 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSE: Illustrating Textual Attributes by Portrait Generation
Nov 09, 2020
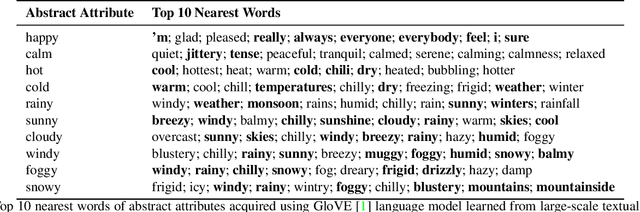

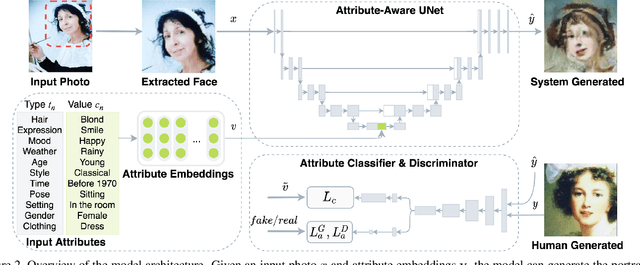
We propose a novel approach, MUSE, to illustrate textual attributes visually via portrait generation. MUSE takes a set of attributes written in text, in addition to facial features extracted from a photo of the subject as input. We propose 11 attribute types to represent inspirations from a subject's profile, emotion, story, and environment. We propose a novel stacked neural network architecture by extending an image-to-image generative model to accept textual attributes. Experiments show that our approach significantly outperforms several state-of-the-art methods without using textual attributes, with Inception Score score increased by 6% and Fr\'echet Inception Distance (FID) score decreased by 11%, respectively. We also propose a new attribute reconstruction metric to evaluate whether the generated portraits preserve the subject's attributes. Experiments show that our approach can accurately illustrate 78% textual attributes, which also help MUSE capture the subject in a more creative and expressive way.
The 1st Agriculture-Vision Challenge: Methods and Results
Apr 23, 2020
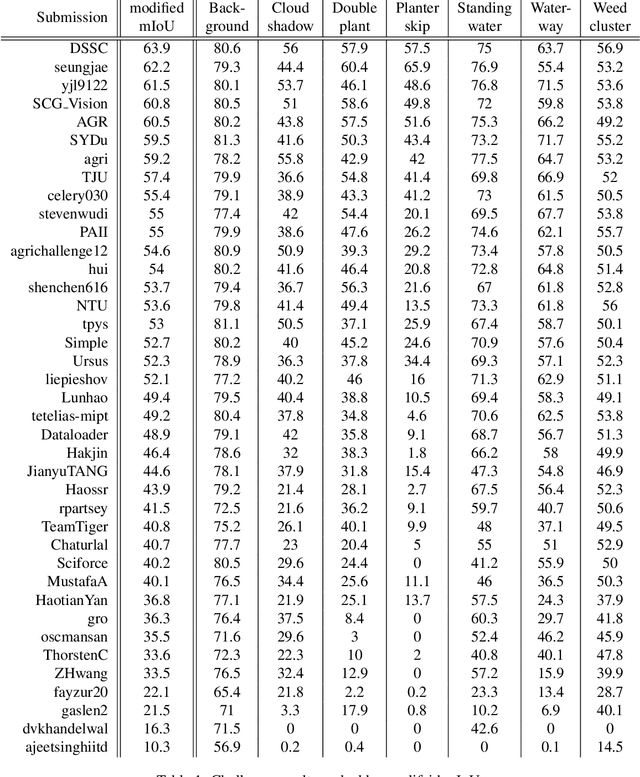
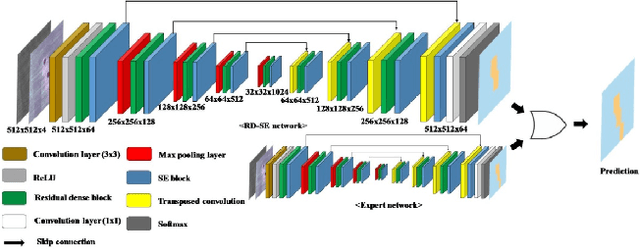
The first Agriculture-Vision Challenge aims to encourage research in developing novel and effective algorithms for agricultural pattern recognition from aerial images, especially for the semantic segmentation task associated with our challenge dataset. Around 57 participating teams from various countries compete to achieve state-of-the-art in aerial agriculture semantic segmentation. The Agriculture-Vision Challenge Dataset was employed, which comprises of 21,061 aerial and multi-spectral farmland images. This paper provides a summary of notable methods and results in the challenge. Our submission server and leaderboard will continue to open for researchers that are interested in this challenge dataset and task; the link can be found here.
