 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Retrieval-Augmented Generation for Medicine: A Large-Scale, Systematic Expert Evaluation and Practical Insights
Nov 10, 2025Large language models (LLMs) are transforming the landscape of medicine, yet two fundamental challenges persist: keeping up with rapidly evolving medical knowledge and providing verifiable, evidence-grounded reasoning. Retrieval-augmented generation (RAG) has been widely adopted to address these limitations by supplementing model outputs with retrieved evidence. However, whether RAG reliably achieves these goals remains unclear. Here, we present the most comprehensive expert evaluation of RAG in medicine to date. Eighteen medical experts contributed a total of 80,502 annotations, assessing 800 model outputs generated by GPT-4o and Llama-3.1-8B across 200 real-world patient and USMLE-style queries. We systematically decomposed the RAG pipeline into three components: (i) evidence retrieval (relevance of retrieved passages), (ii) evidence selection (accuracy of evidence usage), and (iii) response generation (factuality and completeness of outputs). Contrary to expectation, standard RAG often degraded performance: only 22% of top-16 passages were relevant, evidence selection remained weak (precision 41-43%, recall 27-49%), and factuality and completeness dropped by up to 6% and 5%, respectively, compared with non-RAG variants. Retrieval and evidence selection remain key failure points for the model, contributing to the overall performance drop. We further show that simple yet effective strategies, including evidence filtering and query reformulation, substantially mitigate these issues, improving performance on MedMCQA and MedXpertQA by up to 12% and 8.2%, respectively. These findings call for re-examining RAG's role in medicine and highlight the importance of stage-aware evaluation and deliberate system design for reliable medical LLM applications.
AgentMD: Empowering Language Agents for Risk Prediction with Large-Scale Clinical Tool Learning
Feb 20, 2024Clinical calculators play a vital role in healthcare by offering accurate evidence-based predictions for various purposes such as prognosis. Nevertheless, their widespread utilization is frequently hindered by usability challenges, poor dissemination, and restricted functionality. Augmenting large language models with extensive collections of clinical calculators presents an opportunity to overcome these obstacles and improve workflow efficiency, but the scalability of the manual curation process poses a significant challenge. In response, we introduce AgentMD, a novel language agent capable of curating and applying clinical calculators across various clinical contexts. Using the published literature, AgentMD has automatically curated a collection of 2,164 diverse clinical calculators with executable functions and structured documentation, collectively named RiskCalcs. Manual evaluations show that RiskCalcs tools achieve an accuracy of over 80% on three quality metrics. At inference time, AgentMD can automatically select and apply the relevant RiskCalcs tools given any patient description. On the newly established RiskQA benchmark, AgentMD significantly outperforms chain-of-thought prompting with GPT-4 (87.7% vs. 40.9% in accuracy). Additionally, we also applied AgentMD to real-world clinical notes for analyzing both population-level and risk-level patient characteristics. In summary, our study illustrates the utility of language agents augmented with clinical calculators for healthcare analytics and patient care.
