 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHelpful to a Fault: Measuring Illicit Assistance in Multi-Turn, Multilingual LLM Agents
Feb 19, 2026LLM-based agents execute real-world workflows via tools and memory. These affordances enable ill-intended adversaries to also use these agents to carry out complex misuse scenarios. Existing agent misuse benchmarks largely test single-prompt instructions, leaving a gap in measuring how agents end up helping with harmful or illegal tasks over multiple turns. We introduce STING (Sequential Testing of Illicit N-step Goal execution), an automated red-teaming framework that constructs a step-by-step illicit plan grounded in a benign persona and iteratively probes a target agent with adaptive follow-ups, using judge agents to track phase completion. We further introduce an analysis framework that models multi-turn red-teaming as a time-to-first-jailbreak random variable, enabling analysis tools like discovery curves, hazard-ratio attribution by attack language, and a new metric: Restricted Mean Jailbreak Discovery. Across AgentHarm scenarios, STING yields substantially higher illicit-task completion than single-turn prompting and chat-oriented multi-turn baselines adapted to tool-using agents. In multilingual evaluations across six non-English settings, we find that attack success and illicit-task completion do not consistently increase in lower-resource languages, diverging from common chatbot findings. Overall, STING provides a practical way to evaluate and stress-test agent misuse in realistic deployment settings, where interactions are inherently multi-turn and often multilingual.
EcoVal: An Efficient Data Valuation Framework for Machine Learning