Differential Treatment for Stuff and Things: A Simple Unsupervised Domain Adaptation Method for Semantic Segmentation
Apr 22, 2020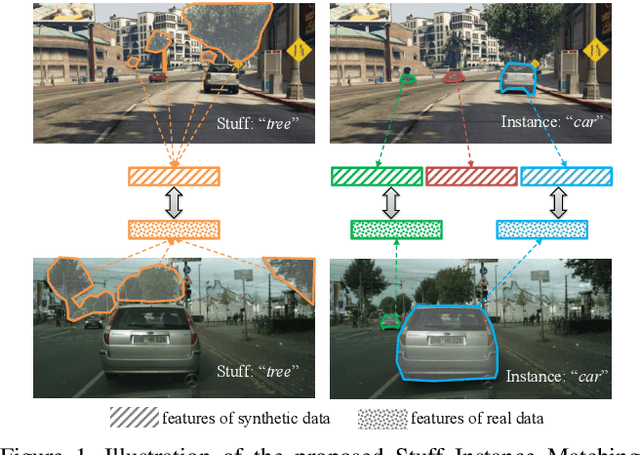

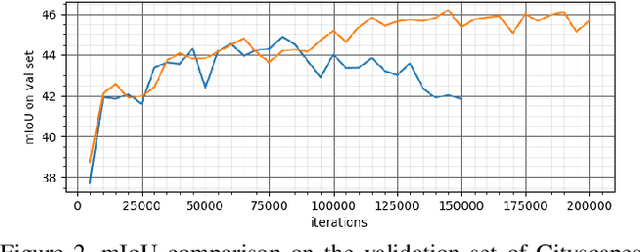
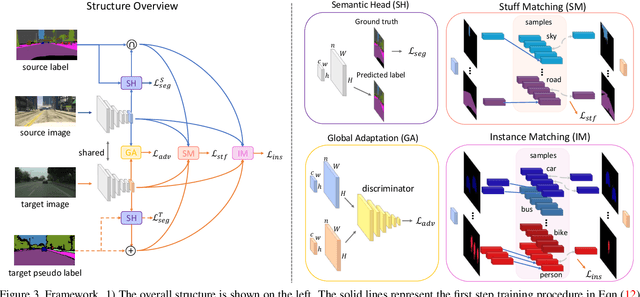
We consider the problem of unsupervised domain adaptation for semantic segmentation by easing the domain shift between the source domain (synthetic data) and the target domain (real data) in this work. State-of-the-art approaches prove that performing semantic-level alignment is helpful in tackling the domain shift issue. Based on the observation that stuff categories usually share similar appearances across images of different domains while things (i.e. object instances) have much larger differences, we propose to improve the semantic-level alignment with different strategies for stuff regions and for things: 1) for the stuff categories, we generate feature representation for each class and conduct the alignment operation from the target domain to the source domain; 2) for the thing categories, we generate feature representation for each individual instance and encourage the instance in the target domain to align with the most similar one in the source domain. In this way, the individual differences within thing categories will also be considered to alleviate over-alignment. In addition to our proposed method, we further reveal the reason why the current adversarial loss is often unstable in minimizing the distribution discrepancy and show that our method can help ease this issue by minimizing the most similar stuff and instance features between the source and the target domains. We conduct extensive experiments in two unsupervised domain adaptation tasks, i.e. GTA5 to Cityscapes and SYNTHIA to Cityscapes, and achieve the new state-of-the-art segmentation accuracy.