Revisiting Hierarchical Approach for Persistent Long-Term Video Prediction
Apr 14, 2021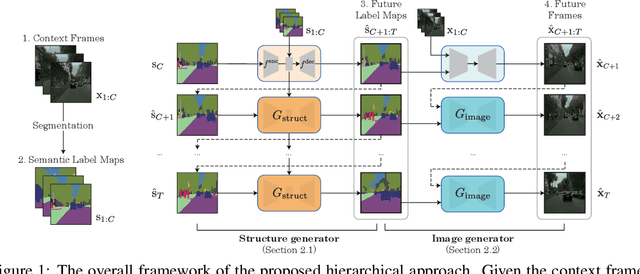
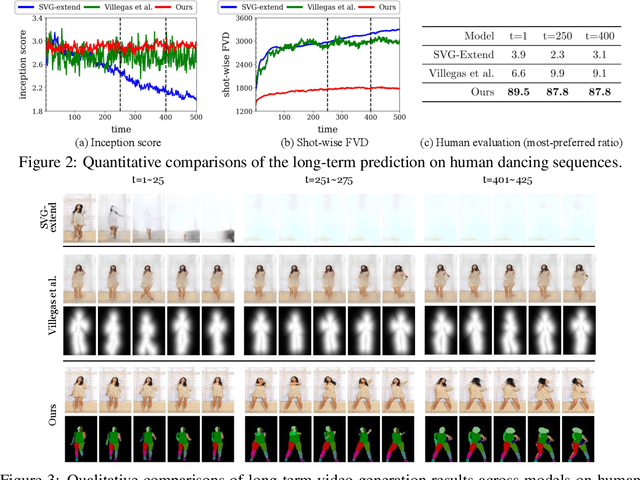
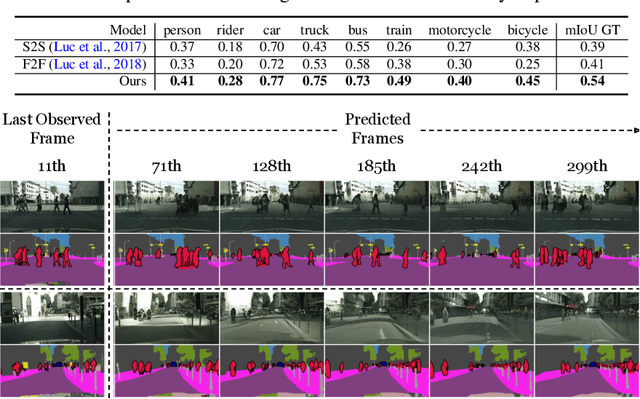
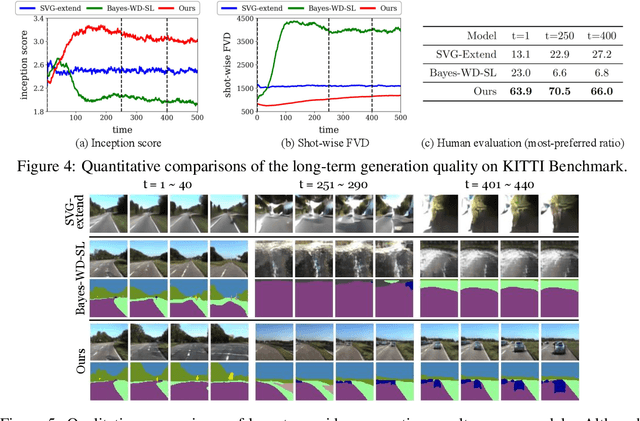
Learning to predict the long-term future of video frames is notoriously challenging due to inherent ambiguities in the distant future and dramatic amplifications of prediction error through time. Despite the recent advances in the literature, existing approaches are limited to moderately short-term prediction (less than a few seconds), while extrapolating it to a longer future quickly leads to destruction in structure and content. In this work, we revisit hierarchical models in video prediction. Our method predicts future frames by first estimating a sequence of semantic structures and subsequently translating the structures to pixels by video-to-video translation. Despite the simplicity, we show that modeling structures and their dynamics in the discrete semantic structure space with a stochastic recurrent estimator leads to surprisingly successful long-term prediction. We evaluate our method on three challenging datasets involving car driving and human dancing, and demonstrate that it can generate complicated scene structures and motions over a very long time horizon (i.e., thousands frames), setting a new standard of video prediction with orders of magnitude longer prediction time than existing approaches. Full videos and codes are available at https://1konny.github.io/HVP/.
