 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-Constrained Neural Architecture Search on Tabular Datasets
Apr 15, 2022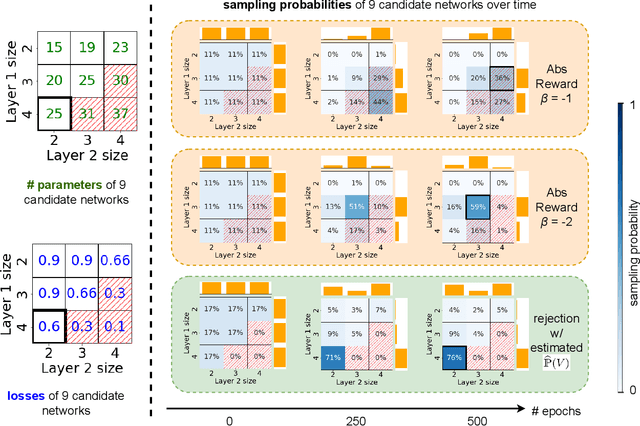
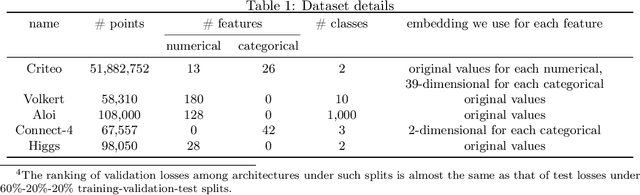
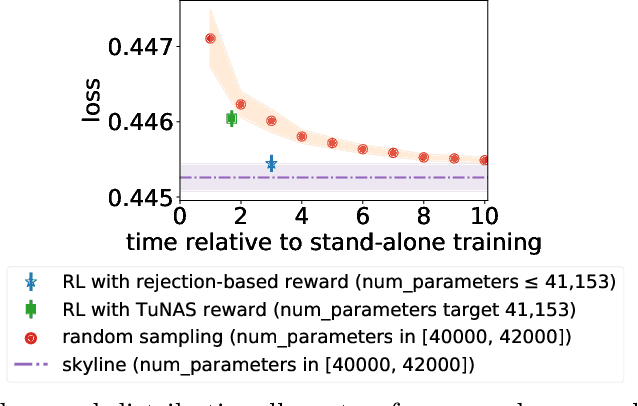
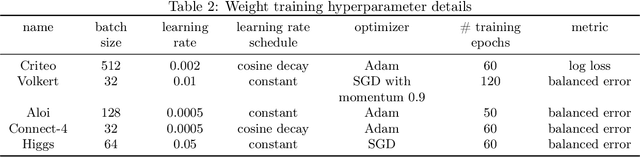
The best neural architecture for a given machine learning problem depends on many factors: not only the complexity and structure of the dataset, but also on resource constraints including latency, compute, energy consumption, etc. Neural architecture search (NAS) for tabular datasets is an important but under-explored problem. Previous NAS algorithms designed for image search spaces incorporate resource constraints directly into the reinforcement learning rewards. In this paper, we argue that search spaces for tabular NAS pose considerable challenges for these existing reward-shaping methods, and propose a new reinforcement learning (RL) controller to address these challenges. Motivated by rejection sampling, when we sample candidate architectures during a search, we immediately discard any architecture that violates our resource constraints. We use a Monte-Carlo-based correction to our RL policy gradient update to account for this extra filtering step. Results on several tabular datasets show TabNAS, the proposed approach, efficiently finds high-quality models that satisfy the given resource constraints.