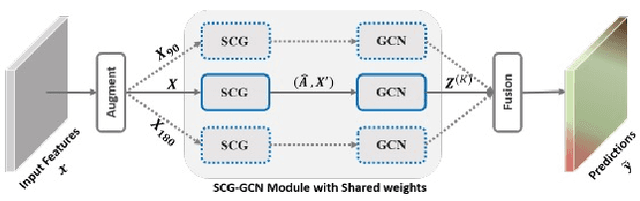
Alleviating Semantic-level Shift: A Semi-supervised Domain Adaptation Method for Semantic Segmentation
Apr 02, 2020
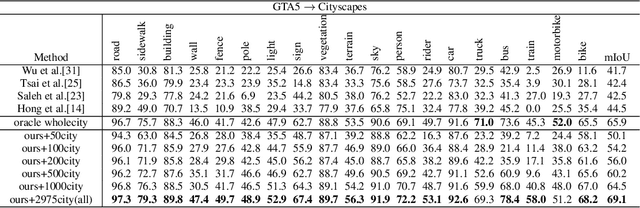
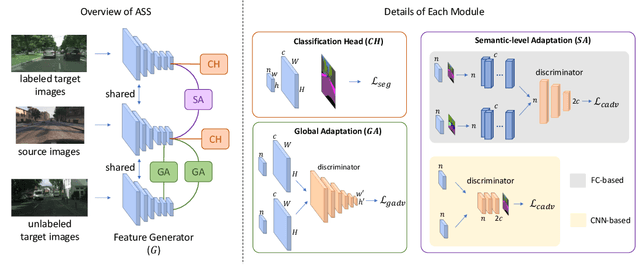
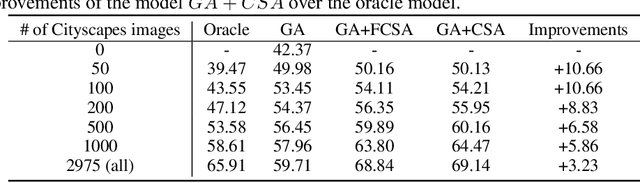
Learning segmentation from synthetic data and adapting to real data can significantly relieve human efforts in labelling pixel-level masks. A key challenge of this task is how to alleviate the data distribution discrepancy between the source and target domains, i.e. reducing domain shift. The common approach to this problem is to minimize the discrepancy between feature distributions from different domains through adversarial training. However, directly aligning the feature distribution globally cannot guarantee consistency from a local view (i.e. semantic-level), which prevents certain semantic knowledge learned on the source domain from being applied to the target domain. To tackle this issue, we propose a semi-supervised approach named Alleviating Semantic-level Shift (ASS), which can successfully promote the distribution consistency from both global and local views. Specifically, leveraging a small number of labeled data from the target domain, we directly extract semantic-level feature representations from both the source and the target domains by averaging the features corresponding to same categories advised by pixel-level masks. We then feed the produced features to the discriminator to conduct semantic-level adversarial learning, which collaborates with the adversarial learning from the global view to better alleviate the domain shift. We apply our ASS to two domain adaptation tasks, from GTA5 to Cityscapes and from Synthia to Cityscapes. Extensive experiments demonstrate that: (1) ASS can significantly outperform the current unsupervised state-of-the-arts by employing a small number of annotated samples from the target domain; (2) ASS can beat the oracle model trained on the whole target dataset by over 3 points by augmenting the synthetic source data with annotated samples from the target domain without suffering from the prevalent problem of overfitting to the source domain.