Inner Cell Mass and Trophectoderm Segmentation in Human Blastocyst Images using Deep Neural Network
Aug 19, 2020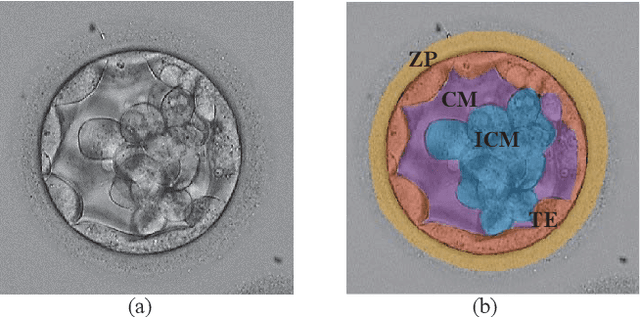

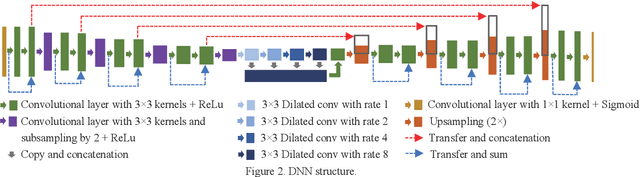

Embryo quality assessment based on morphological attributes is important for achieving higher pregnancy rates from in vitro fertilization (IVF). The accurate segmentation of the embryo's inner cell mass (ICM) and trophectoderm epithelium (TE) is important, as these parameters can help to predict the embryo viability and live birth potential. However, segmentation of the ICM and TE is difficult due to variations in their shape and similarities in their textures, both with each other and with their surroundings. To tackle this problem, a deep neural network (DNN) based segmentation approach was implemented. The DNN can identify the ICM region with 99.1% accuracy, 94.9% precision, 93.8% recall, a 94.3% Dice Coefficient, and a 89.3% Jaccard Index. It can extract the TE region with 98.3% accuracy, 91.8% precision, 93.2% recall, a 92.5% Dice Coefficient, and a 85.3% Jaccard Index.
Image Segmentation of Zona-Ablated Human Blastocysts
Aug 19, 2020

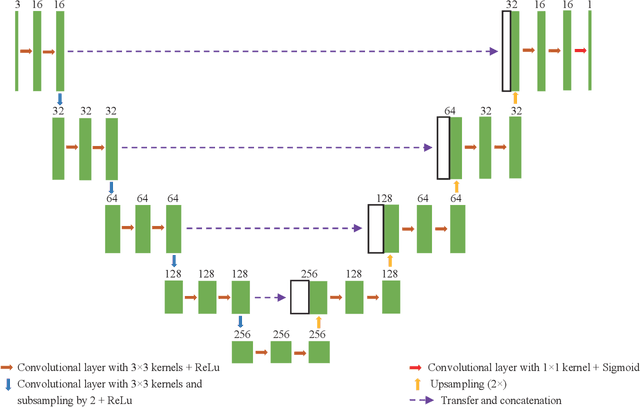
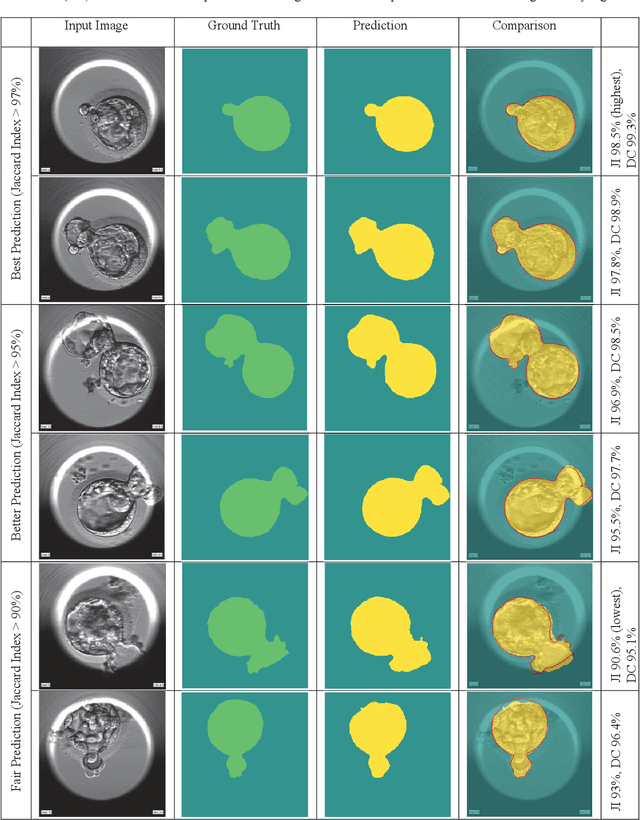
Automating human preimplantation embryo grading offers the potential for higher success rates with in vitro fertilization (IVF) by providing new quantitative and objective measures of embryo quality. Current IVF procedures typically use only qualitative manual grading, which is limited in the identification of genetically abnormal embryos. The automatic quantitative assessment of blastocyst expansion can potentially improve sustained pregnancy rates and reduce health risks from abnormal pregnancies through a more accurate