 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectional Neural Collapse Explains Few-Shot Transfer in Self-Supervised Learning
Mar 03, 2026Frozen self-supervised representations often transfer well with only a few labels across many semantic tasks. We argue that a single geometric quantity, \emph{directional} CDNV (decision-axis variance), sits at the core of two favorable behaviors: strong few-shot transfer within a task, and low interference across many tasks. We show that both emerge when variability \emph{along} class-separating directions is small. First, we prove sharp non-asymptotic multiclass generalization bounds for downstream classification whose leading term is the directional CDNV. The bounds include finite-shot corrections that cleanly separate intrinsic decision-axis variability from centroid-estimation error. Second, we link decision-axis collapse to multitask geometry: for independent balanced labelings, small directional CDNV across tasks forces the corresponding decision axes to be nearly orthogonal, helping a single representation support many tasks with minimal interference. Empirically, across SSL objectives, directional CDNV collapses during pretraining even when classical CDNV remains large, and our bounds closely track few-shot error at practical shot sizes. Additionally, on synthetic multitask data, we verify that SSL learns representations whose induced decision axes are nearly orthogonal. The code and project page of the paper are available at [\href{https://dlfundamentals.github.io/directional-neural-collapse/}{project page}].
Self-Supervised Contrastive Learning is Approximately Supervised Contrastive Learning
Jun 04, 2025

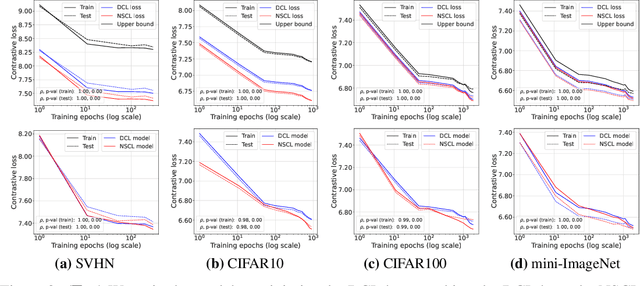

Despite its empirical success, the theoretical foundations of self-supervised contrastive learning (CL) are not yet fully established. In this work, we address this gap by showing that standard CL objectives implicitly approximate a supervised variant we call the negatives-only supervised contrastive loss (NSCL), which excludes same-class contrasts. We prove that the gap between the CL and NSCL losses vanishes as the number of semantic classes increases, under a bound that is both label-agnostic and architecture-independent. We characterize the geometric structure of the global minimizers of the NSCL loss: the learned representations exhibit augmentation collapse, within-class collapse, and class centers that form a simplex equiangular tight frame. We further introduce a new bound on the few-shot error of linear-probing. This bound depends on two measures of feature variability--within-class dispersion and variation along the line between class centers. We show that directional variation dominates the bound and that the within-class dispersion's effect diminishes as the number of labeled samples increases. These properties enable CL and NSCL-trained representations to support accurate few-shot label recovery using simple linear probes. Finally, we empirically validate our theoretical findings: the gap between CL and NSCL losses decays at a rate of $\mathcal{O}(\frac{1}{\#\text{classes}})$; the two losses are highly correlated; minimizing the CL loss implicitly brings the NSCL loss close to the value achieved by direct minimization; and the proposed few-shot error bound provides a tight estimate of probing performance in practice.
OccludeNeRF: Geometric-aware 3D Scene Inpainting with Collaborative Score Distillation in NeRF
Apr 01, 2025With Neural Radiance Fields (NeRFs) arising as a powerful 3D representation, research has investigated its various downstream tasks, including inpainting NeRFs with 2D images. Despite successful efforts addressing the view consistency and geometry quality, prior methods yet suffer from occlusion in NeRF inpainting tasks, where 2D prior is severely limited in forming a faithful reconstruction of the scene to inpaint. To address this, we propose a novel approach that enables cross-view information sharing during knowledge distillation from a diffusion model, effectively propagating occluded information across limited views. Additionally, to align the distillation direction across multiple sampled views, we apply a grid-based denoising strategy and incorporate additional rendered views to enhance cross-view consistency. To assess our approach's capability of handling occlusion cases, we construct a dataset consisting of challenging scenes with severe occlusion, in addition to existing datasets. Compared with baseline methods, our method demonstrates better performance in cross-view consistency and faithfulness in reconstruction, while preserving high rendering quality and fidelity.