Laplacian Denoising Autoencoder
Mar 30, 2020
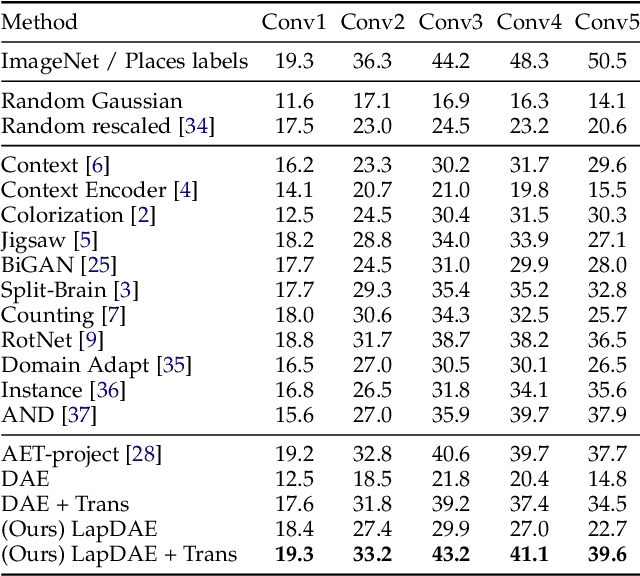

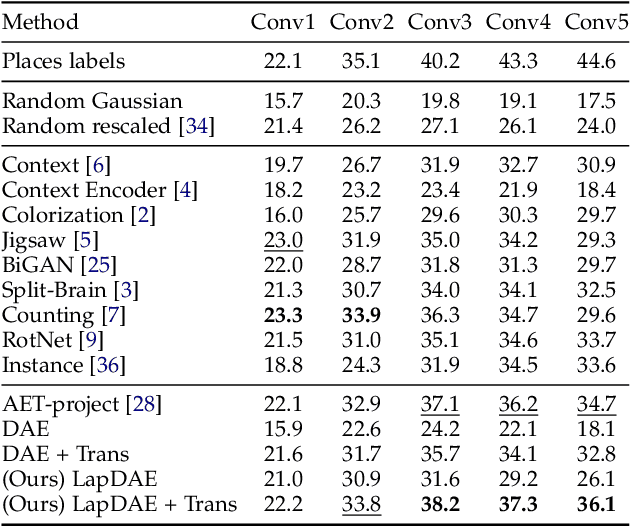
While deep neural networks have been shown to perform remarkably well in many machine learning tasks, labeling a large amount of ground truth data for supervised training is usually very costly to scale. Therefore, learning robust representations with unlabeled data is critical in relieving human effort and vital for many downstream tasks. Recent advances in unsupervised and self-supervised learning approaches for visual data have benefited greatly from domain knowledge. Here we are interested in a more generic unsupervised learning framework that can be easily generalized to other domains. In this paper, we propose to learn data representations with a novel type of denoising autoencoder, where the noisy input data is generated by corrupting latent clean data in the gradient domain. This can be naturally generalized to span multiple scales with a Laplacian pyramid representation of the input data. In this way, the agent learns more robust representations that exploit the underlying data structures across multiple scales. Experiments on several visual benchmarks demonstrate that better representations can be learned with the proposed approach, compared to its counterpart with single-scale corruption and other approaches. Furthermore, we also demonstrate that the learned representations perform well when transferring to other downstream vision tasks.