identification of genetic abnormality. The expansion rate of a blastocyst is an important morphological feature to determine the quality of a developing embryo. In this work, a deep learning based human blastocyst image segmentation method is presented, with the goal of facilitating the challenging task of segmenting irregularly shaped blastocysts. The type of blastocysts evaluated here has undergone laser ablation of the zona pellucida, which is required prior to trophectoderm biopsy. This complicates the manual measurements of the expanded blastocyst's size, which shows a correlation with genetic abnormalities. The experimental results on the test set demonstrate segmentation greatly improves the accuracy of expansion measurements, resulting in up to 99.4% accuracy, 98.1% precision, 98.8% recall, a 98.4% Dice Coefficient, and a 96.9% Jaccard Index.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020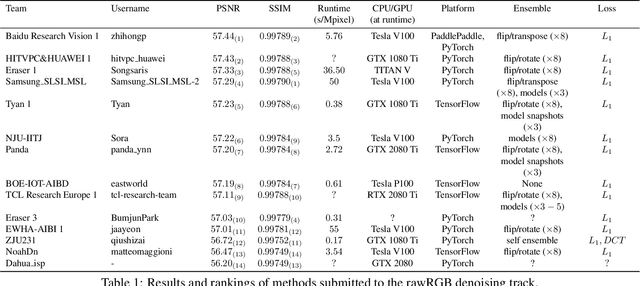
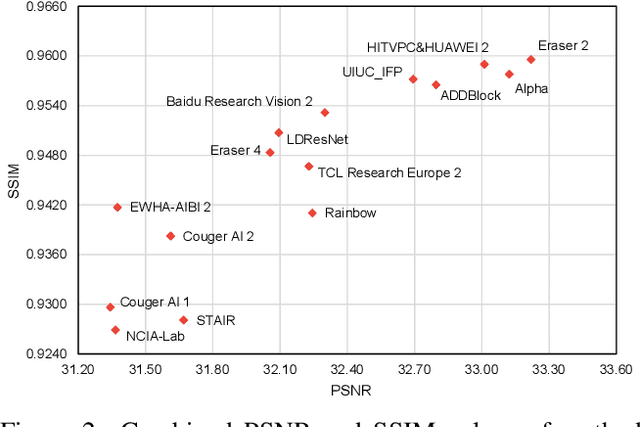
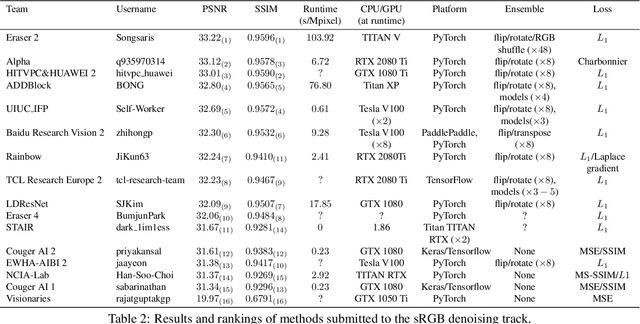
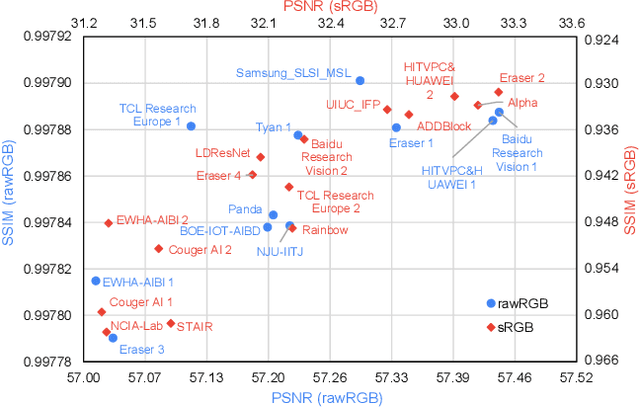
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
BigNAS: Scaling Up Neural Architecture Search with Big Single-Stage Models
Mar 24, 2020
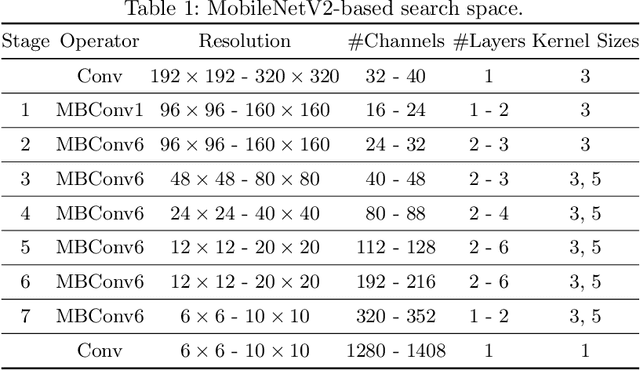
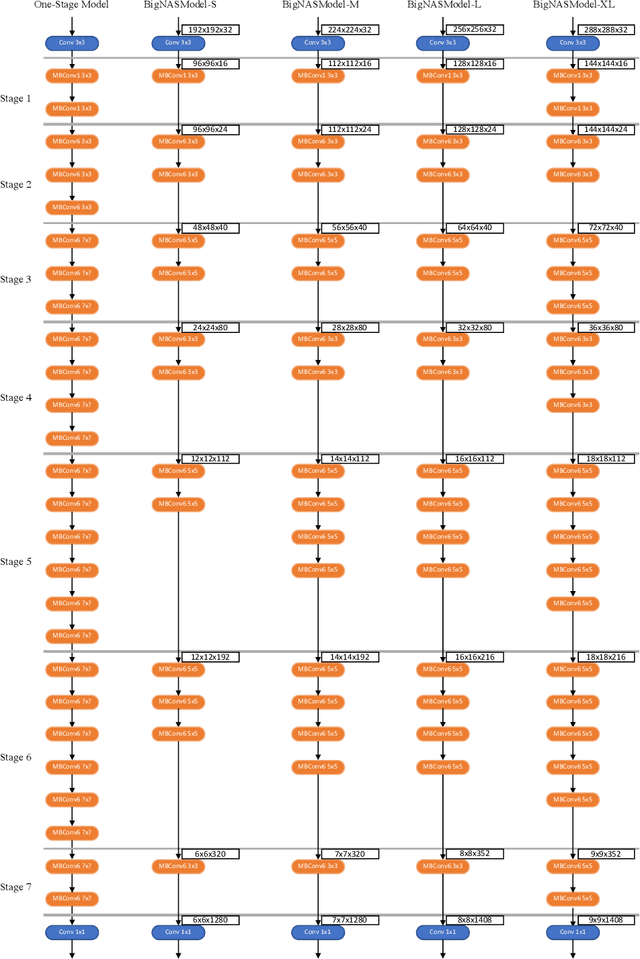
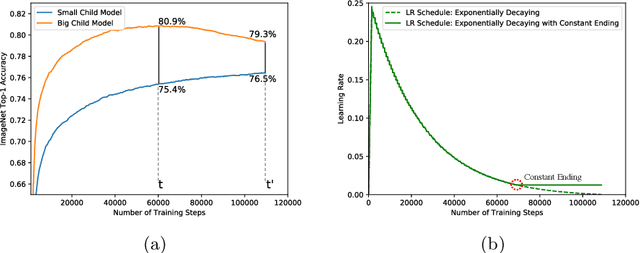
Neural architecture search (NAS) has shown promising results discovering models that are both accurate and fast. For NAS, training a one-shot model has become a popular strategy to rank the relative quality of different architectures (child models) using a single set of shared weights. However, while one-shot model weights can effectively rank different network architectures, the absolute accuracies from these shared