LVRNet: Lightweight Image Restoration for Aerial Images under Low Visibility
Jan 13, 2023Learning to recover clear images from images having a combination of degrading factors is a challenging task. That being said, autonomous surveillance in low visibility conditions caused by high pollution/smoke, poor air quality index, low light, atmospheric scattering, and haze during a blizzard becomes even more important to prevent accidents. It is thus crucial to form a solution that can result in a high-quality image and is efficient enough to be deployed for everyday use. However, the lack of proper datasets available to tackle this task limits the performance of the previous methods proposed. To this end, we generate the LowVis-AFO dataset, containing 3647 paired dark-hazy and clear images. We also introduce a lightweight deep learning model called Low-Visibility Restoration Network (LVRNet). It outperforms previous image restoration methods with low latency, achieving a PSNR value of 25.744 and an SSIM of 0.905, making our approach scalable and ready for practical use. The code and data can be found at https://github.com/Achleshwar/LVRNet.
DroneAttention: Sparse Weighted Temporal Attention for Drone-Camera Based Activity Recognition
Dec 07, 2022
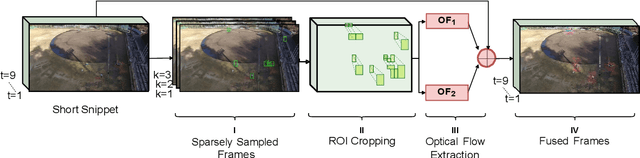
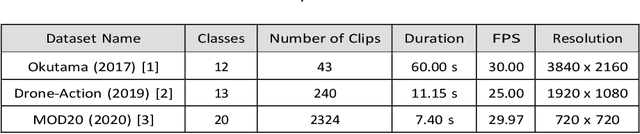
Human activity recognition (HAR) using drone-mounted cameras has attracted considerable interest from the computer vision research community in recent years. A robust and efficient HAR system has a pivotal role in fields like video surveillance, crowd behavior analysis, sports analysis, and human-computer interaction. What makes it challenging are the complex poses, understanding different viewpoints, and the environmental scenarios where the action is taking place. To address such complexities, in this paper, we propose a novel Sparse Weighted Temporal Attention (SWTA) module to utilize sparsely sampled video frames for obtaining global weighted temporal attention. The proposed SWTA is comprised of two parts. First, temporal segment network that sparsely samples a given set of frames. Second, weighted temporal attention, which incorporates a fusion of attention maps derived from optical flow, with raw RGB images. This is followed by a basenet network, which comprises a convolutional neural network (CNN) module along with fully connected layers that provide us with activity recognition. The SWTA network can be used as a plug-in module to the existing deep CNN architectures, for optimizing them to learn temporal information by eliminating the need for a separate temporal stream. It has been evaluated on three publicly available benchmark datasets, namely Okutama, MOD20, and Drone-Action. The proposed model has received an accuracy of 72.76%, 92.56%, and 78.86% on the respective datasets thereby surpassing the previous state-of-the-art performances by a margin of 25.26%, 18.56%, and 2.94%, respectively.
SWTF: Sparse Weighted Temporal Fusion for Drone-Based Activity Recognition
Nov 10, 2022Drone-camera based human activity recognition (HAR) has received significant attention from the computer vision research community in the past few years. A robust and efficient HAR system has a pivotal role in fields like video surveillance, crowd behavior analysis, sports analysis, and human-computer interaction. What makes it challenging are the complex poses, understanding different viewpoints, and the environmental scenarios where the action is taking place. To address such complexities, in this paper, we propose a novel Sparse Weighted Temporal Fusion (SWTF) module to utilize sparsely sampled video frames for obtaining global weighted temporal fusion outcome. The proposed SWTF is divided into two components. First, a temporal segment network that sparsely samples a given set of frames. Second, weighted temporal fusion, that incorporates a fusion of feature maps derived from optical flow, with raw RGB images. This is followed by base-network, which comprises a convolutional neural network module along with fully connected layers that provide us with activity recognition. The SWTF network can be used as a plug-in module to the existing deep CNN architectures, for optimizing them to learn temporal information by eliminating the need for a separate temporal stream. It has been evaluated on three publicly available benchmark datasets, namely Okutama, MOD20, and Drone-Action. The proposed model has received an accuracy of 72.76%, 92.56%, and 78.86% on the respective datasets thereby surpassing the previous state-of-the-art performances by a significant margin.