Deep Affinity Net: Instance Segmentation via Affinity
Mar 15, 2020
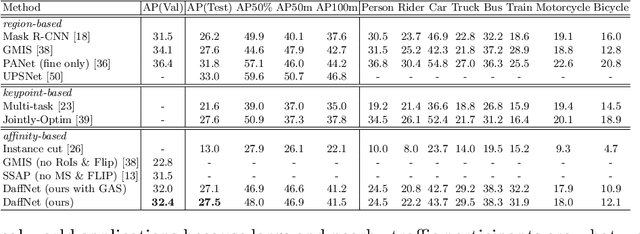
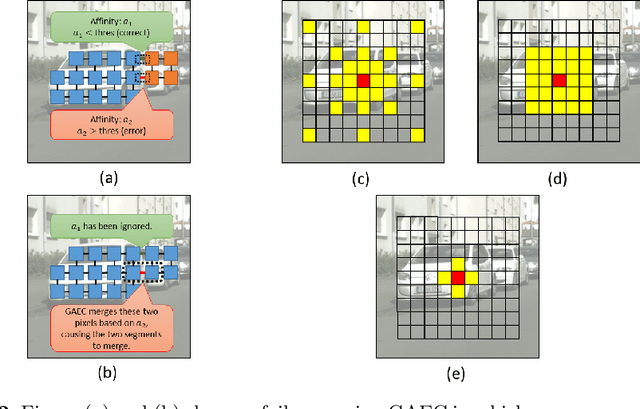

Most of the modern instance segmentation approaches fall into two categories: region-based approaches in which object bounding boxes are detected first and later used in cropping and segmenting instances; and keypoint-based approaches in which individual instances are represented by a set of keypoints followed by a dense pixel clustering around those keypoints. Despite the maturity of these two paradigms, we would like to report an alternative affinity-based paradigm where instances are segmented based on densely predicted affinities and graph partitioning algorithms. Such affinity-based approaches indicate that high-level graph features other than regions or keypoints can be directly applied in the instance segmentation task. In this work, we propose Deep Affinity Net, an effective affinity-based approach accompanied with a new graph partitioning algorithm Cascade-GAEC. Without bells and whistles, our end-to-end model results in 32.4% AP on Cityscapes val and 27.5% AP on test. It achieves the best single-shot result as well as the fastest running time among all affinity-based models. It also outperforms the region-based method Mask R-CNN.
FOAL: Fast Online Adaptive Learning for Cardiac Motion Estimation
Mar 10, 2020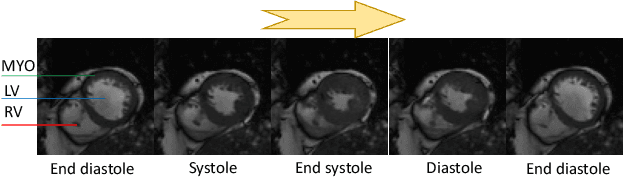
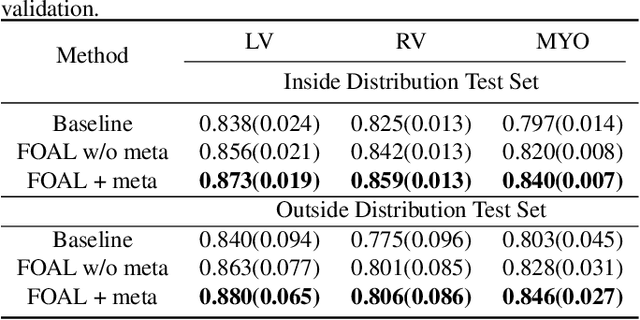
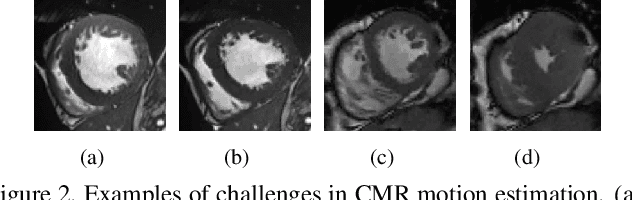

Motion estimation of cardiac MRI videos is crucial for the evaluation of human heart anatomy and function. Recent researches show promising results with deep learning-based methods. In clinical deployment, however, they suffer dramatic performance drops due to mismatched distributions between training and testing datasets, commonly encountered in the clinical environment. On the other hand, it is arguably impossible to collect all representative datasets and to train a universal tracker before deployment. In this context, we proposed a novel fast online adaptive learning (FOAL) framework: an online gradient descent based optimizer that is optimized by a meta-learner. The meta-learner enables the online optimizer to perform a fast and robust adaptation. We evaluated our method through extensive experiments on two public clinical datasets. The results showed the superior performance of FOAL in accuracy compared to the offline-trained tracking method. On average, the FOAL took only $0.4$ second per video for online optimization.
