 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust Regions Sell, But Who's Buying? Overlap Geometry as an Alternative Trust Region for Policy Optimization
Feb 06, 2026Standard trust-region methods constrain policy updates via Kullback-Leibler (KL) divergence. However, KL controls only an average divergence and does not directly prevent rare, large likelihood-ratio excursions that destabilize training--precisely the failure mode that motivates heuristics such as PPO's clipping. We propose overlap geometry as an alternative trust region, constraining distributional overlap via the Bhattacharyya coefficient (closely related to the Hellinger/Renyi-1/2 geometry). This objective penalizes separation in the ratio tails, yielding tighter control over likelihood-ratio excursions without relying on total variation bounds that can be loose in tail regimes. We derive Bhattacharyya-TRPO (BTRPO) and Bhattacharyya-PPO (BPPO), enforcing overlap constraints via square-root ratio updates: BPPO clips the square-root ratio q = sqrt(r), and BTRPO applies a quadratic Hellinger/Bhattacharyya penalty. Empirically, overlap-based updates improve robustness and aggregate performance as measured by RLiable under matched training budgets, suggesting overlap constraints as a practical, principled alternative to KL for stable policy optimization.
A Hybrid Supervised-LLM Pipeline for Actionable Suggestion Mining in Unstructured Customer Reviews
Jan 27, 2026Extracting actionable suggestions from customer reviews is essential for operational decision-making, yet these directives are often embedded within mixed-intent, unstructured text. Existing approaches either classify suggestion-bearing sentences or generate high-level summaries, but rarely isolate the precise improvement instructions businesses need. We evaluate a hybrid pipeline combining a high-recall RoBERTa classifier trained with a precision-recall surrogate to reduce unrecoverable false negatives with a controlled, instruction-tuned LLM for suggestion extraction, categorization, clustering, and summarization. Across real-world hospitality and food datasets, the hybrid system outperforms prompt-only, rule-based, and classifier-only baselines in extraction accuracy and cluster coherence. Human evaluations further confirm that the resulting suggestions and summaries are clear, faithful, and interpretable. Overall, our results show that hybrid reasoning architectures achieve meaningful improvements fine-grained actionable suggestion mining while highlighting challenges in domain adaptation and efficient local deployment.
Actionable Advice from Reviews via Mixture of LoRA Experts: A Two-LLM Pipeline for Issue Extraction and Business Recommendations
Jan 18, 2026Customer reviews contain detailed, domain specific signals about service failures and user expectations, but converting this unstructured feedback into actionable business decisions remains difficult. We study review-to-action generation: producing concrete, implementable recommendations grounded in review text. We propose a modular two-LLM framework in which an Issue model extracts salient issues and assigns coarse themes, and an Advice model generates targeted operational fixes conditioned on the extracted issue representation. To enable specialization without expensive full fine-tuning, we adapt the Advice model using a mixture of LoRA experts strategy: multiple low-rank adapters are trained and a lightweight gating mechanism performs token-level expert mixing at inference, combining complementary expertise across issue types. We construct synthetic review-issue-advice triples from Yelp reviews (airlines and restaurants) to supervise training, and evaluate recommendations using an eight dimension operational rubric spanning actionability, specificity, feasibility, expected impact, novelty, non-redundancy, bias, and clarity. Across both domains, our approach consistently outperforms prompting-only and single-adapter baselines, yielding higher actionability and specificity while retaining favorable efficiency-quality trade-offs.
A Multi-Agent System for Generating Actionable Business Advice
Jan 17, 2026Customer reviews contain rich signals about product weaknesses and unmet user needs, yet existing analytic methods rarely move beyond descriptive tasks such as sentiment analysis or aspect extraction. While large language models (LLMs) can generate free-form suggestions, their outputs often lack accuracy and depth of reasoning. In this paper, we present a multi-agent, LLM-based framework for prescriptive decision support, which transforms large scale review corpora into actionable business advice. The framework integrates four components: clustering to select representative reviews, generation of advices, iterative evaluation, and feasibility based ranking. This design couples corpus distillation with feedback driven advice refinement to produce outputs that are specific, actionable, and practical. Experiments across three service domains and multiple model families show that our framework consistently outperform single model baselines on actionability, specificity, and non-redundancy, with medium sized models approaching the performance of large model frameworks.
FAST-IDS: A Fast Two-Stage Intrusion Detection System with Hybrid Compression for Real-Time Threat Detection in Connected and Autonomous Vehicles
Dec 30, 2025We have implemented a multi-stage IDS for CAVs that can be deployed to resourec-constrained environments after hybrid model compression.
FedSecureFormer: A Fast, Federated and Secure Transformer Framework for Lightweight Intrusion Detection in Connected and Autonomous Vehicles
Dec 30, 2025This works presents an encoder-only transformer built with minimum layers for intrusion detection in the domain of Connected and Autonomous Vehicles using Federated Learning.