Tracking Grow-Finish Pigs Across Large Pens Using Multiple Cameras
Nov 22, 2021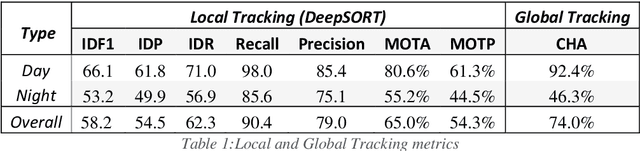
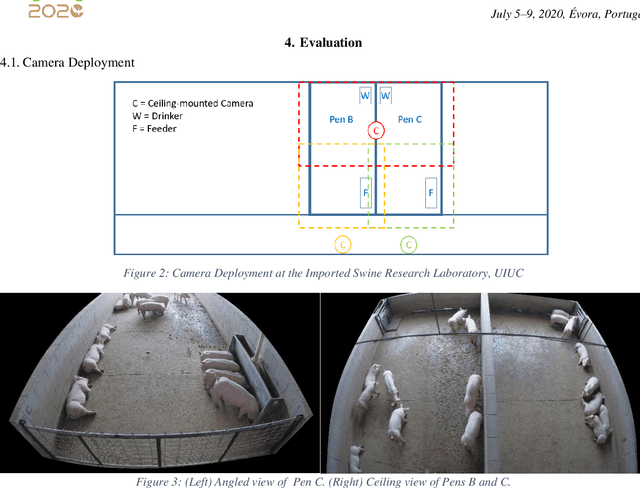


Increasing demand for meat products combined with farm labor shortages has resulted in a need to develop new real-time solutions to monitor animals effectively. Significant progress has been made in continuously locating individual pigs using tracking-by-detection methods. However, these methods fail for oblong pens because a single fixed camera does not cover the entire floor at adequate resolution. We address this problem by using multiple cameras, placed such that the visual fields of adjacent cameras overlap, and together they span the entire floor. Avoiding breaks in tracking requires inter-camera handover when a pig crosses from one camera's view into that of an adjacent camera. We identify the adjacent camera and the shared pig location on the floor at the handover time using inter-view homography. Our experiments involve two grow-finish pens, housing 16-17 pigs each, and three RGB cameras. Our algorithm first detects pigs using a deep learning-based object detection model (YOLO) and creates their local tracking IDs using a multi-object tracking algorithm (DeepSORT). We then use inter-camera shared locations to match multiple views and generate a global ID for each pig that holds throughout tracking. To evaluate our approach, we provide five two-minutes long video sequences with fully annotated global identities. We track pigs in a single camera view with a Multi-Object Tracking Accuracy and Precision of 65.0% and 54.3% respectively and achieve a Camera Handover Accuracy of 74.0%. We open-source our code and annotated dataset at https://github.com/AIFARMS/multi-camera-pig-tracking
ABO: Dataset and Benchmarks for Real-World 3D Object Understanding
Oct 12, 2021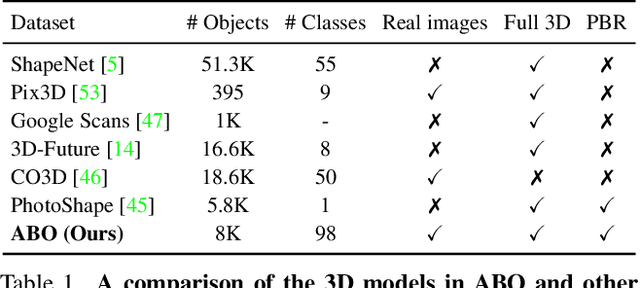
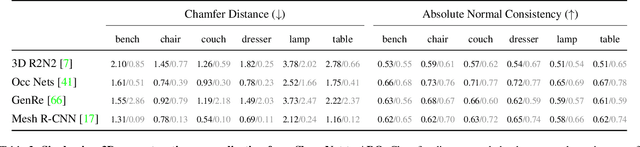
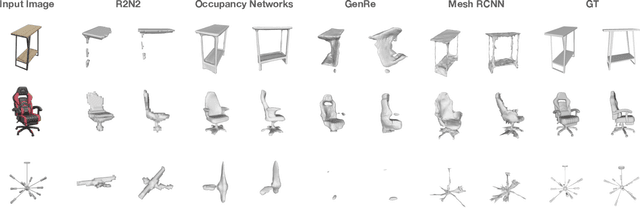
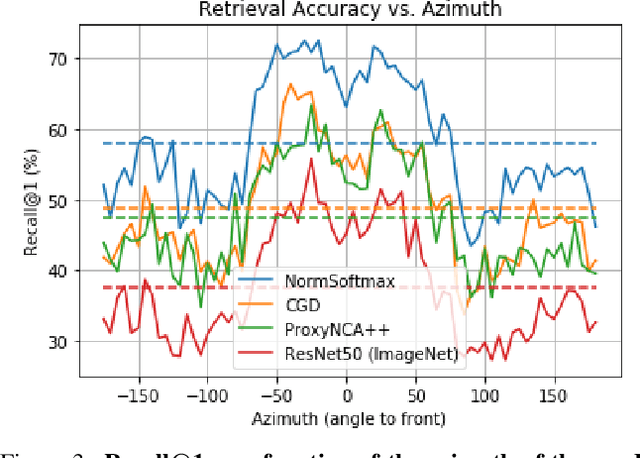
We introduce Amazon-Berkeley Objects (ABO), a new large-scale dataset of product images and 3D models corresponding to real household objects. We use this realistic, object-centric 3D dataset to measure the domain gap for single-view 3D reconstruction networks trained on synthetic objects. We also use multi-view images from ABO to measure the robustness of state-of-the-art metric learning approaches to different camera viewpoints. Finally, leveraging the physically-based rendering materials in ABO, we perform single- and multi-view material estimation for a variety of complex, real-world geometries. The full dataset is available for download at https://amazon-berkeley-objects.s3.amazonaws.com/index.html.
