 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCortex AISQL: A Production SQL Engine for Unstructured Data
Nov 19, 2025Snowflake's Cortex AISQL is a production SQL engine that integrates native semantic operations directly into SQL. This integration allows users to write declarative queries that combine relational operations with semantic reasoning, enabling them to query both structured and unstructured data effortlessly. However, making semantic operations efficient at production scale poses fundamental challenges. Semantic operations are more expensive than traditional SQL operations, possess distinct latency and throughput characteristics, and their cost and selectivity are unknown during query compilation. Furthermore, existing query engines are not designed to optimize semantic operations. The AISQL query execution engine addresses these challenges through three novel techniques informed by production deployment data from Snowflake customers. First, AI-aware query optimization treats AI inference cost as a first-class optimization objective, reasoning about large language model (LLM) cost directly during query planning to achieve 2-8$\times$ speedups. Second, adaptive model cascades reduce inference costs by routing most rows through a fast proxy model while escalating uncertain cases to a powerful oracle model, achieving 2-6$\times$ speedups while maintaining 90-95% of oracle model quality. Third, semantic join query rewriting lowers the quadratic time complexity of join operations to linear through reformulation as multi-label classification tasks, achieving 15-70$\times$ speedups with often improved prediction quality. AISQL is deployed in production at Snowflake, where it powers diverse customer workloads across analytics, search, and content understanding.
Generating Fit Check Videos with a Handheld Camera
May 29, 2025Self-captured full-body videos are popular, but most deployments require mounted cameras, carefully-framed shots, and repeated practice. We propose a more convenient solution that enables full-body video capture using handheld mobile devices. Our approach takes as input two static photos (front and back) of you in a mirror, along with an IMU motion reference that you perform while holding your mobile phone, and synthesizes a realistic video of you performing a similar target motion. We enable rendering into a new scene, with consistent illumination and shadows. We propose a novel video diffusion-based model to achieve this. Specifically, we propose a parameter-free frame generation strategy, as well as a multi-reference attention mechanism, that effectively integrate appearance information from both the front and back selfies into the video diffusion model. Additionally, we introduce an image-based fine-tuning strategy to enhance frame sharpness and improve the generation of shadows and reflections, achieving a more realistic human-scene composition.
Inverse Painting: Reconstructing The Painting Process
Sep 30, 2024
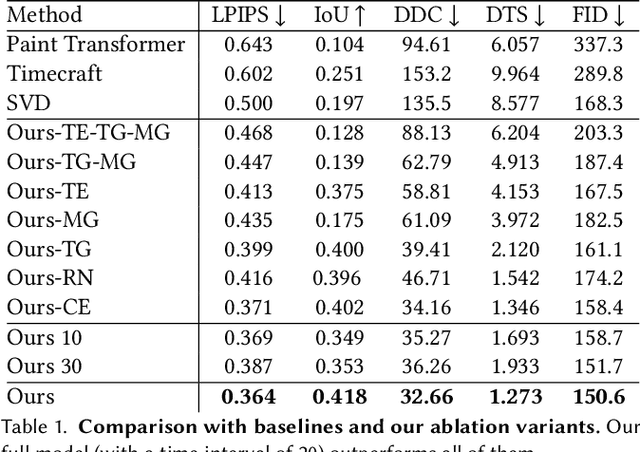

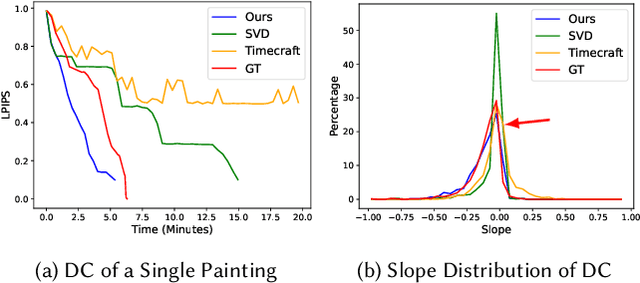
Given an input painting, we reconstruct a time-lapse video of how it may have been painted. We formulate this as an autoregressive image generation problem, in which an initially blank "canvas" is iteratively updated. The model learns from real artists by training on many painting videos. Our approach incorporates text and region understanding to define a set of painting "instructions" and updates the canvas with a novel diffusion-based renderer. The method extrapolates beyond the limited, acrylic style paintings on which it has been trained, showing plausible results for a wide range of artistic styles and genres.