PyGlove: Symbolic Programming for Automated Machine Learning
Jan 21, 2021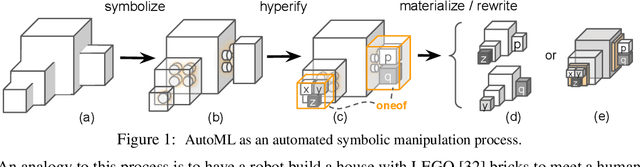
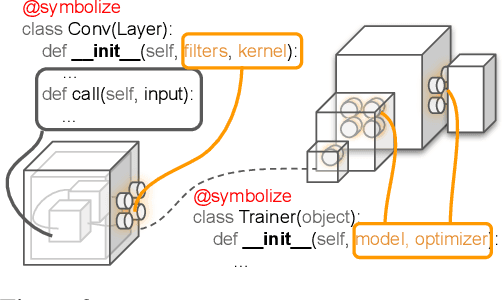
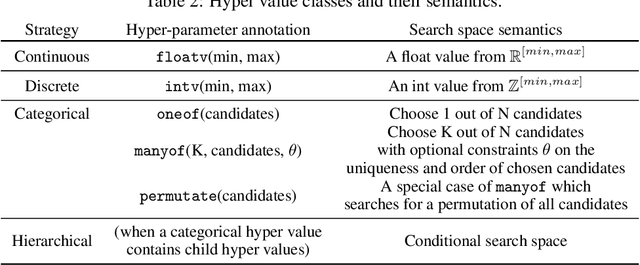
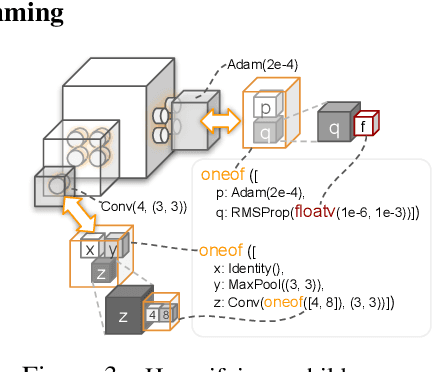
Neural networks are sensitive to hyper-parameter and architecture choices. Automated Machine Learning (AutoML) is a promising paradigm for automating these choices. Current ML software libraries, however, are quite limited in handling the dynamic interactions among the components of AutoML. For example, efficientNAS algorithms, such as ENAS and DARTS, typically require an implementation coupling between the search space and search algorithm, the two key components in AutoML. Furthermore, implementing a complex search flow, such as searching architectures within a loop of searching hardware configurations, is difficult. To summarize, changing the search space, search algorithm, or search flow in current ML libraries usually requires a significant change in the program logic. In this paper, we introduce a new way of programming AutoML based on symbolic programming. Under this paradigm, ML programs are mutable, thus can be manipulated easily by another program. As a result, AutoML can be reformulated as an automated process of symbolic manipulation. With this formulation, we decouple the triangle of the search algorithm, the search space and the child program. This decoupling makes it easy to change the search space and search algorithm (without and with weight sharing), as well as to add search capabilities to existing code and implement complex search flows. We then introduce PyGlove, a new Python library that implements this paradigm. Through case studies on ImageNet and NAS-Bench-101, we show that with PyGlove users can easily convert a static program into a search space, quickly iterate on the search spaces and search algorithms, and craft complex search flows to achieve better results.
