 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o: Visual perception performance of multimodal large language models in piglet activity understanding
Jun 14, 2024Animal ethology is an crucial aspect of animal research, and animal behavior labeling is the foundation for studying animal behavior. This process typically involves labeling video clips with behavioral semantic tags, a task that is complex, subjective, and multimodal. With the rapid development of multimodal large language models(LLMs), new application have emerged for animal behavior understanding tasks in livestock scenarios. This study evaluates the visual perception capabilities of multimodal LLMs in animal activity recognition. To achieve this, we created piglet test data comprising close-up video clips of individual piglets and annotated full-shot video clips. These data were used to assess the performance of four multimodal LLMs-Video-LLaMA, MiniGPT4-Video, Video-Chat2, and GPT-4 omni (GPT-4o)-in piglet activity understanding. Through comprehensive evaluation across five dimensions, including counting, actor referring, semantic correspondence, time perception, and robustness, we found that while current multimodal LLMs require improvement in semantic correspondence and time perception, they have initially demonstrated visual perception capabilities for animal activity recognition. Notably, GPT-4o showed outstanding performance, with Video-Chat2 and GPT-4o exhibiting significantly better semantic correspondence and time perception in close-up video clips compared to full-shot clips. The initial evaluation experiments in this study validate the potential of multimodal large language models in livestock scene video understanding and provide new directions and references for future research on animal behavior video understanding. Furthermore, by deeply exploring the influence of visual prompts on multimodal large language models, we expect to enhance the accuracy and efficiency of animal behavior recognition in livestock scenarios through human visual processing methods.
Tracking Grow-Finish Pigs Across Large Pens Using Multiple Cameras
Nov 22, 2021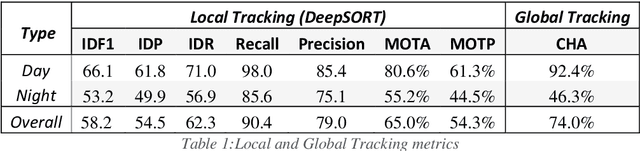
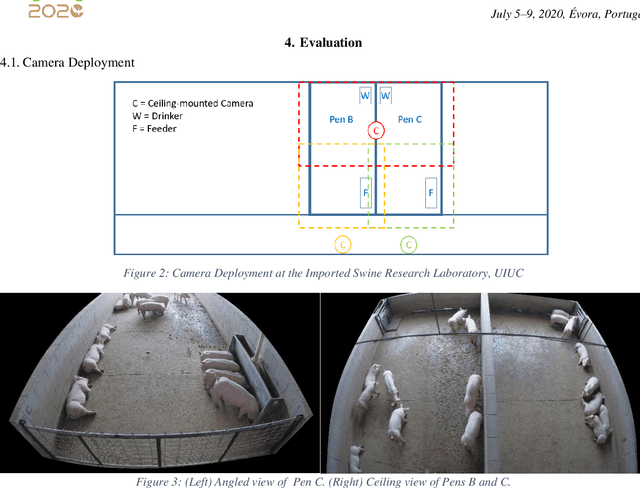


Increasing demand for meat products combined with farm labor shortages has resulted in a need to develop new real-time solutions to monitor animals effectively. Significant progress has been made in continuously locating individual pigs using tracking-by-detection methods. However, these methods fail for oblong pens because a single fixed camera does not cover the entire floor at adequate resolution. We address this problem by using multiple cameras, placed such that the visual