weights are typically far below those obtained from stand-alone training. To compensate, existing methods assume that the weights must be retrained, finetuned, or otherwise post-processed after the search is completed. These steps significantly increase the compute requirements and complexity of the architecture search and model deployment. In this work, we propose BigNAS, an approach that challenges the conventional wisdom that post-processing of the weights is necessary to get good prediction accuracies. Without extra retraining or post-processing steps, we are able to train a single set of shared weights on ImageNet and use these weights to obtain child models whose sizes range from 200 to 1000 MFLOPs. Our discovered model family, BigNASModels, achieve top-1 accuracies ranging from 76.5% to 80.9%, surpassing state-of-the-art models in this range including EfficientNets and Once-for-All networks without extra retraining or post-processing. We present ablative study and analysis to further understand the proposed BigNASModels.
FOAL: Fast Online Adaptive Learning for Cardiac Motion Estimation
Mar 10, 2020
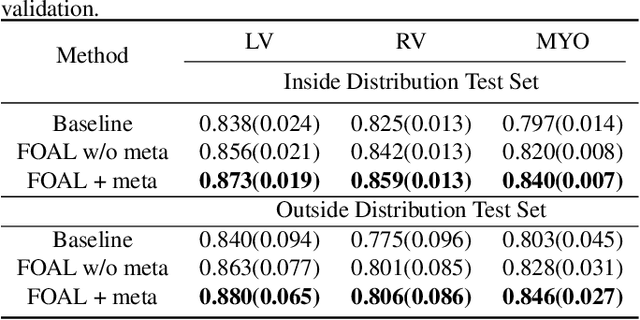

Motion estimation of cardiac MRI videos is crucial for the evaluation of human heart anatomy and function. Recent researches show promising results with deep learning-based methods. In clinical deployment, however, they suffer dramatic performance drops due to mismatched distributions between training and testing datasets, commonly encountered in the clinical environment. On the other hand, it is arguably impossible to collect all representative datasets and to train a universal tracker before deployment. In this context, we proposed a novel fast online adaptive learning (FOAL) framework: an