Multi-path Neural Networks for On-device Multi-domain Visual Classification
Oct 10, 2020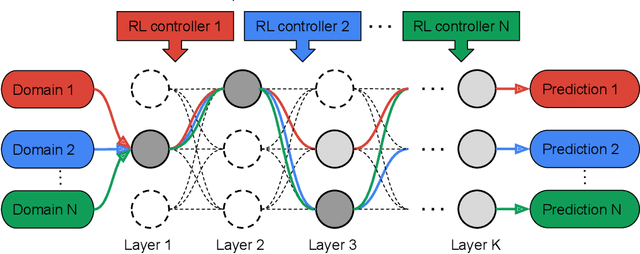
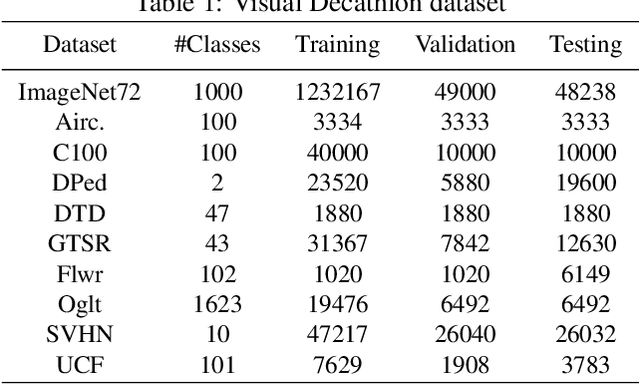
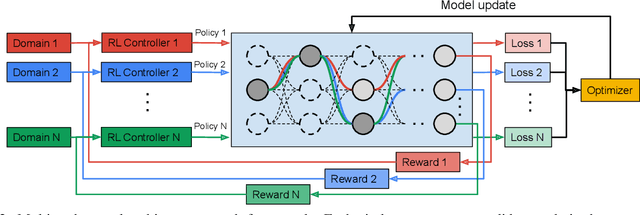
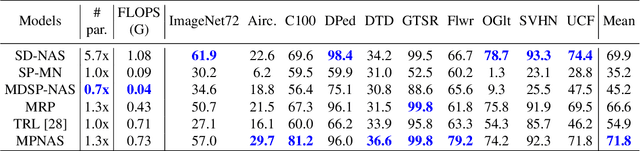
Learning multiple domains/tasks with a single model is important for improving data efficiency and lowering inference cost for numerous vision tasks, especially on resource-constrained mobile devices. However, hand-crafting a multi-domain/task model can be both tedious and challenging. This paper proposes a novel approach to automatically learn a multi-path network for multi-domain visual classification on mobile devices. The proposed multi-path network is learned from neural architecture search by applying one reinforcement learning controller for each domain to select the best path in the super-network created from a MobileNetV3-like search space. An adaptive balanced domain prioritization algorithm is proposed to balance optimizing the joint model on multiple domains simultaneously. The determined multi-path model selectively shares parameters across domains in shared nodes while keeping domain-specific parameters within non-shared nodes in individual domain paths. This approach effectively reduces the total number of parameters and FLOPS, encouraging positive knowledge transfer while mitigating negative interference across domains. Extensive evaluations on the Visual Decathlon dataset demonstrate that the proposed multi-path model achieves state-of-the-art performance in terms of accuracy, model size, and FLOPS against other approaches using MobileNetV3-like architectures. Furthermore, the proposed method improves average accuracy over learning single-domain models individually, and reduces the total number of parameters and FLOPS by 78% and 32% respectively, compared to the approach that simply bundles single-domain models for multi-domain learning.