Feb 15, 2024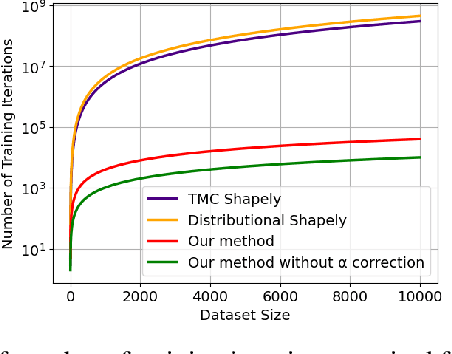
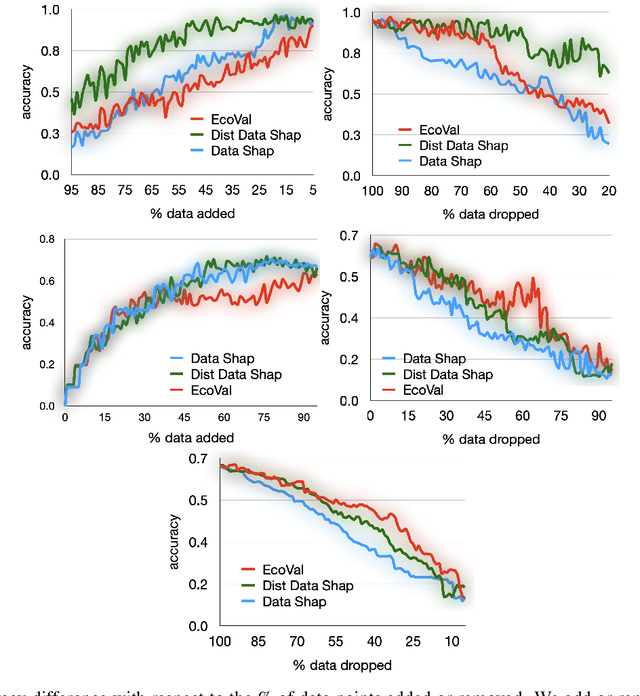
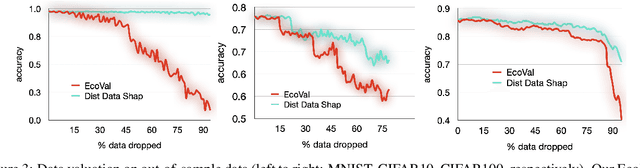
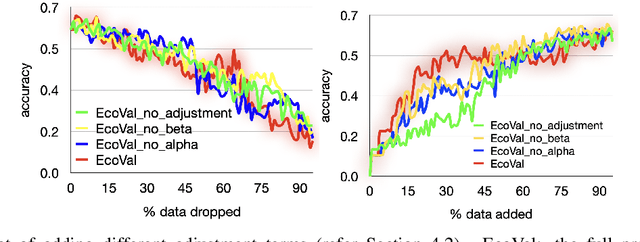
Quantifying the value of data within a machine learning workflow can play a pivotal role in making more strategic decisions in machine learning initiatives. The existing Shapley value based frameworks for data valuation in machine learning are computationally expensive as they require considerable amount of repeated training of the model to obtain the Shapley value. In this paper, we introduce an efficient data valuation framework EcoVal, to estimate the value of data for machine learning models in a fast and practical manner. Instead of directly working with individual data sample, we determine the value of a cluster of similar data points. This value is further propagated amongst all the member cluster points. We show that the overall data value can be determined by estimating the intrinsic and extrinsic value of each data. This is enabled by formulating the performance of a model as a \textit{production function}, a concept which is popularly used to estimate the amount of output based on factors like labor and capital in a traditional free economic market. We provide a formal proof of our valuation technique and elucidate the principles and mechanisms that enable its accelerated performance. We demonstrate the real-world applicability of our method by showcasing its effectiveness for both in-distribution and out-of-sample data. This work addresses one of the core challenges of efficient data valuation at scale in machine learning models.
Deep Regression Unlearning