online gradient descent based optimizer that is optimized by a meta-learner. The meta-learner enables the online optimizer to perform a fast and robust adaptation. We evaluated our method through extensive experiments on two public clinical datasets. The results showed the superior performance of FOAL in accuracy compared to the offline-trained tracking method. On average, the FOAL took only $0.4$ second per video for online optimization.
FLNet: Landmark Driven Fetching and Learning Network for Faithful Talking Facial Animation Synthesis
Nov 21, 2019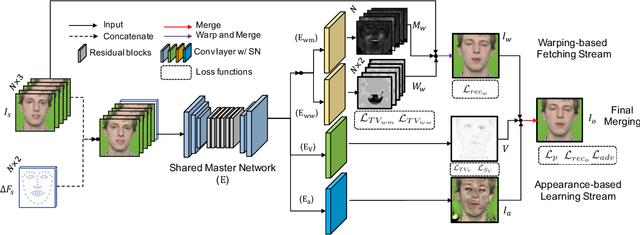
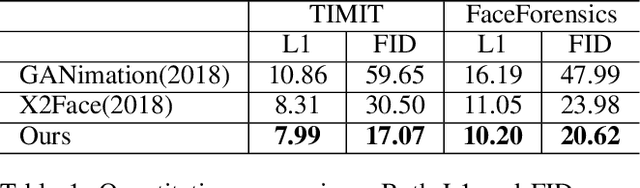


Talking face synthesis has been widely studied in either appearance-based or warping-based methods. Previous works mostly utilize single face image as a source, and generate novel facial animations by merging other person's facial features. However, some facial regions like eyes or teeth, which may be hidden in the source image, can not be synthesized faithfully and stably. In this paper, We present a landmark driven two-stream network to generate faithful talking facial animation, in which more facial details are created, preserved and transferred from multiple source images instead of a single one. Specifically, we propose a network consisting of a learning and fetching stream. The fetching sub-net directly learns to attentively warp and merge facial regions from five source images of distinctive landmarks, while the learning pipeline renders facial organs from the training face space to compensate. Compared to baseline algorithms, extensive experiments demonstrate that the proposed method achieves a higher performance both quantitatively and qualitatively. Codes are at https://github.com/kgu3/FLNet_AAAI2020.