Discovering Multi-Hardware Mobile Models via Architecture Search
Aug 18, 2020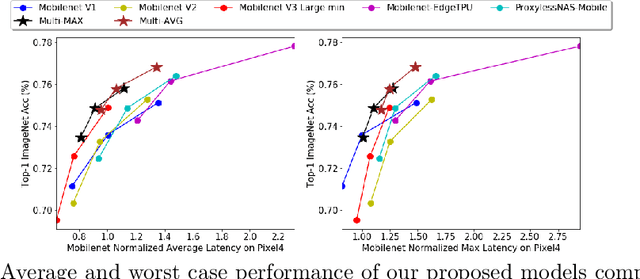

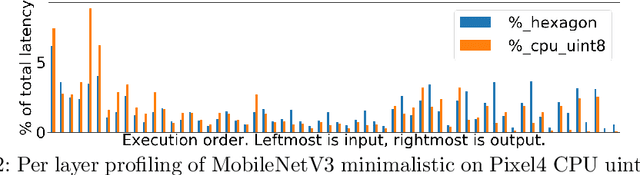
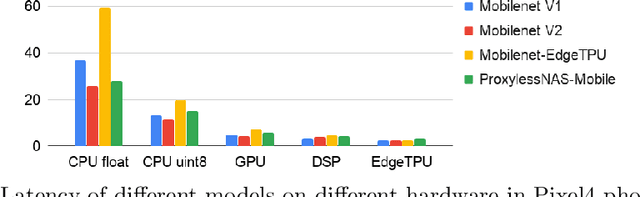
Developing efficient models for mobile phones or other on-device deployments has been a popular topic in both industry and academia. In such scenarios, it is often convenient to deploy the same model on a diverse set of hardware devices owned by different end users to minimize the costs of development, deployment and maintenance. Despite the importance, designing a single neural network that can perform well on multiple devices is difficult as each device has its own specialty and restrictions: A model optimized for one device may not perform well on another. While most existing work proposes different models optimized for each single hardware, this paper is the first which explores the problem of finding a single model that performs well on multiple hardware. Specifically, we leverage architecture search to help us find the best model, where given a set of diverse hardware to optimize for, we first introduce a multi-hardware search space that is compatible with all examined hardware. Then, to measure the performance of a neural network over multiple hardware, we propose metrics that can characterize the overall latency performance in an average case and worst case scenario. With the multi-hardware search space and new metrics applied to Pixel4 CPU, GPU, DSP and EdgeTPU, we found models that perform on par or better than state-of-the-art (SOTA) models on each of our target accelerators and generalize well on many un-targeted hardware. Comparing with single-hardware searches, multi-hardware search gives a better trade-off between computation cost and model performance.
