 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabSynDex: A Universal Metric for Robust Evaluation of Synthetic Tabular Data
Jul 12, 2022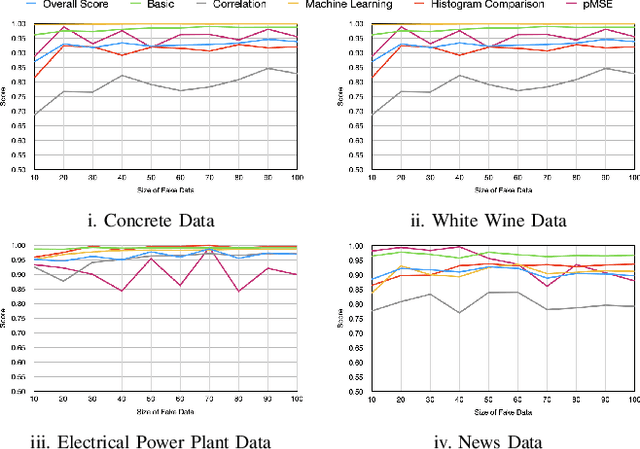
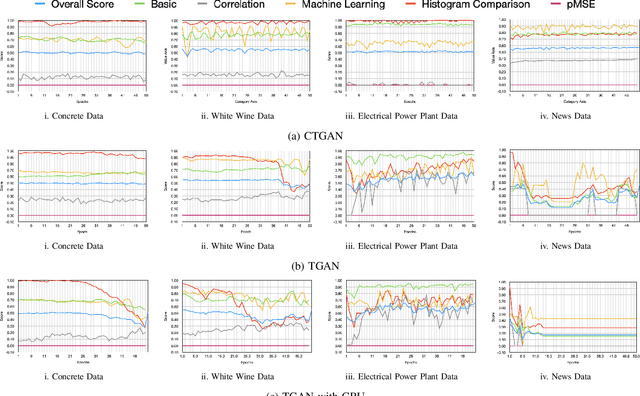
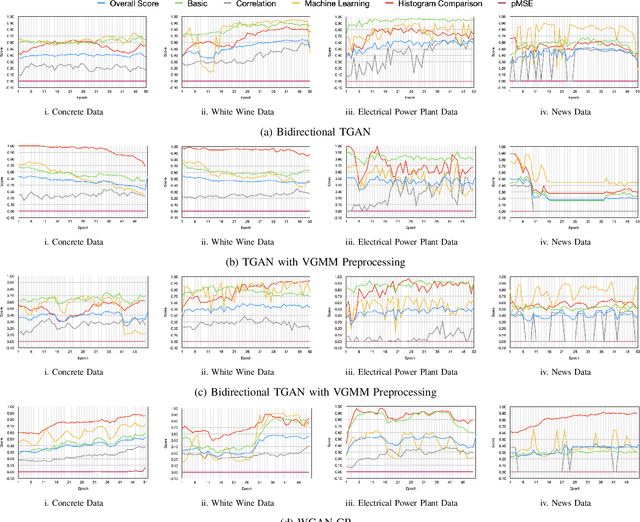
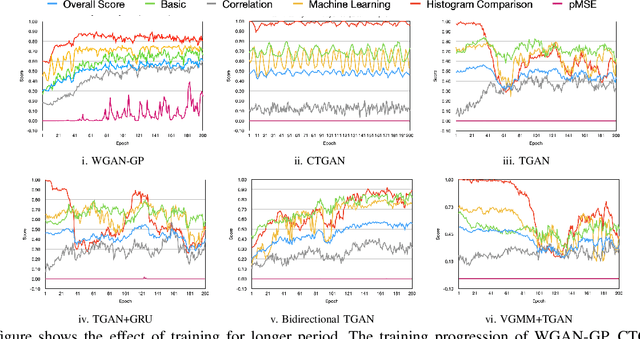
Synthetic tabular data generation becomes crucial when real data is limited, expensive to collect, or simply cannot be used due to privacy concerns. However, producing good quality synthetic data is challenging. Several probabilistic, statistical, and generative adversarial networks (GANs) based approaches have been presented for synthetic tabular data generation. Once generated, evaluating the quality of the synthetic data is quite challenging. Some of the traditional metrics have been used in the literature but there is lack of a common, robust, and single metric. This makes it difficult to properly compare the effectiveness of different synthetic tabular data generation methods. In this paper we propose a new universal metric, TabSynDex, for robust evaluation of synthetic data. TabSynDex assesses the similarity of synthetic data with real data through different component scores which evaluate the characteristics that are desirable for "high quality" synthetic data. Being a single score metric, TabSynDex can also be used to observe and evaluate the training of neural network based approaches. This would help in obtaining insights that was not possible earlier. Further, we present several baseline models for comparative analysis of the proposed evaluation metric with existing generative models.