluations on the Visual Decathlon dataset demonstrate that the proposed multi-path model achieves state-of-the-art performance in terms of accuracy, model size, and FLOPS against other approaches using MobileNetV3-like architectures. Furthermore, the proposed method improves average accuracy over learning single-domain models individually, and reduces the total number of parameters and FLOPS by 78% and 32% respectively, compared to the approach that simply bundles single-domain models for multi-domain learning.
Single-Photon Image Classification
Aug 13, 2020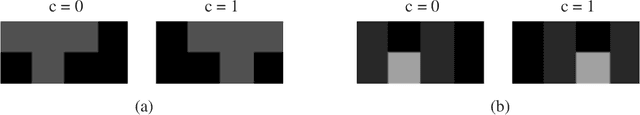
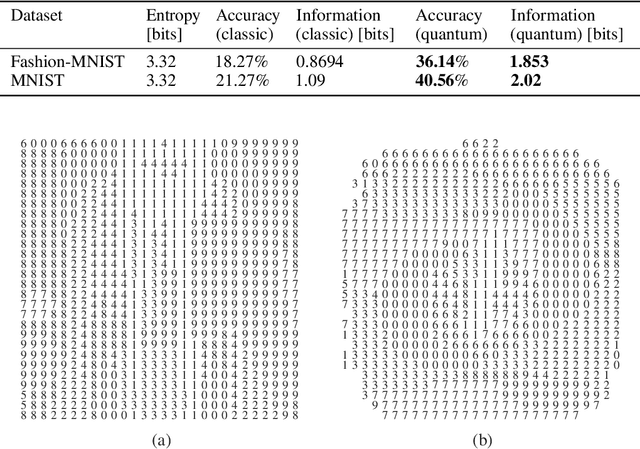
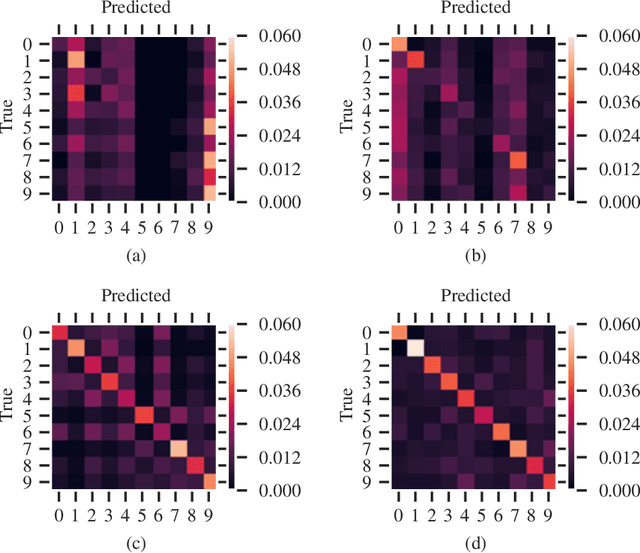

Quantum computing-based machine learning mainly focuses on quantum computing hardware that is experimentally challenging to realize due to requiring quantum gates that operate at very low temperature. Instead, we demonstrate the existence of a lower performance and much lower effort island on the accuracy-vs-qubits graph that may well be experimentally accessible with room temperature optics. This high temperature "quantum computing toy model" is nevertheless interesting to study as it allows rather accessible explanations of key concepts in quantum computing, in particular interference, entanglement, and the measurement process. We specifically study the problem of classifying an example from the MNIST and Fashion-MNIST datasets, subject to the constraint that we have to make a prediction after the detection of the very first photon that passed a coherently illuminated filter showing the example. Whereas a classical set-up in which a photon is detected after falling on one of the~$28\times 28$ image pixels is limited to a (maximum likelihood estimation) accuracy of~$21.27\%$ for MNIST, respectively $18.27\%$ for Fashion-MNIST, we show that the theoretically achievable accuracy when exploiting inference by optically transforming the quantum state of the photon is at least $41.27\%$ for MNIST, respectively $36.14\%$ for Fashion-MNIST. We show in detail how to train the corresponding transformation with TensorFlow and also explain how this example can serve as a teaching tool for the measurement process in quantum mechanics.
Ranking architectures using meta-learning
Nov 26, 2019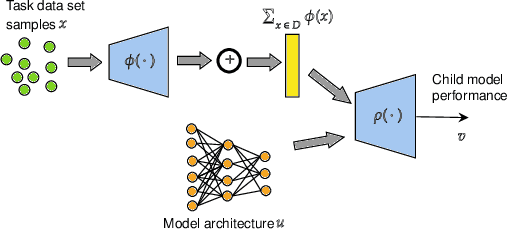
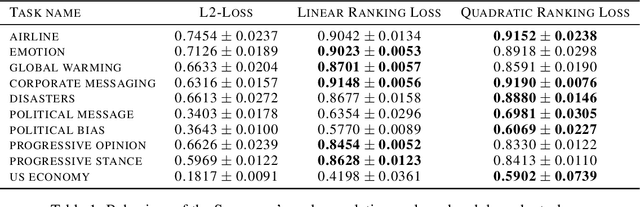
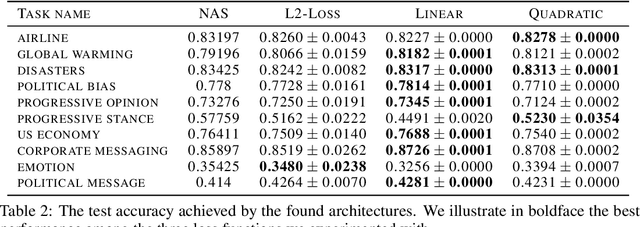
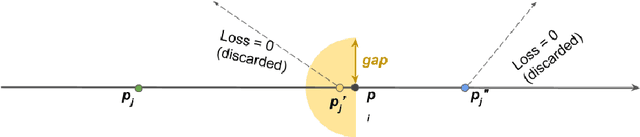
Neural architecture search has recently attracted lots of research efforts as it promises to automate the manual design of neural networks. However, it requires a large amount of computing resources and in order to alleviate this, a performance prediction network has been recently proposed that enables efficient architecture search by forecasting the performance of candidate architectures, instead of relying on actual model training. The performance predictor is task-aware taking as input not only the candidate architecture but also task meta-features and it has been designed to collectively learn from several tasks. In this work, we introduce a pairwise ranking loss for training a network able to rank candidate architectures for a new unseen task conditioning on its task meta-features. We present experimental results, showing that the ranking network is more effective in architecture search than the previously proposed performance predictor.
Gumbel-Matrix Routing for Flexible Multi-task Learning
Oct 10, 2019