Oct 15, 2022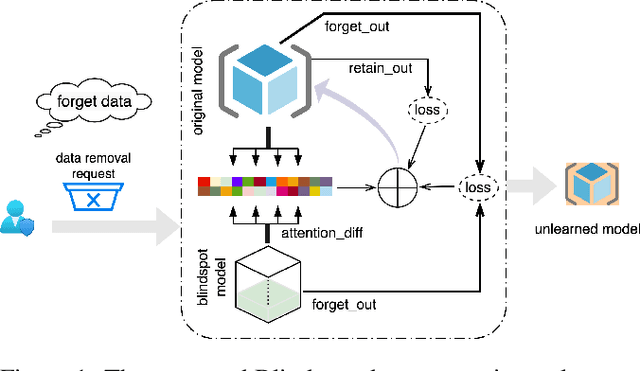
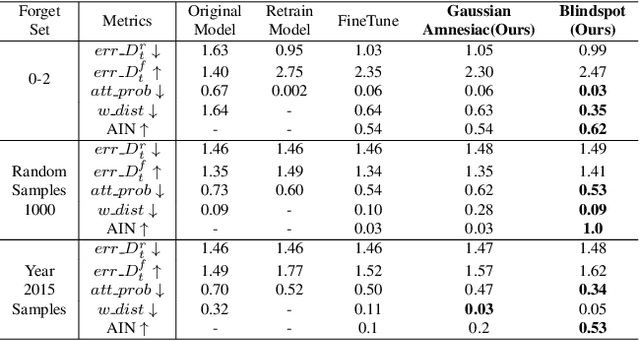
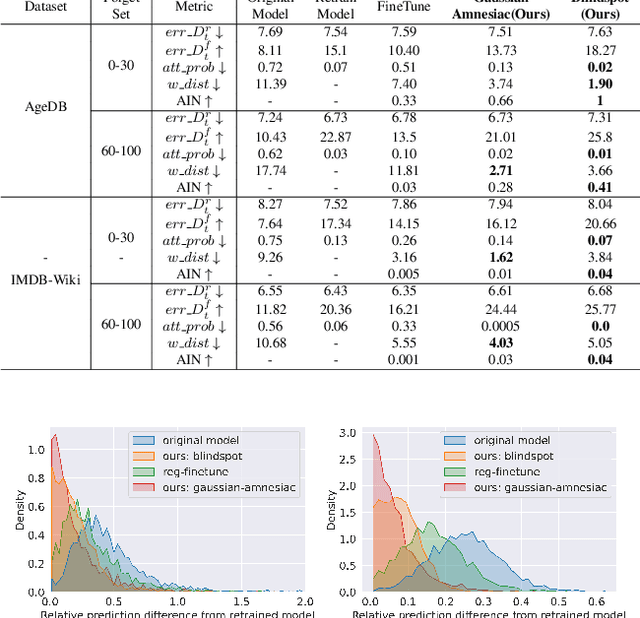
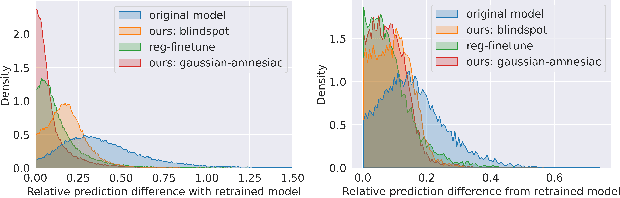
With the introduction of data protection and privacy regulations, it has become crucial to remove the lineage of data on demand in a machine learning system. In past few years, there has been notable development in machine unlearning to remove the information of certain training data points efficiently and effectively from the model. In this work, we explore unlearning in a regression problem, particularly in deep learning models. Unlearning in classification and simple linear regression has been investigated considerably. However, unlearning in deep regression models largely remain an untouched problem till now. In this work, we introduce deep regression unlearning methods that are well generalized and robust to privacy attacks. We propose the Blindspot unlearning method which uses a novel weight optimization process. A randomly initialized model, partially exposed to the retain samples and a copy of original model are used together to selectively imprint knowledge about the data that we wish to keep and scrub the information of the data we wish to forget. We also propose a Gaussian distribution based fine tuning method for regression unlearning. The existing evaluation metrics for unlearning in a classification task are not directly applicable for regression unlearning. Therefore, we adapt these metrics for regression task. We devise a membership inference attack to check the privacy leaks in the unlearned regression model. We conduct the experiments on regression tasks for computer vision, natural language processing and forecasting applications. Our deep regression unlearning methods show excellent performance across all of these datasets and metrics.
