 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmulating Clinician Cognition via Self-Evolving Deep Clinical Research
Mar 11, 2026Clinical diagnosis is a complex cognitive process, grounded in dynamic cue acquisition and continuous expertise accumulation. Yet most current artificial intelligence (AI) systems are misaligned with this reality, treating diagnosis as single-pass retrospective prediction while lacking auditable mechanisms for governed improvement. We developed DxEvolve, a self-evolving diagnostic agent that bridges these gaps through an interactive deep clinical research workflow. The framework autonomously requisitions examinations and continually externalizes clinical experience from increasing encounter exposure as diagnostic cognition primitives. On the MIMIC-CDM benchmark, DxEvolve improved diagnostic accuracy by 11.2% on average over backbone models and reached 90.4% on a reader-study subset, comparable to the clinician reference (88.8%). DxEvolve improved accuracy on an independent external cohort by 10.2% (categories covered by the source cohort) and 17.1% (uncovered categories) compared to the competitive method. By transforming experience into a governable learning asset, DxEvolve supports an accountable pathway for the continual evolution of clinical AI.
Adaptive debiased SGD in high-dimensional GLMs with steaming data
May 28, 2024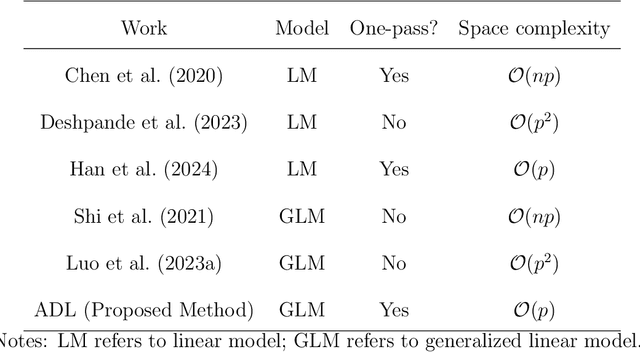
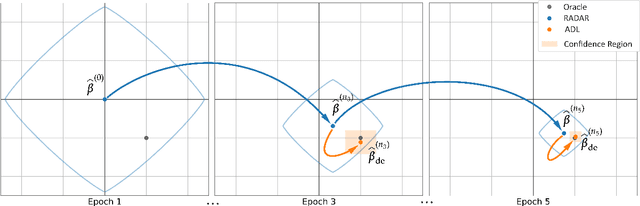

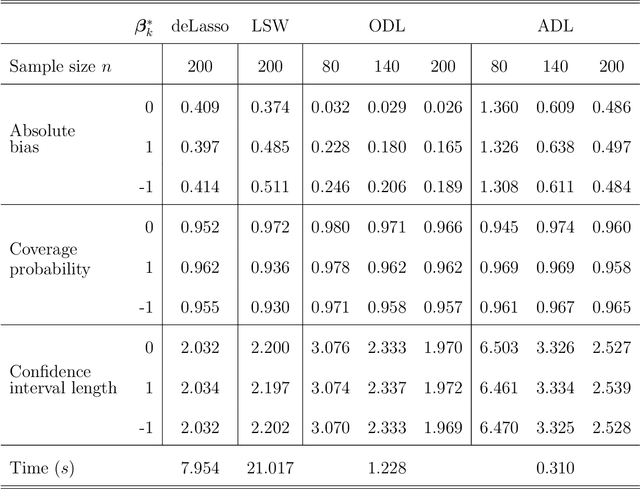
Online statistical inference facilitates real-time analysis of sequentially collected data, making it different from traditional methods that rely on static datasets. This paper introduces a novel approach to online inference in high-dimensional generalized linear models, where we update regression coefficient estimates and their standard errors upon each new data arrival. In contrast to existing methods that either require full dataset access or large-dimensional summary statistics storage, our method operates in a single-pass mode, significantly reducing both time and space complexity. The core of our methodological innovation lies in an adaptive stochastic gradient descent algorithm tailored for dynamic objective functions, coupled with a novel online debiasing procedure. This allows us to maintain low-dimensional summary statistics while effectively controlling optimization errors introduced by the dynamically changing loss functions. We demonstrate that our method, termed the Approximated Debiased Lasso (ADL), not only mitigates the need for the bounded individual probability condition but also significantly improves numerical performance. Numerical experiments demonstrate that the proposed ADL method consistently exhibits robust performance across various covariance matrix structures.