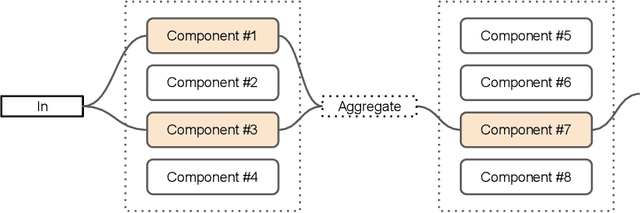
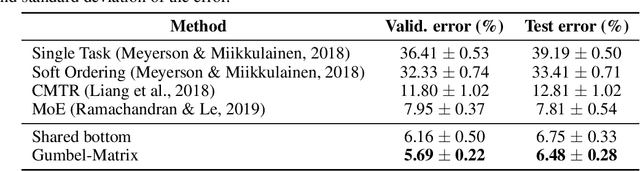
This paper proposes a novel per-task routing method for multi-task applications. Multi-task neural networks can learn to transfer knowledge across different tasks by using parameter sharing. However, sharing parameters between unrelated tasks can hurt performance. To address this issue, we advocate the use of routing networks to learn flexible parameter sharing, where each group of parameters is shared with a different subset of tasks in order to better leverage tasks relatedness. At the same time, it is known that routing networks are notoriously hard to train. We propose the Gumbel-Matrix routing: a novel multi-task routing method, designed to learn fine-grained patterns of parameter sharing. The routing is learned jointly with the model parameters by standard back-propagation thanks to the Gumbel-Softmax trick. When applied to the Omniglot benchmark, the proposed method reduces the state-of-the-art error rate by 17%.
Fast Task-Aware Architecture Inference
Feb 15, 2019


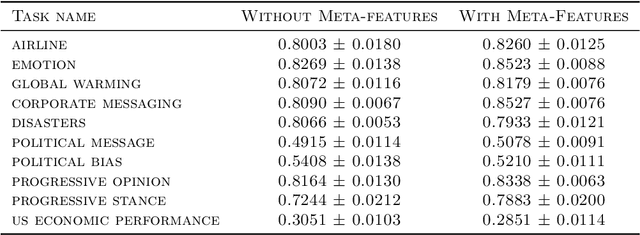
Neural architecture search has been shown to hold great promise towards the automation of deep learning. However in spite of its potential, neural architecture search remains quite costly. To this point, we propose a novel gradient-based framework for efficient architecture search by sharing information across several tasks. We start by training many model architectures on several related (training) tasks. When a new unseen task is presented, the framework performs architecture inference in order to quickly identify a good candidate architecture, before any model is trained on the new task. At the core of our framework lies a deep value network that can predict the performance of input architectures on a task by utilizing task meta-features and the previous model training experiments performed on related tasks. We adopt a continuous parametrization of the model architecture which allows for efficient gradient-based optimization. Given a new task, an effective architecture is quickly identified by maximizing the estimated performance with respect to the model architecture parameters with simple gradient ascent. It is key to point out that our goal is to achieve reasonable performance at the lowest cost. We provide experimental results showing the effectiveness of the framework despite its high computational efficiency.