Learning Feature-Preserving Portrait Editing from Generated Pairs
Jul 29, 2024Portrait editing is challenging for existing techniques due to difficulties in preserving subject features like identity. In this paper, we propose a training-based method leveraging auto-generated paired data to learn desired editing while ensuring the preservation of unchanged subject features. Specifically, we design a data generation process to create reasonably good training pairs for desired editing at low cost. Based on these pairs, we introduce a Multi-Conditioned Diffusion Model to effectively learn the editing direction and preserve subject features. During inference, our model produces accurate editing mask that can guide the inference process to further preserve detailed subject features. Experiments on costume editing and cartoon expression editing show that our method achieves state-of-the-art quality, quantitatively and qualitatively.
EcoVal: An Efficient Data Valuation Framework for Machine Learning
Feb 15, 2024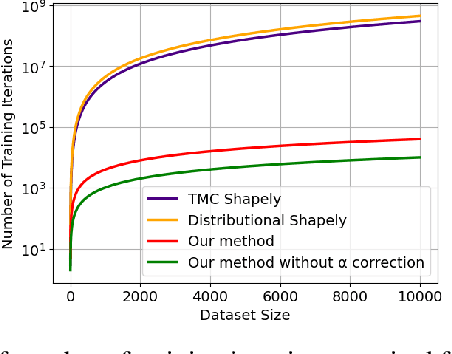
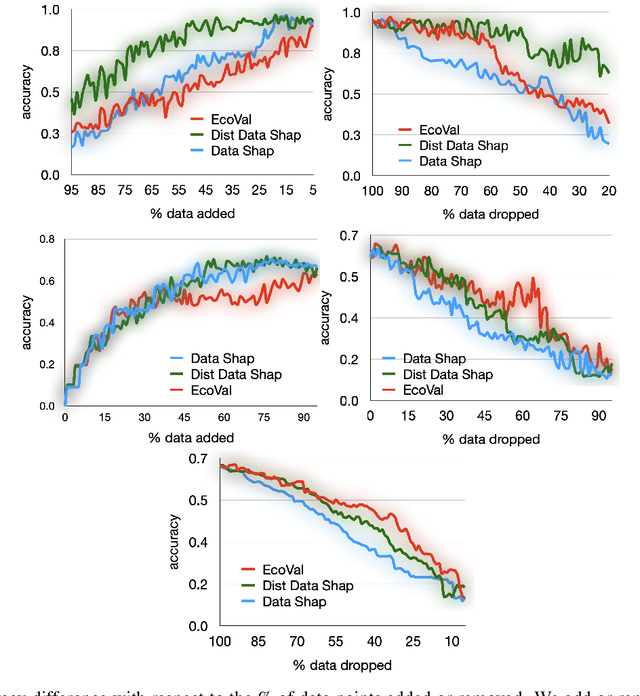
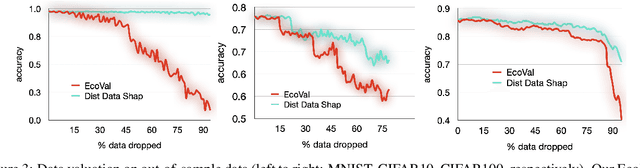
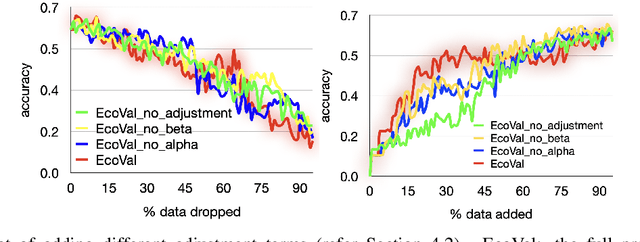
Quantifying the value of data within a machine learning workflow can play a pivotal role in making more strategic decisions in machine learning initiatives. The existing Shapley value based frameworks for data valuation in machine learning are computationally expensive as they require considerable amount of repeated training of the model to obtain the Shapley value. In this paper, we introduce an efficient data valuation framework EcoVal, to estimate the value of data for machine learning models in a fast and practical manner. Instead of directly working with individual data sample, we determine the value of a cluster of similar data points. This value is further propagated amongst all the member cluster points. We show that the overall data value can be determined by estimating the intrinsic and extrinsic value of each data. This is enabled by formulating the performance of a model as a \textit{production function}, a concept which is popularly used to estimate the amount of output based on factors like labor and capital in a traditional free economic market. We provide a formal proof of our valuation technique and elucidate the principles and mechanisms that enable its accelerated performance. We demonstrate the real-world applicability of our method by showcasing its effectiveness for both in-distribution and out-of-sample data. This work addresses one of the core challenges of efficient data valuation at scale in machine learning models.