fields of adjacent cameras overlap, and together they span the entire floor. Avoiding breaks in tracking requires inter-camera handover when a pig crosses from one camera's view into that of an adjacent camera. We identify the adjacent camera and the shared pig location on the floor at the handover time using inter-view homography. Our experiments involve two grow-finish pens, housing 16-17 pigs each, and three RGB cameras. Our algorithm first detects pigs using a deep learning-based object detection model (YOLO) and creates their local tracking IDs using a multi-object tracking algorithm (DeepSORT). We then use inter-camera shared locations to match multiple views and generate a global ID for each pig that holds throughout tracking. To evaluate our approach, we provide five two-minutes long video sequences with fully annotated global identities. We track pigs in a single camera view with a Multi-Object Tracking Accuracy and Precision of 65.0% and 54.3% respectively and achieve a Camera Handover Accuracy of 74.0%. We open-source our code and annotated dataset at https://github.com/AIFARMS/multi-camera-pig-tracking
Unsupervised 3D Pose Estimation for Hierarchical Dance Video Recognition
Sep 19, 2021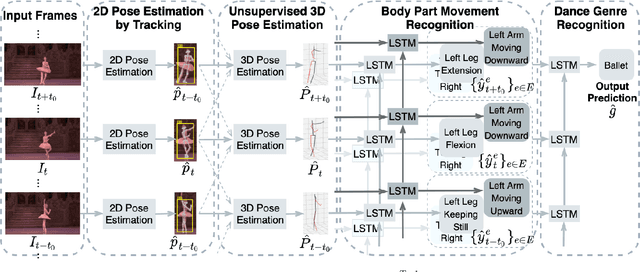

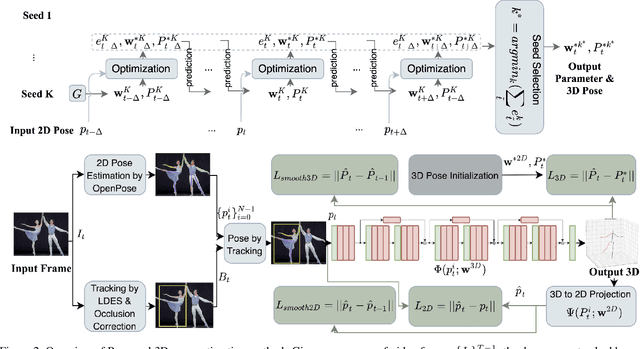
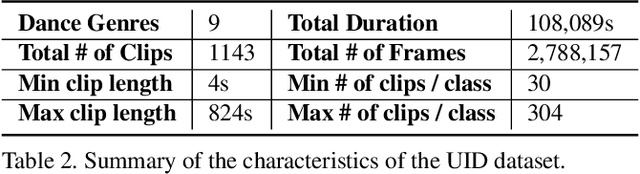
Dance experts often view dance as a hierarchy of information, spanning low-level (raw images, image sequences), mid-levels (human poses and bodypart movements), and high-level (dance genre). We propose a Hierarchical Dance Video Recognition framework (HDVR). HDVR estimates 2D pose sequences, tracks dancers, and then simultaneously estimates corresponding 3D poses and 3D-to-2D imaging parameters, without requiring ground truth for 3D poses. Unlike most methods that work on a single person, our tracking works on multiple dancers, under occlusions. From the estimated 3D pose sequence, HDVR extracts body part movements, and therefrom dance genre. The resulting hierarchical dance representation is explainable to experts. To overcome noise and interframe correspondence ambiguities, we enforce spatial and temporal motion smoothness and photometric continuity over time. We use an LSTM network to extract 3D movement subsequences from which we recognize the dance genre. For experiments, we have identified 154 movement types, of 16 body parts, and assembled a new University of Illinois Dance (UID) Dataset, containing 1143 video clips of 9 genres covering 30 hours, annotated with movement and genre labels. Our experimental results demonstrate that our algorithms outperform the state-of-the-art 3D pose estimation methods, which also enhances our dance recognition performance.