Eformer: Edge Enhancement based Transformer for Medical Image Denoising
Sep 16, 2021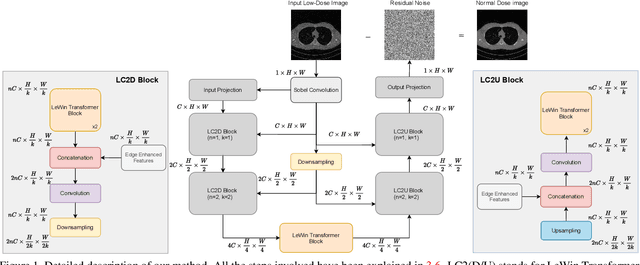
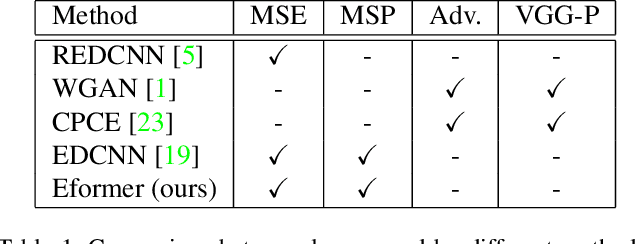
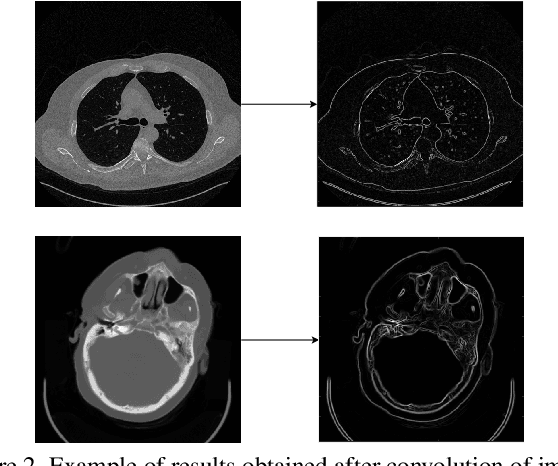
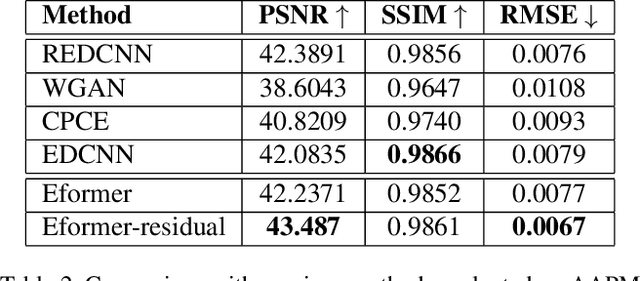
In this work, we present Eformer - Edge enhancement based transformer, a novel architecture that builds an encoder-decoder network using transformer blocks for medical image denoising. Non-overlapping window-based self-attention is used in the transformer block that reduces computational requirements. This work further incorporates learnable Sobel-Feldman operators to enhance edges in the image and propose an effective way to concatenate them in the intermediate layers of our architecture. The experimental analysis is conducted by comparing deterministic learning and residual learning for the task of medical image denoising. To defend the effectiveness of our approach, our model is evaluated on the AAPM-Mayo Clinic Low-Dose CT Grand Challenge Dataset and achieves state-of-the-art performance, $i.e.$, 43.487 PSNR, 0.0067 RMSE, and 0.9861 SSIM. We believe that our work will encourage more research in transformer-based architectures for medical image denoising using residual learning.