SkyNet: a Hardware-Efficient Method for Object Detection and Tracking on Embedded Systems
Sep 20, 2019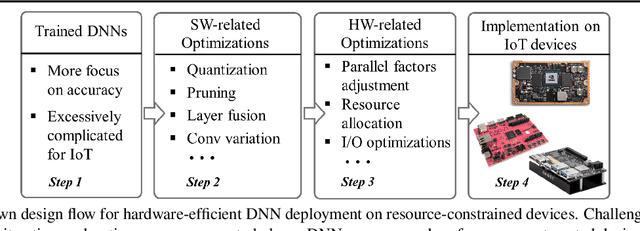
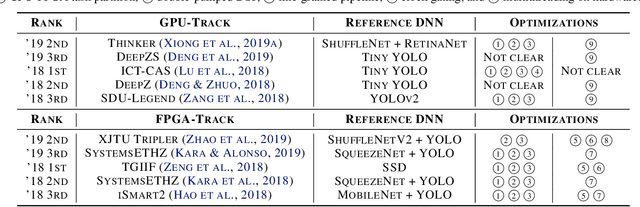

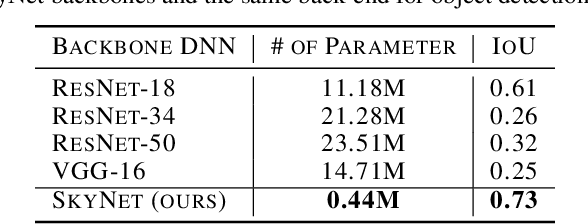
Developing object detection and tracking on resource-constrained embedded systems is challenging. While object detection is one of the most compute-intensive tasks from the artificial intelligence domain, it is only allowed to use limited computation and memory resources on embedded devices. In the meanwhile, such resource-constrained implementations are often required to satisfy additional demanding requirements such as real-time response, high-throughput performance, and reliable inference accuracy. To overcome these challenges, we propose SkyNet, a hardware-efficient method to deliver the state-of-the-art detection accuracy and speed for embedded systems. Instead of following the common top-down flow for compact DNN design, SkyNet provides a bottom-up DNN design approach with comprehensive understanding of the hardware constraints at the very beginning to deliver hardware-efficient DNNs. The effectiveness of SkyNet is demonstrated by winning the extremely competitive System Design Contest for low power object detection in the 56th IEEE/ACM Design Automation Conference (DAC-SDC), where our SkyNet significantly outperforms all other 100+ competitors: it delivers 0.731 Intersection over Union (IoU) and 67.33 frames per second (FPS) on a TX2 embedded GPU; and 0.716 IoU and 25.05 FPS on an Ultra96 embedded FPGA. The evaluation of SkyNet is also extended to GOT-10K, a recent large-scale high-diversity benchmark for generic object tracking in the wild. For state-of-the-art object trackers SiamRPN++ and SiamMask, where ResNet-50 is employed as the backbone, implementations using our SkyNet as the backbone DNN are 1.60X and 1.73X faster with better or similar accuracy when running on a 1080Ti GPU, and 37.20X smaller in terms of parameter size for significantly better memory and storage footprint.