MUSE: Illustrating Textual Attributes by Portrait Generation
Nov 09, 2020
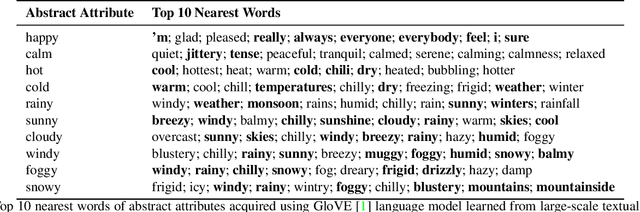

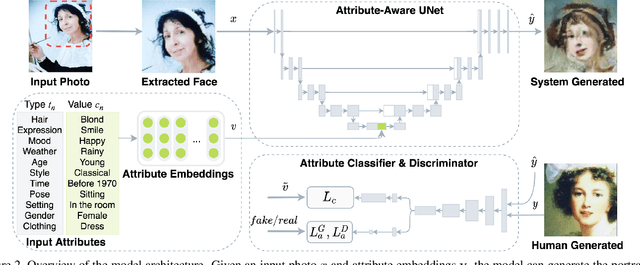
We propose a novel approach, MUSE, to illustrate textual attributes visually via portrait generation. MUSE takes a set of attributes written in text, in addition to facial features extracted from a photo of the subject as input. We propose 11 attribute types to represent inspirations from a subject's profile, emotion, story, and environment. We propose a novel stacked neural network architecture by extending an image-to-image generative model to accept textual attributes. Experiments show that our approach significantly outperforms several state-of-the-art methods without using textual attributes, with Inception Score score increased by 6% and Fr\'echet Inception Distance (FID) score decreased by 11%, respectively. We also propose a new attribute reconstruction metric to evaluate whether the generated portraits preserve the subject's attributes. Experiments show that our approach can accurately illustrate 78% textual attributes, which also help MUSE capture the subject in a more creative and expressive way.
Squeeze-and-Attention Networks for Semantic Segmentation
Sep 10, 2019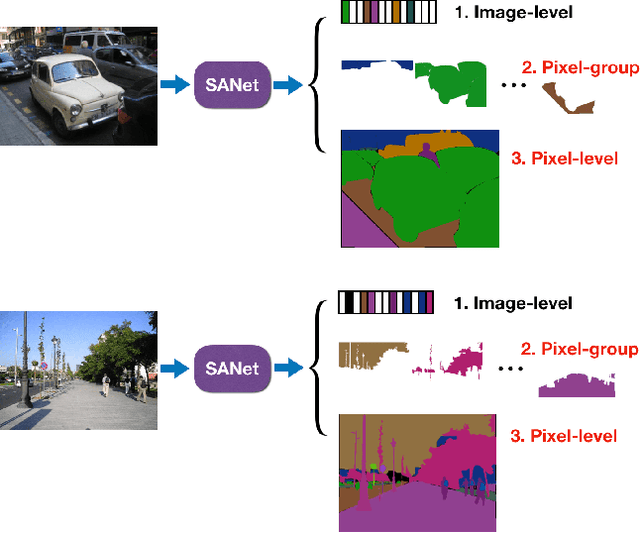
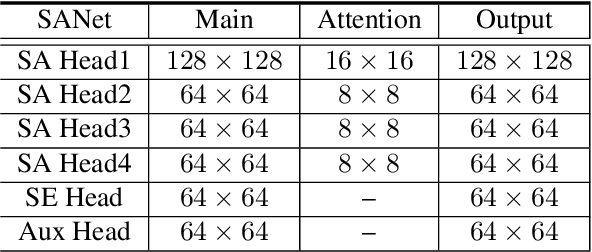

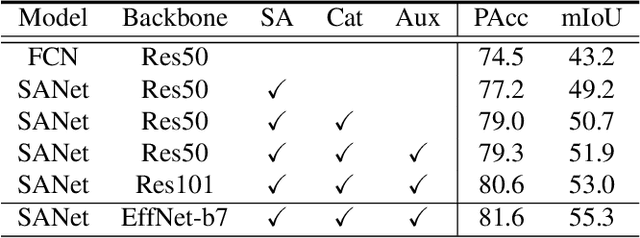
Squeeze-and-excitation (SE) module enhances the representational power of convolution layers by adaptively re-calibrating channel-wise feature responses. However, the limitation of SE in terms of attention characterization lies in the loss of spatial information cues, making it less well suited for perception tasks with very high spatial inter-dependencies such as semantic segmentation. In this paper, we propose a novel squeeze-and-attention network (SANet) architecture that leverages a simple but effective squeeze-and-attention (SA) module to account for two distinctive characteristics of segmentation: i) pixel-group attention, and ii) pixel-wise prediction. Specifically, the proposed SA modules impose pixel-group attention on conventional convolution by introducing an 'attention' convolutional channel, thus taking into account spatial-channel inter-dependencies in an efficient manner. The final segmentation results are produced by merging outputs from four hierarchical stages of a SANet to integrate multi-scale contexts for obtaining enhanced pixel-wise prediction. Empirical experiments using two challenging public datasets validate the effectiveness of the proposed SANets, which achieved 83.2% mIoU (without COCO pre-training) on PASCAL VOC and a state-of-the-art mIoU of 54.4% on PASCAL Context.