Total Selfie: Generating Full-Body Selfies
Aug 28, 2023



We present a method to generate full-body selfies -- photos that you take of yourself, but capturing your whole body as if someone else took the photo of you from a few feet away. Our approach takes as input a pre-captured video of your body, a target pose photo, and a selfie + background pair for each location. We introduce a novel diffusion-based approach to combine all of this information into high quality, well-composed photos of you with the desired pose and background.
Learning Continuous Implicit Representation for Near-Periodic Patterns
Aug 25, 2022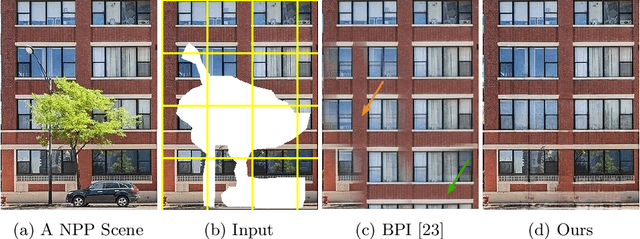
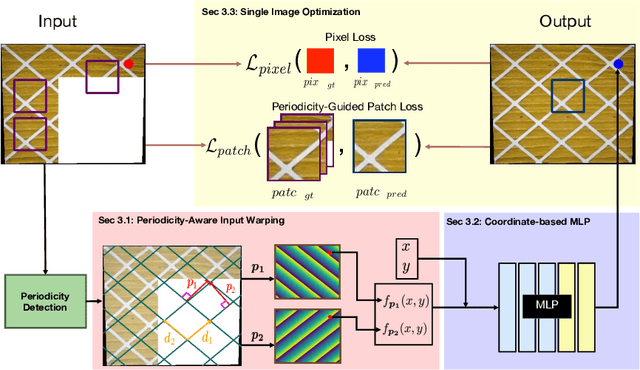
Near-Periodic Patterns (NPP) are ubiquitous in man-made scenes and are composed of tiled motifs with appearance differences caused by lighting, defects, or design elements. A good NPP representation is useful for many applications including image completion, segmentation, and geometric remapping. But representing NPP is challenging because it needs to maintain global consistency (tiled motifs layout) while preserving local variations (appearance differences). Methods trained on general scenes using a large dataset or single-image optimization struggle to satisfy these constraints, while methods that explicitly model periodicity are not robust to periodicity detection errors. To address these challenges, we learn a neural implicit representation using a coordinate-based MLP with single image optimization. We design an input feature warping module and a periodicity-guided patch loss to handle both global consistency and local variations. To further improve the robustness, we introduce a periodicity proposal module to search and use multiple candidate periodicities in our pipeline. We demonstrate the effectiveness of our method on more than 500 images of building facades, friezes, wallpapers, ground, and Mondrian patterns on single and multi-planar scenes.