TabSynDex: A Universal Metric for Robust Evaluation of Synthetic Tabular Data
Jul 12, 2022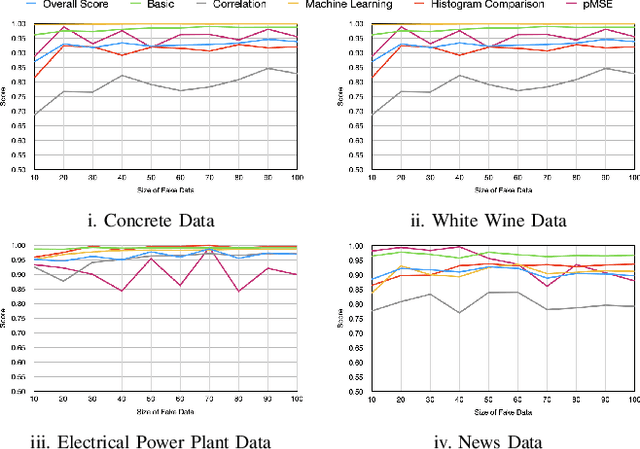
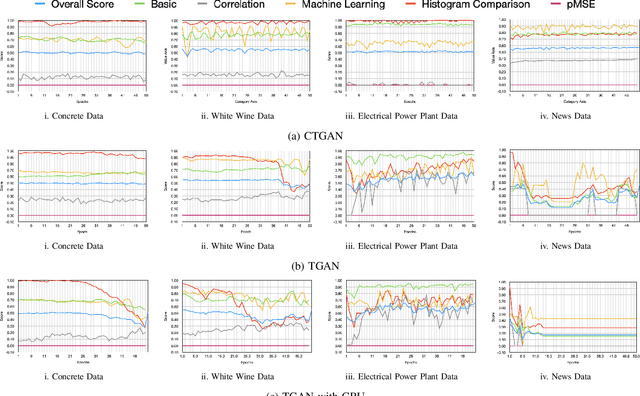
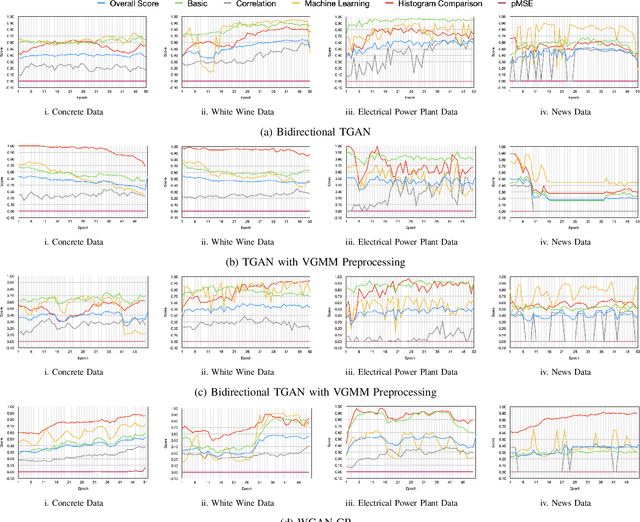
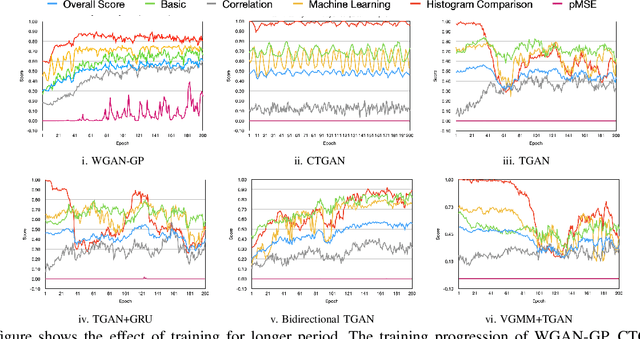
Synthetic tabular data generation becomes crucial when real data is limited, expensive to collect, or simply cannot be used due to privacy concerns. However, producing good quality synthetic data is challenging. Several probabilistic, statistical, and generative adversarial networks (GANs) based approaches have been presented for synthetic tabular data generation. Once generated, evaluating the quality of the synthetic data is quite challenging. Some of the traditional metrics have been used in the literature but there is lack of a common, robust, and single metric. This makes it difficult to properly compare the effectiveness of different synthetic tabular data generation methods. In this paper we propose a new universal metric, TabSynDex, for robust evaluation of synthetic data. TabSynDex assesses the similarity of synthetic data with real data through different component scores which evaluate the characteristics that are desirable for "high quality" synthetic data. Being a single score metric, TabSynDex can also be used to observe and evaluate the training of neural network based approaches. This would help in obtaining insights that was not possible earlier. Further, we present several baseline models for comparative analysis of the proposed evaluation metric with existing generative models.