ProstateGAN: Mitigating Data Bias via Prostate Diffusion Imaging Synthesis with Generative Adversarial Networks
Nov 21, 2018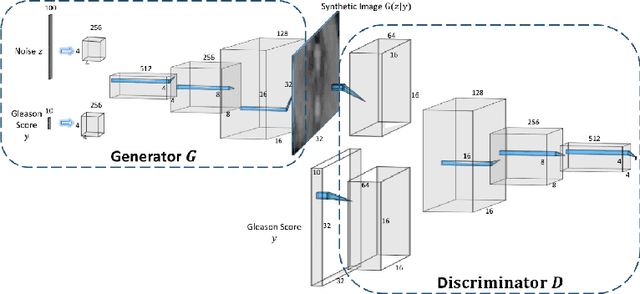

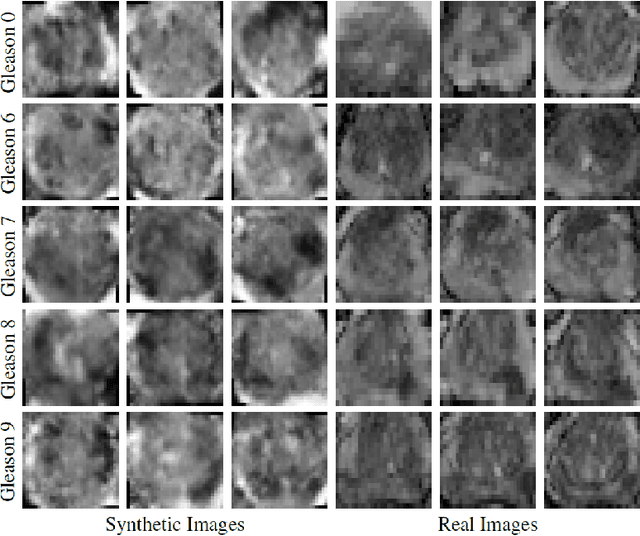
Generative Adversarial Networks (GANs) have shown considerable promise for mitigating the challenge of data scarcity when building machine learning-driven analysis algorithms. Specifically, a number of studies have shown that GAN-based image synthesis for data augmentation can aid in improving classification accuracy in a number of medical image analysis tasks, such as brain and liver image analysis. However, the efficacy of leveraging GANs for tackling prostate cancer analysis has not been previously explored. Motivated by this, in this study we introduce ProstateGAN, a GAN-based model for synthesizing realistic prostate diffusion imaging data. More specifically, in order to generate new diffusion imaging data corresponding to a particular cancer grade (Gleason score), we propose a conditional deep convolutional GAN architecture that takes Gleason scores into consideration during the training process. Experimental results show that high-quality synthetic prostate diffusion imaging data can be generated using the proposed ProstateGAN for specified Gleason scores.