AlignSeg: Feature-Aligned Segmentation Networks
Feb 24, 2020
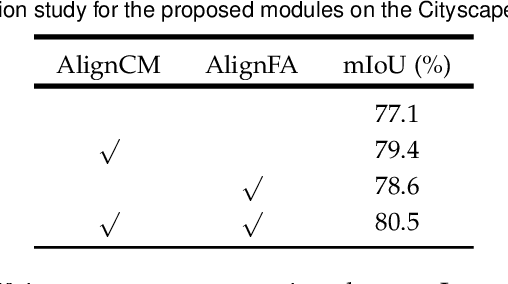
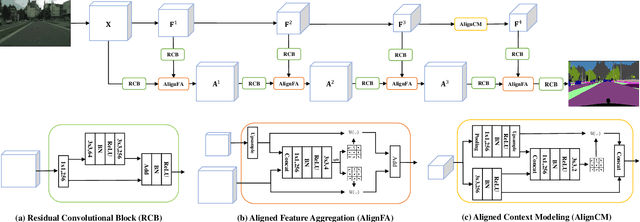
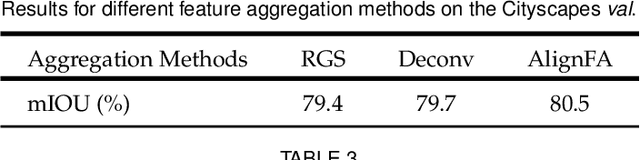
Aggregating features in terms of different convolutional blocks or contextual embeddings has been proven to be an effective way to strengthen feature representations for semantic segmentation. However, most of the current popular network architectures tend to ignore the misalignment issues during the feature aggregation process caused by 1) step-by-step downsampling operations, and 2) indiscriminate contextual information fusion. In this paper, we explore the principles in addressing such feature misalignment issues and inventively propose Feature-Aligned Segmentation Networks (AlignSeg). AlignSeg consists of two primary modules, i.e., the Aligned Feature Aggregation (AlignFA) module and the Aligned Context Modeling (AlignCM) module. First, AlignFA adopts a simple learnable interpolation strategy to learn transformation offsets of pixels, which can effectively relieve the feature misalignment issue caused by multiresolution feature aggregation. Second, with the contextual embeddings in hand, AlignCM enables each pixel to choose private custom contextual information in an adaptive manner, making the contextual embeddings aligned better to provide appropriate guidance. We validate the effectiveness of our AlignSeg network with extensive experiments on Cityscapes and ADE20K, achieving new state-of-the-art mIoU scores of 82.6% and 45.95%, respectively. Our source code will be made available.
Agriculture-Vision: A Large Aerial Image Database for Agricultural Pattern Analysis
Jan 05, 2020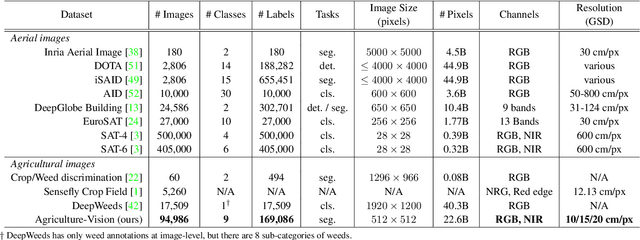


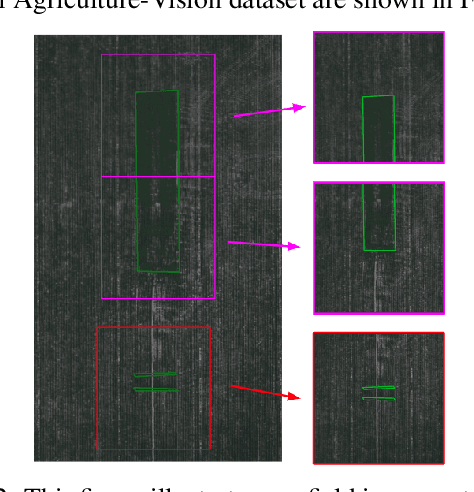
The success of deep learning in visual recognition tasks has driven advancements in multiple fields of research. Particularly, increasing attention has been drawn towards its application in agriculture. Nevertheless, while visual pattern recognition on farmlands carries enormous economic values, little progress has been made to merge computer vision and crop sciences due to the lack of suitable agricultural image datasets. Meanwhile, problems in agriculture also pose new challenges in computer vision. For example, semantic segmentation of aerial farmland images requires inference over extremely large-size images with extreme annotation sparsity. These challenges are not present in most of the common object datasets, and we show that they are more challenging than many other aerial image datasets. To encourage research in computer vision for agriculture, we present Agriculture-Vision: a large-scale aerial farmland image dataset for semantic segmentation of agricultural patterns. We collected 94,986 high-quality aerial images from 3,432 farmlands across the US, where each image consists of RGB and Near-infrared (NIR) channels with resolution as high as 10 cm per pixel. We annotate nine types of field anomaly patterns that are most important to farmers. As a pilot study of aerial agricultural semantic segmentation, we perform comprehensive experiments using popular semantic segmentation models; we also propose an effective model designed for aerial agricultural pattern recognition. Our experiments demonstrate several challenges Agriculture-Vision poses to both the computer vision and agriculture communities. Future versions of this dataset will include even more aerial images, anomaly patterns and image channels. More information at https://www.agriculture-vision.com.