DVM-CAR: A large-scale automotive dataset for visual marketing research and applications
Aug 10, 2021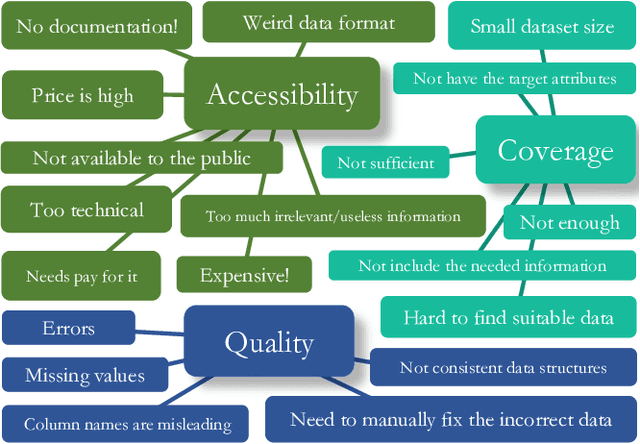
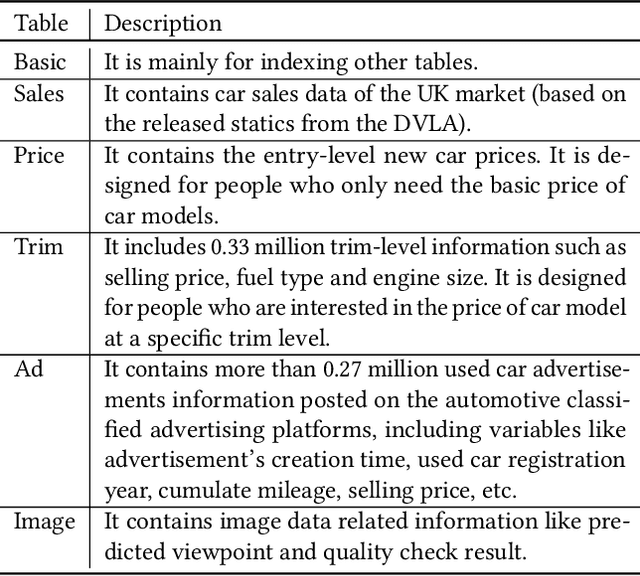

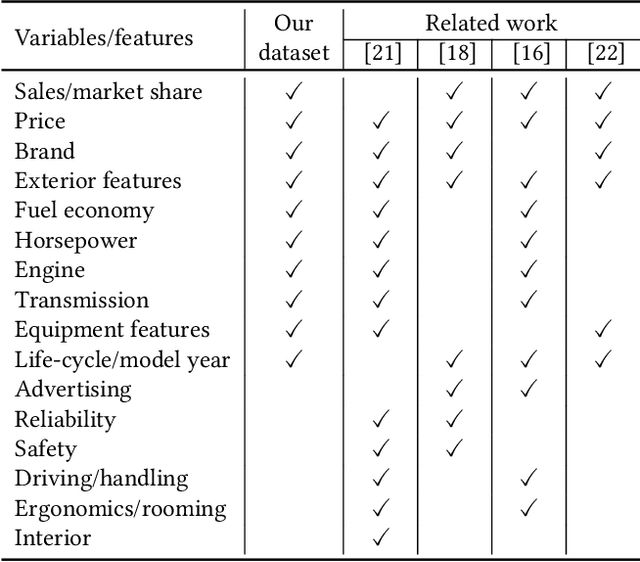
The automotive industry is being transformed by technologies, applications and services ranging from sensors to big data analytics and to artificial intelligence. In this paper, we present our multidisciplinary initiative of creating a publicly available dataset to facilitate the visual-related marketing research and applications in automotive industry such as automotive exterior design, consumer analytics and sales modelling. We are motivated by the fact that there is growing interest in product aesthetics but there is no large-scale dataset available that covers a wide range of variables and information. We summarise the common issues faced by marketing researchers and computer scientists through a user survey study, and design our dataset to alleviate these issues. Our dataset contains 1.4 million images from 899 car models as well as their corresponding car model specification and sales information over more than ten years in the UK market. To the best of our knowledge, this is the very first large-scale automotive dataset which contains images, text and sales information from multiple sources over a long period of time. We describe the detailed data structure and the preparation steps, which we believe has the methodological contribution to the multi-source data fusion and sharing. In addition, we discuss three dataset application examples to illustrate the value of our dataset.
Learning Robust Variational Information Bottleneck with Reference
Apr 29, 2021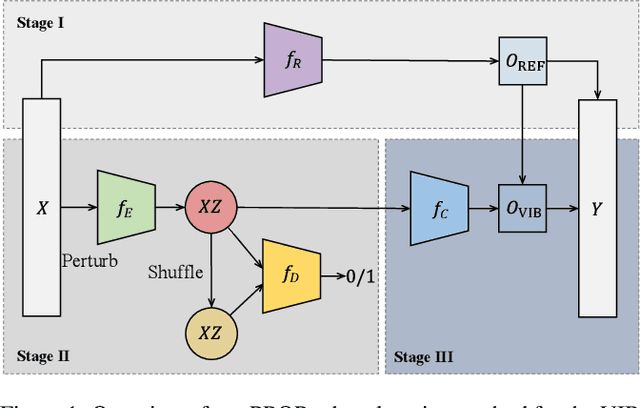