FedLiTeCAN : A Federated Lightweight Transformer for Fast and Robust CAN Bus Intrusion Detection
Dec 30, 2025This work implements a lightweight Transformer model for IDS in the domain of Connected and Autonomous Vehicles
Understanding Virality: A Rubric based Vision-Language Model Framework for Short-Form Edutainment Evaluation
Dec 24, 2025Evaluating short-form video content requires moving beyond surface-level quality metrics toward human-aligned, multimodal reasoning. While existing frameworks like VideoScore-2 assess visual and semantic fidelity, they do not capture how specific audiovisual attributes drive real audience engagement. In this work, we propose a data-driven evaluation framework that uses Vision-Language Models (VLMs) to extract unsupervised audiovisual features, clusters them into interpretable factors, and trains a regression-based evaluator to predict engagement on short-form edutainment videos. Our curated YouTube Shorts dataset enables systematic analysis of how VLM-derived features relate to human engagement behavior. Experiments show strong correlations between predicted and actual engagement, demonstrating that our lightweight, feature-based evaluator provides interpretable and scalable assessments compared to traditional metrics (e.g., SSIM, FID). By grounding evaluation in both multimodal feature importance and human-centered engagement signals, our approach advances toward robust and explainable video understanding.
Navigating the Reality Gap: Privacy-Preserving Adaptation of ASR for Challenging Low-Resource Domains
Dec 22, 2025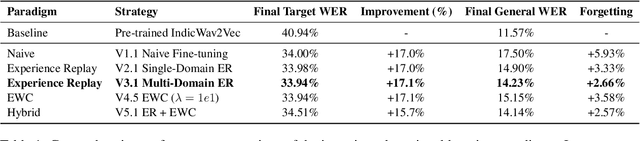
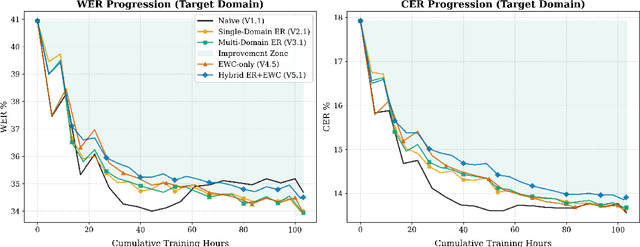
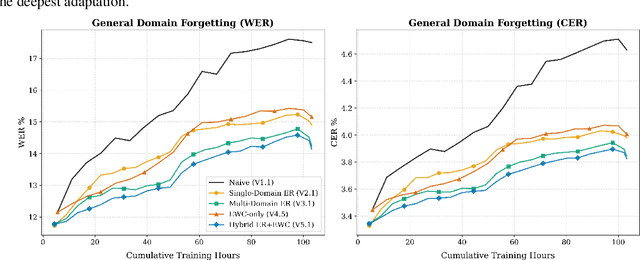

Automatic Speech Recognition (ASR) holds immense potential to assist in clinical documentation and patient report generation, particularly in resource-constrained regions. However, deployment is currently hindered by a technical deadlock: a severe "Reality Gap" between laboratory performance and noisy, real-world clinical audio, coupled with strict privacy and resource constraints. We quantify this gap, showing that a robust multilingual model (IndicWav2Vec) degrades to a 40.94% WER on rural clinical data from India, rendering it unusable. To address this, we explore a zero-data-exfiltration framework enabling localized, continual adaptation via Low-Rank Adaptation (LoRA). We conduct a rigorous investigative study of continual learning strategies, characterizing the trade-offs between data-driven and parameter-driven stability. Our results demonstrate that multi-domain Experience Replay (ER) yields the primary performance gains, achieving a 17.1% relative improvement in target WER and reducing catastrophic forgetting by 55% compared to naive adaptation. Furthermore, we observed that standard Elastic Weight Consolidation (EWC) faced numerical stability challenges when applied to LoRA in noisy environments. Our experiments show that a stabilized, linearized formulation effectively controls gradient magnitudes and enables stable convergence. Finally, we verify via a domain-specific spot check that acoustic adaptation is a fundamental prerequisite for usability which cannot be bypassed by language models alone.
Investigating Spatial Attention Bias in Vision-Language Models
Dec 20, 2025Vision-Language Models have demonstrated remarkable capabilities in understanding visual content, yet systematic biases in their spatial processing remain largely unexplored. This work identifies and characterizes a systematic spatial attention bias where VLMs consistently prioritize describing left-positioned content before right-positioned content in horizontally concatenated images. Through controlled experiments on image pairs using both open-source and closed-source models, we demonstrate that this bias persists across different architectures, with models describing left-positioned content first in approximately 97% of cases under neutral prompting conditions. Testing on an Arabic-finetuned model reveals that the bias persists despite right-to-left language training, ruling out language reading direction as the primary cause. Investigation of training dataset annotation guidelines from PixMo and Visual Genome reveals no explicit left-first ordering instructions, suggesting the bias is consistent with architectural factors rather than explicit training data instructions. These findings reveal fundamental limitations in how current VLMs process spatial information.