Any-Precision Deep Neural Networks
Nov 17, 2019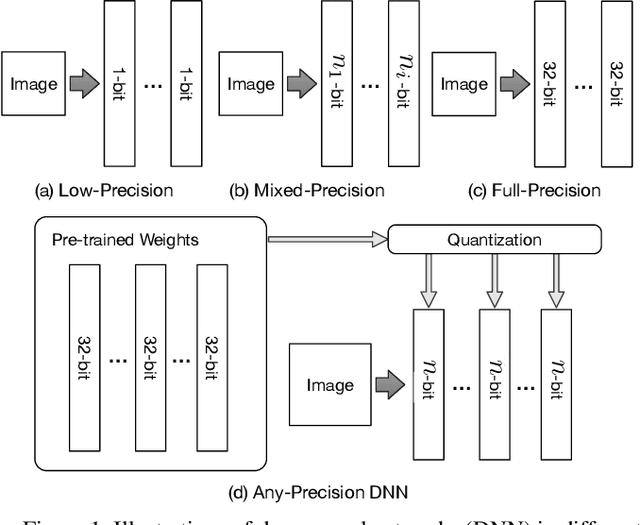
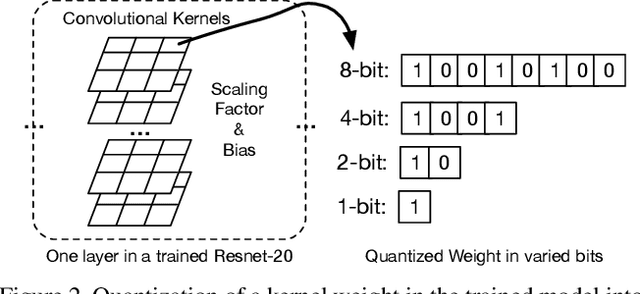

We present Any-Precision Deep Neural Networks (Any-Precision DNNs), which are trained with a new method that empowers learned DNNs to be flexible in any numerical precision during inference. The same model in runtime can be flexibly and directly set to different bit-width, by truncating the least significant bits, to support dynamic speed and accuracy trade-off. When all layers are set to low-bits, we show that the model achieved accuracy comparable to dedicated models trained at the same precision. This nice property facilitates flexible deployment of deep learning models in real-world applications, where in practice trade-offs between model accuracy and runtime efficiency are often sought. Previous literature presents solutions to train models at each individual fixed efficiency/accuracy trade-off point. But how to produce a model flexible in runtime precision is largely unexplored. When the demand of efficiency/accuracy trade-off varies from time to time or even dynamically changes in runtime, it is infeasible to re-train models accordingly, and the storage budget may forbid keeping multiple models. Our proposed framework achieves this flexibility without performance degradation. More importantly, we demonstrate that this achievement is agnostic to model architectures. We experimentally validated our method with different deep network backbones (AlexNet-small, Resnet-20, Resnet-50) on different datasets (SVHN, Cifar-10, ImageNet) and observed consistent results. Code and models will be available at https://github.com/haichaoyu.