Can weight sharing outperform random architecture search? An investigation with TuNAS
Aug 13, 2020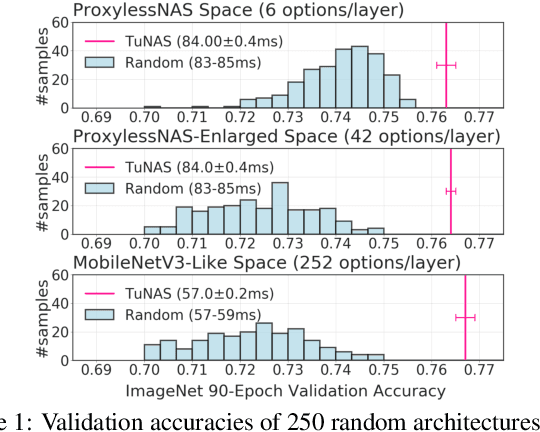


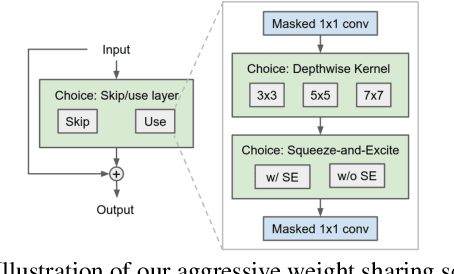
Efficient Neural Architecture Search methods based on weight sharing have shown good promise in democratizing Neural Architecture Search for computer vision models. There is, however, an ongoing debate whether these efficient methods are significantly better than random search. Here we perform a thorough comparison between efficient and random search methods on a family of progressively larger and more challenging search spaces for image classification and detection on ImageNet and COCO. While the efficacies of both methods are problem-dependent, our experiments demonstrate that there are large, realistic tasks where efficient search methods can provide substantial gains over random search. In addition, we propose and evaluate techniques which improve the quality of searched architectures and reduce the need for manual hyper-parameter tuning. Source code and experiment data are available at https://github.com/google-research/google-research/tree/master/tunas
* Published at CVPR 2020
MobileDets: Searching for Object Detection Architectures for Mobile Accelerators
Apr 30, 2020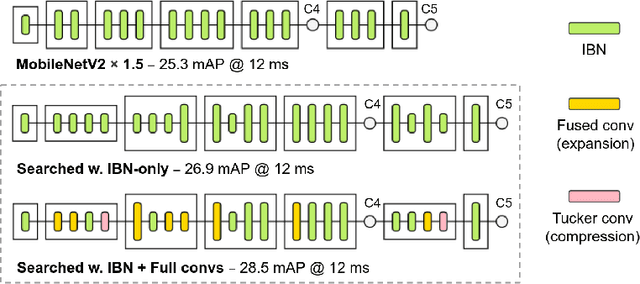
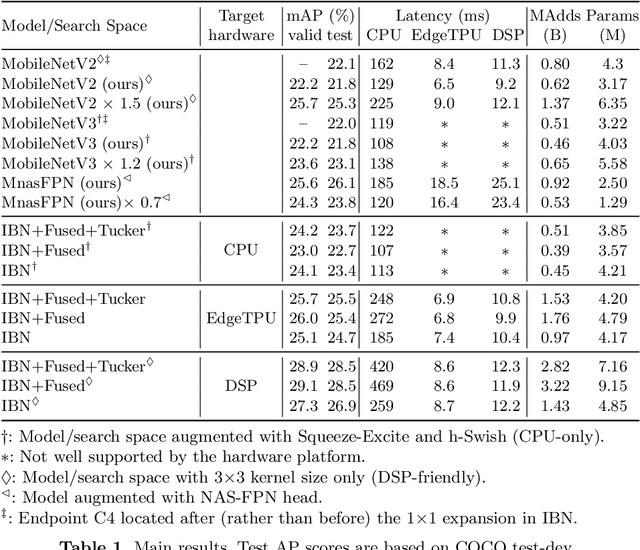
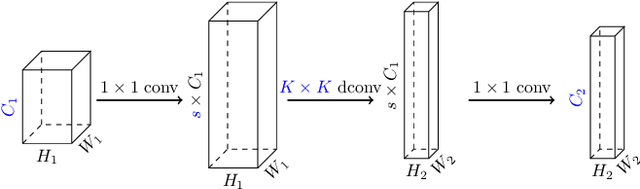
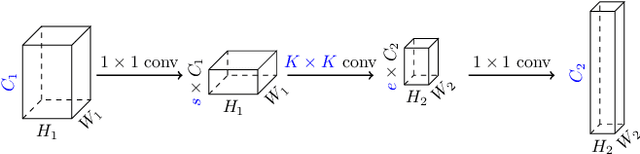
Inverted bottleneck layers, which are built upon depthwise convolutions, have been the predominant building blocks in state-of-the-art object detection models on mobile devices. In this work, we question the optimality of this design pattern over a broad range of mobile accelerators by revisiting the usefulness of regular convolutions. We achieve substantial improvements in the latency-accuracy trade-off by incorporating regular convolutions in the search space, and effectively placing them in the network via neural architecture search. We obtain a family of object detection models, MobileDets, that achieve state-of-the-art results across mobile accelerators. On the COCO object detection task, MobileDets outperform MobileNetV3+SSDLite by 1.7 mAP at comparable mobile CPU inference latencies. MobileDets also outperform MobileNetV2+SSDLite by 1.9 mAP on mobile CPUs, 3.7 mAP on EdgeTPUs and 3.4 mAP on DSPs while running equally fast. Moreover, MobileDets are comparable with the state-of-the-art MnasFPN on mobile CPUs even without using the feature pyramid, and achieve better mAP scores on both EdgeTPUs and DSPs with up to 2X speedup.