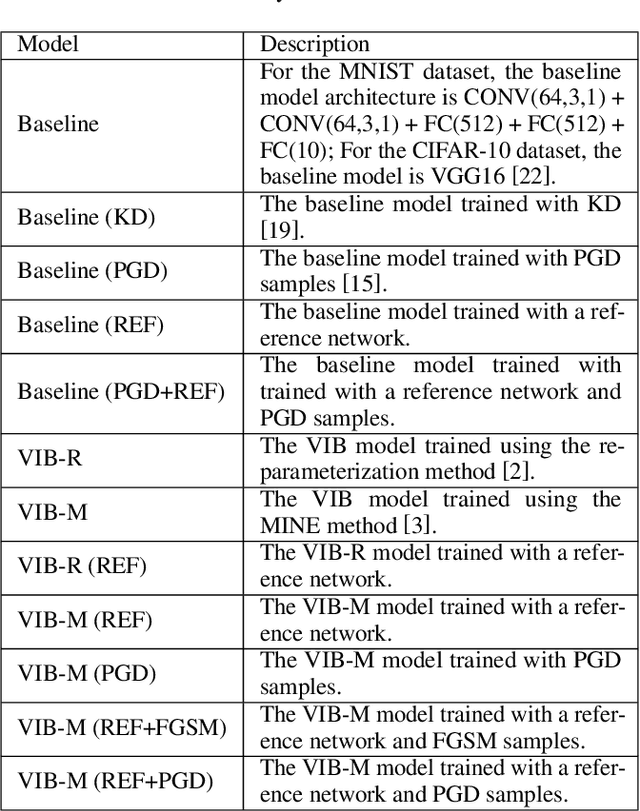


We propose a new approach to train a variational information bottleneck (VIB) that improves its robustness to adversarial perturbations. Unlike the traditional methods where the hard labels are usually used for the classification task, we refine the categorical class information in the training phase with soft labels which are obtained from a pre-trained reference neural network and can reflect the likelihood of the original class labels. We also relax the Gaussian posterior assumption in the VIB implementation by using the mutual information neural estimation. Extensive experiments have been performed with the MNIST and CIFAR-10 datasets, and the results show that our proposed approach significantly outperforms the benchmarked models.
Multi-Task Variational Information Bottleneck
Jul 01, 2020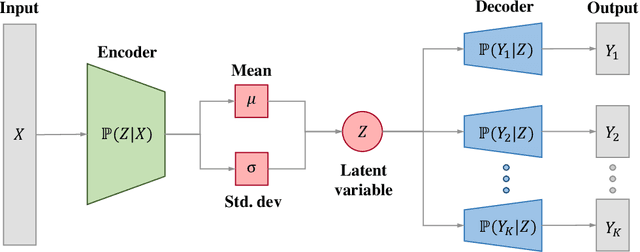
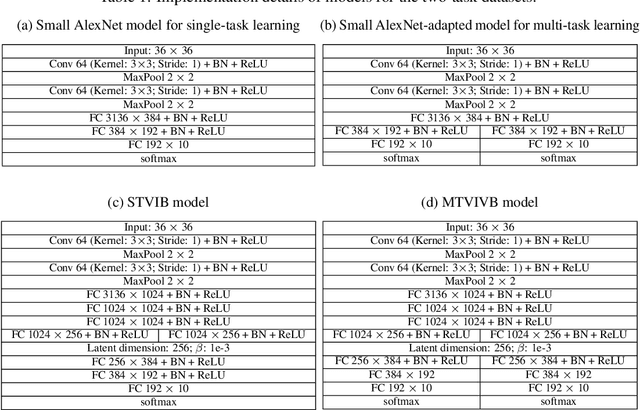

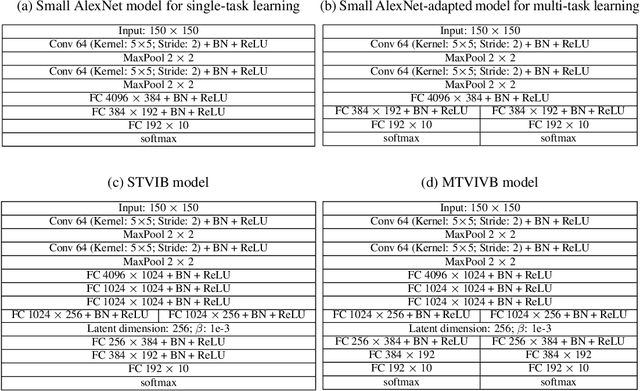
In this paper we propose a multi-task deep learning model called \emph{multi-task variational information bottleneck} (in short MTVIB). The structure of the variational information bottleneck (VIB) is used to obtain the latent representation of the input data; the task-dependent uncertainties are used to learn the relative weights of task loss functions; and the multi-task learning can be formulated as a constrained multi-objective optimization problem. Our model can enhance the latent representations and consider the trade-offs among different learning tasks. It is examined with publicly available datasets under different adversarial attacks. The overall classification performance of our model is promising. It can achieve comparable classification accuracies as the benchmarked models, and has shown a better robustness against adversarial attacks compared with other multi-task deep learning models.