Can Bad Teaching Induce Forgetting? Unlearning in Deep Networks using an Incompetent Teacher
May 17, 2022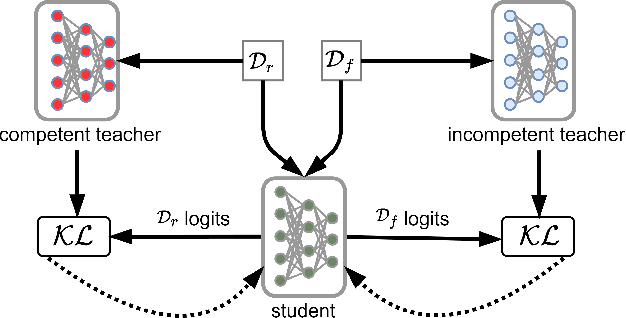
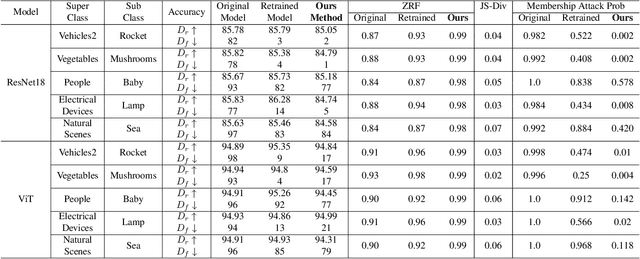

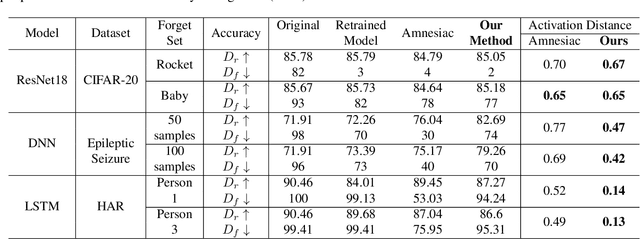
Machine unlearning has become an important field of research due to an increasing focus on addressing the evolving data privacy rules and regulations into the machine learning (ML) applications. It facilitates the request for removal of certain set or class of data from the already trained ML model without retraining from scratch. Recently, several efforts have been made to perform unlearning in an effective and efficient manner. We propose a novel machine unlearning method by exploring the utility of competent and incompetent teachers in a student-teacher framework to induce forgetfulness. The knowledge from the competent and incompetent teachers is selectively transferred to the student to obtain a model that doesn't contain any information about the forget data. We experimentally show that this method is well generalized, fast, and effective. Furthermore, we introduce a zero retrain forgetting (ZRF) metric to evaluate the unlearning method. Unlike the existing unlearning metrics, the ZRF score does not depend on the availability of the expensive retrained model. This makes it useful for analysis of the unlearned model after deployment as well. The experiments are conducted for random subset forgetting and class forgetting on various deep networks and across different application domains. A use case of forgetting information about the patients' medical records is also presented.
Zero-Shot Machine Unlearning
Jan 14, 2022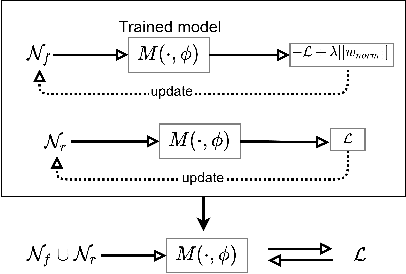
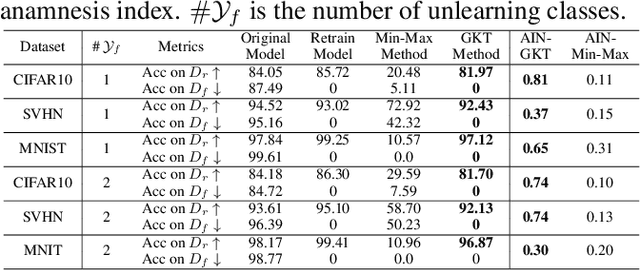
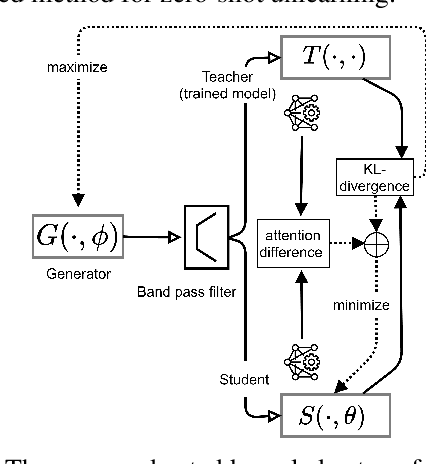
With the introduction of new privacy regulations, machine unlearning is becoming an emerging research problem due to an increasing need for regulatory compliance required for machine learning (ML) applications. Modern privacy regulations grant citizens the right to be forgotten by products, services and companies. This necessitates deletion of data not only from storage archives but also from ML model. The right to be forgotten requests come in the form of removal of a certain set or class of data from the already trained ML model. Practical considerations preclude retraining of the model from scratch minus the deleted data. The few existing studies use the whole training data, or a subset of training data, or some metadata stored during training to update the model weights for unlearning. However, strict regulatory compliance requires time-bound deletion of data. Thus, in many cases, no data related to the training process or training samples may be accessible even for the unlearning purpose. We therefore ask the question: is it possible to achieve unlearning with zero training samples? In this paper, we introduce the novel problem of zero-shot machine unlearning that caters for the extreme but practical scenario where zero original data samples are available for use. We then propose two novel solutions for zero-shot machine unlearning based on (a) error minimizing-maximizing noise and (b) gated knowledge transfer. We also introduce a new evaluation metric, Anamnesis Index (AIN) to effectively measure the quality of the unlearning method. The experiments show promising results for unlearning in deep learning models on benchmark vision data-sets. The source code will be made publicly available.