BigNAS: Scaling Up Neural Architecture Search with Big Single-Stage Models
Mar 24, 2020
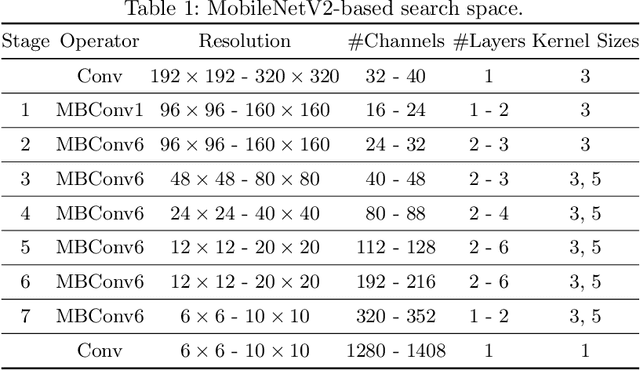
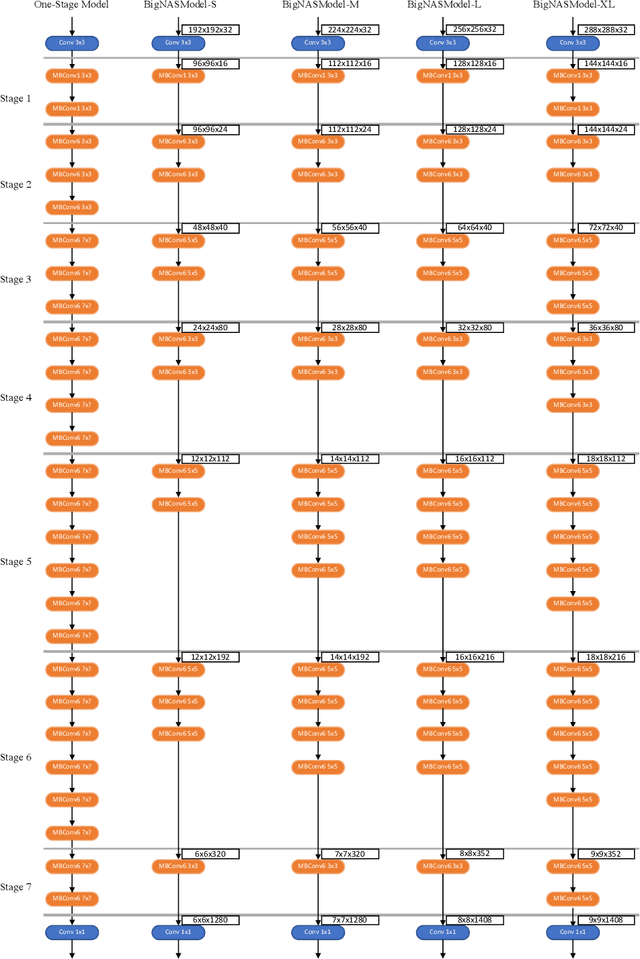
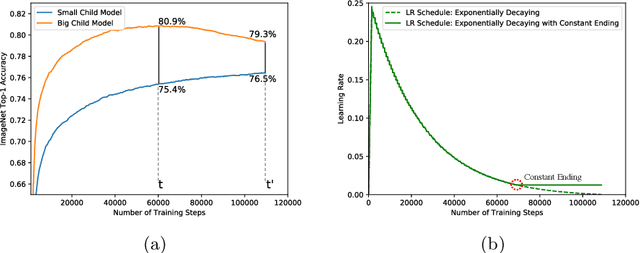
Neural architecture search (NAS) has shown promising results discovering models that are both accurate and fast. For NAS, training a one-shot model has become a popular strategy to rank the relative quality of different architectures (child models) using a single set of shared weights. However, while one-shot model weights can effectively rank different network architectures, the absolute accuracies from these shared weights are typically far below those obtained from stand-alone training. To compensate, existing methods assume that the weights must be retrained, finetuned, or otherwise post-processed after the search is completed. These steps significantly increase the compute requirements and complexity of the architecture search and model deployment. In this work, we propose BigNAS, an approach that challenges the conventional wisdom that post-processing of the weights is necessary to get good prediction accuracies. Without extra retraining or post-processing steps, we are able to train a single set of shared weights on ImageNet and use these weights to obtain child models whose sizes range from 200 to 1000 MFLOPs. Our discovered model family, BigNASModels, achieve top-1 accuracies ranging from 76.5% to 80.9%, surpassing state-of-the-art models in this range including EfficientNets and Once-for-All networks without extra retraining or post-processing. We present ablative study and analysis to further understand the proposed BigNASModels.