Latency-aware Road Anomaly Segmentation in Videos: A Photorealistic Dataset and New Metrics
Jan 10, 2024In the past several years, road anomaly segmentation is actively explored in the academia and drawing growing attention in the industry. The rationale behind is straightforward: if the autonomous car can brake before hitting an anomalous object, safety is promoted. However, this rationale naturally calls for a temporally informed setting while existing methods and benchmarks are designed in an unrealistic frame-wise manner. To bridge this gap, we contribute the first video anomaly segmentation dataset for autonomous driving. Since placing various anomalous objects on busy roads and annotating them in every frame are dangerous and expensive, we resort to synthetic data. To improve the relevance of this synthetic dataset to real-world applications, we train a generative adversarial network conditioned on rendering G-buffers for photorealism enhancement. Our dataset consists of 120,000 high-resolution frames at a 60 FPS framerate, as recorded in 7 different towns. As an initial benchmarking, we provide baselines using latest supervised and unsupervised road anomaly segmentation methods. Apart from conventional ones, we focus on two new metrics: temporal consistency and latencyaware streaming accuracy. We believe the latter is valuable as it measures whether an anomaly segmentation algorithm can truly prevent a car from crashing in a temporally informed setting.
Hyperlink-induced Pre-training for Passage Retrieval in Open-domain Question Answering
Apr 12, 2022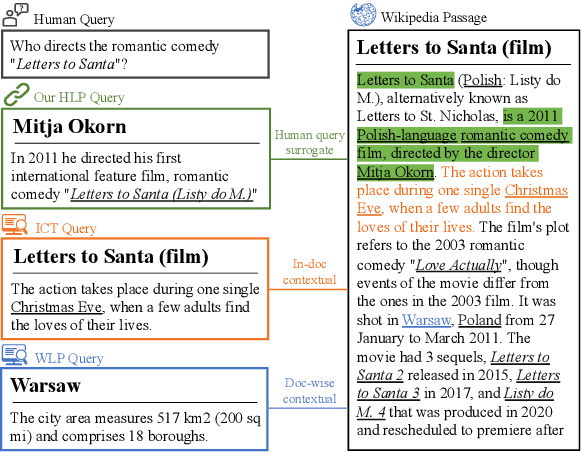
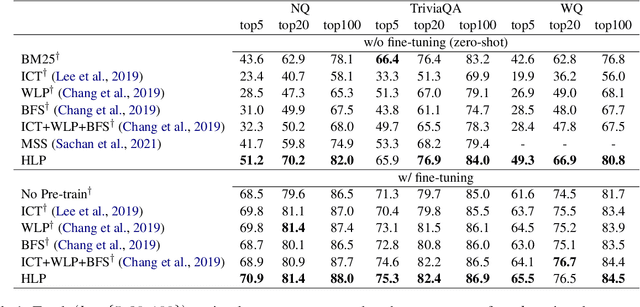
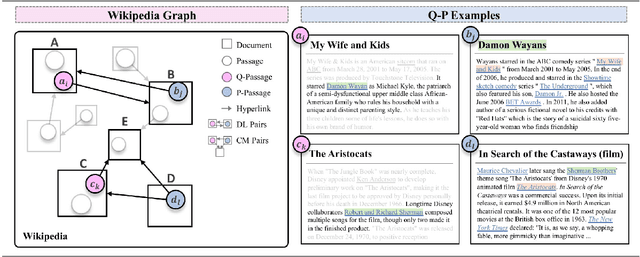
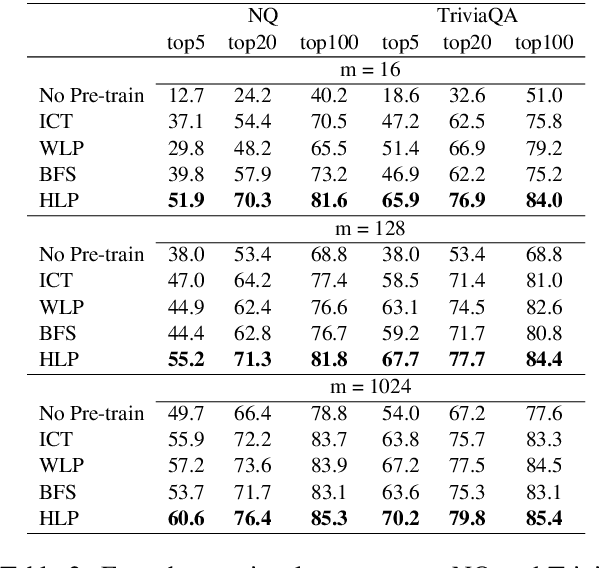
To alleviate the data scarcity problem in training question answering systems, recent works propose additional intermediate pre-training for dense passage retrieval (DPR). However, there still remains a large discrepancy between the provided upstream signals and the downstream question-passage relevance, which leads to less improvement. To bridge this gap, we propose the HyperLink-induced Pre-training (HLP), a method to pre-train the dense retriever with the text relevance induced by hyperlink-based topology within Web documents. We demonstrate that the hyperlink-based structures of dual-link and co-mention can provide effective relevance signals for large-scale pre-training that better facilitate downstream passage retrieval. We investigate the effectiveness of our approach across a wide range of open-domain QA datasets under zero-shot, few-shot, multi-hop, and out-of-domain scenarios. The experiments show our HLP outperforms the BM25 by up to 7 points as well as other pre-training methods by more than 10 points in terms of top-20 retrieval accuracy under the zero-shot scenario. Furthermore, HLP significantly outperforms other pre-training methods under the other scenarios.