Fast Yet Effective Machine Unlearning
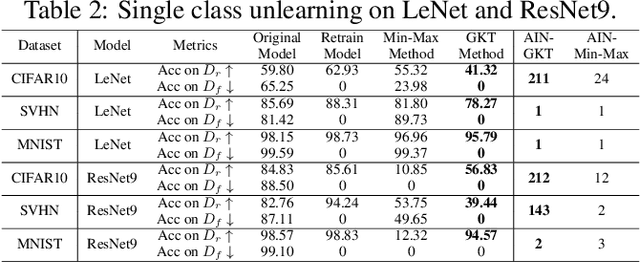
Nov 25, 2021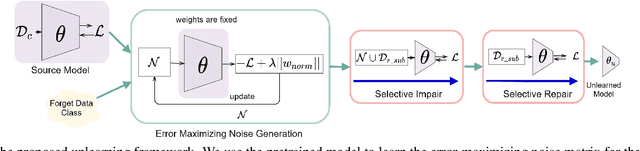
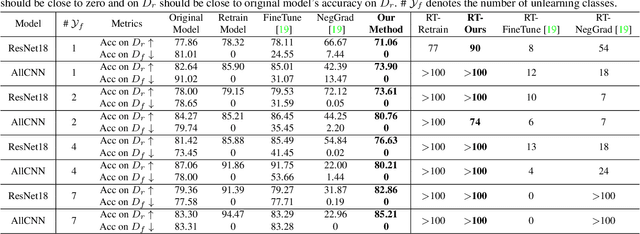

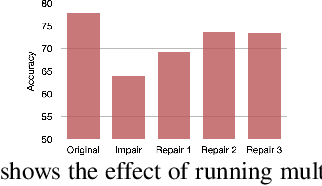
Unlearning the data observed during the training of a machine learning (ML) model is an important task that can play a pivotal role in fortifying the privacy and security of ML-based applications. This paper raises the following questions: (i) can we unlearn a class/classes of data from a ML model without looking at the full training data even once? (ii) can we make the process of unlearning fast and scalable to large datasets, and generalize it to different deep networks? We introduce a novel machine unlearning framework with error-maximizing noise generation and impair-repair based weight manipulation that offers an efficient solution to the above questions. An error-maximizing noise matrix is learned for the class to be unlearned using the original model. The noise matrix is used to manipulate the model weights to unlearn the targeted class of data. We introduce impair and repair steps for a controlled manipulation of the network weights. In the impair step, the noise matrix along with a very high learning rate is used to induce sharp unlearning in the model. Thereafter, the repair step is used to regain the overall performance. With very few update steps, we show excellent unlearning while substantially retaining the overall model accuracy. Unlearning multiple classes requires a similar number of update steps as for the single class, making our approach scalable to large problems. Our method is quite efficient in comparison to the existing methods, works for multi-class unlearning, doesn't put any constraints on the original optimization mechanism or network design, and works well in both small and large-scale vision tasks. This work is an important step towards fast and easy implementation of unlearning in deep networks. We will make the source code publicly available.