Neural Predictor for Neural Architecture Search
Dec 02, 2019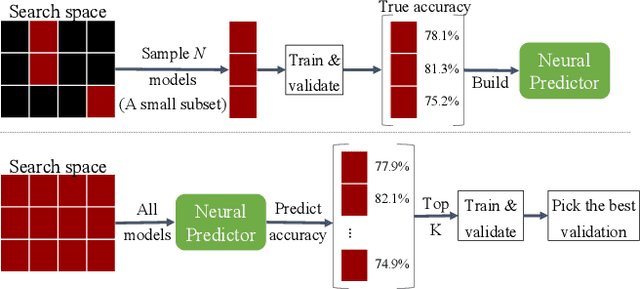
Neural Architecture Search methods are effective but often use complex algorithms to come up with the best architecture. We propose an approach with three basic steps that is conceptually much simpler. First we train N random architectures to generate N (architecture, validation accuracy) pairs and use them to train a regression model that predicts accuracy based on the architecture. Next, we use this regression model to predict the validation accuracies of a large number of random architectures. Finally, we train the top-K predicted architectures and deploy the model with the best validation result. While this approach seems simple, it is more than 20 times as sample efficient as Regularized Evolution on the NASBench-101 benchmark and can compete on ImageNet with more complex approaches based on weight sharing, such as ProxylessNAS.
Soft Conditional Computation
Apr 10, 2019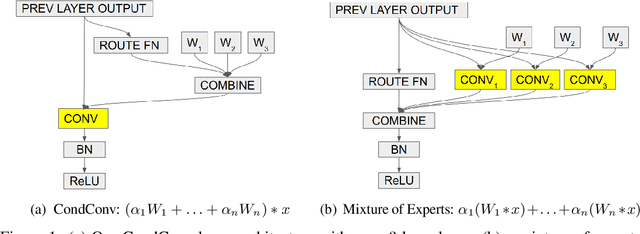
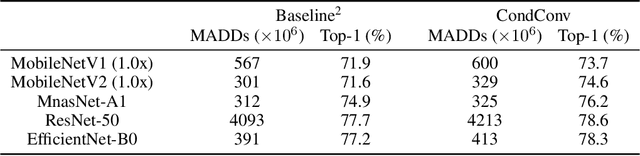
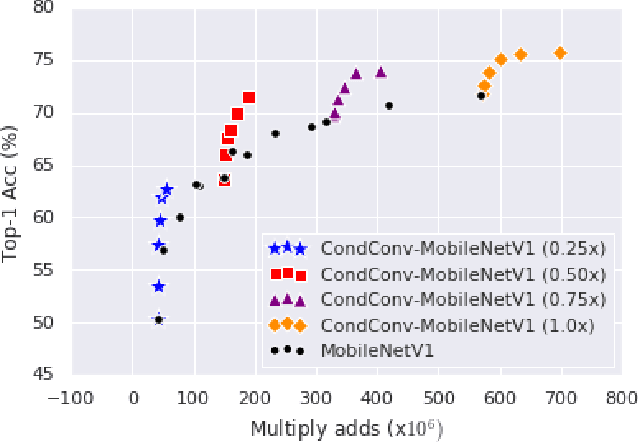

Conditional computation aims to increase the size and accuracy of a network, at a small increase in inference cost. Previous hard-routing models explicitly route the input to a subset of experts. We propose soft conditional computation, which, in contrast, utilizes all experts while still permitting efficient inference through parameter routing. Concretely, for a given convolutional layer, we wish to compute a linear combination of $n$ experts $\alpha_1 \cdot (W_1 * x) + \ldots + \alpha_n \cdot (W_n * x)$, where $\alpha_1, \ldots, \alpha_n$ are functions of the input learned through gradient descent. A straightforward evaluation requires $n$ convolutions. We propose an equivalent form of the above computation, $(\alpha_1 W_1 + \ldots + \alpha_n W_n) * x$, which requires only a single convolution. We demonstrate the efficacy of our method, named CondConv, by scaling up the MobileNetV1, MobileNetV2, and ResNet-50 model architectures to achieve higher accuracy while retaining efficient inference. On the ImageNet classification dataset, CondConv improves the top-1 validation accuracy of the MobileNetV1(0.5x) model from 63.8% to 71.6% while only increasing inference cost by 27%. On COCO object detection, CondConv improves the minival mAP of a MobileNetV1(1.0x) SSD model from 20.3 to 22.4 with just a 4% increase in inference cost.