DVM-CAR: A large-scale automotive dataset for visual marketing research and applications
Aug 10, 2021
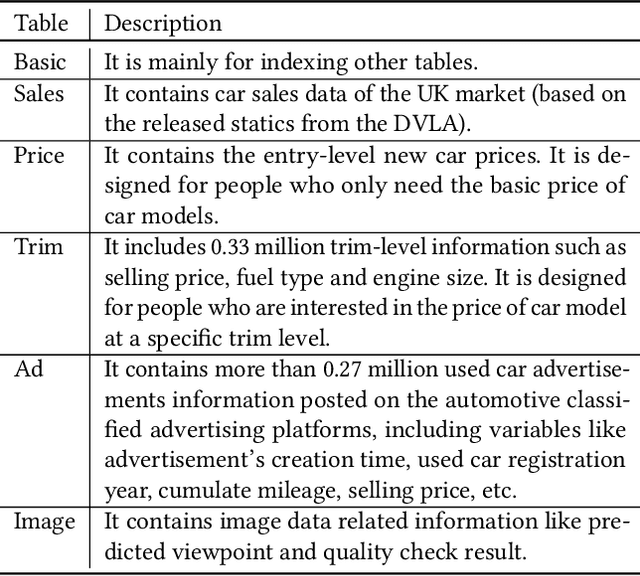

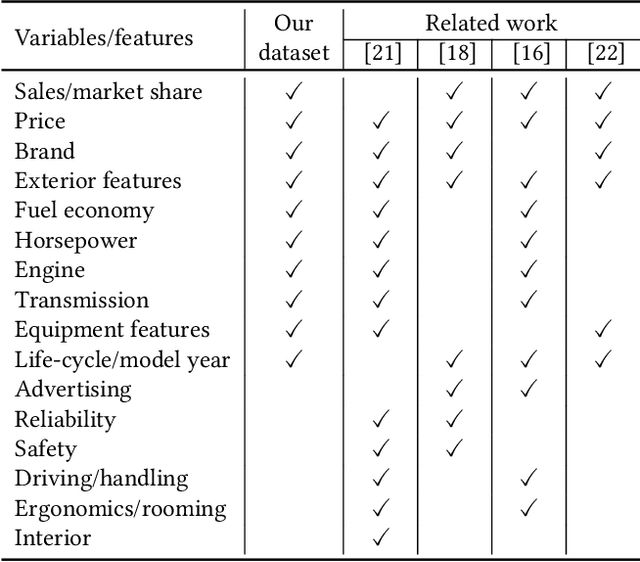
The automotive industry is being transformed by technologies, applications and services ranging from sensors to big data analytics and to artificial intelligence. In this paper, we present our multidisciplinary initiative of creating a publicly available dataset to facilitate the visual-related marketing research and applications in automotive industry such as automotive exterior design, consumer analytics and sales modelling. We are motivated by the fact that there is growing interest in product aesthetics but there is no large-scale dataset available that covers a wide range of variables and information. We summarise the common issues faced by marketing researchers and computer scientists through a user survey study, and design our dataset to alleviate these issues. Our dataset contains 1.4 million images from 899 car models as well as their corresponding car model specification and sales information over more than ten years in the UK market. To the best of our knowledge, this is the very first large-scale automotive dataset which contains images, text and sales information from multiple sources over a long period of time. We describe the detailed data structure and the preparation steps, which we believe has the methodological contribution to the multi-source data fusion and sharing. In addition, we discuss three dataset application examples to illustrate the value of our dataset.
Learning to Infer User Hidden States for Online Sequential Advertising
Sep 03, 2020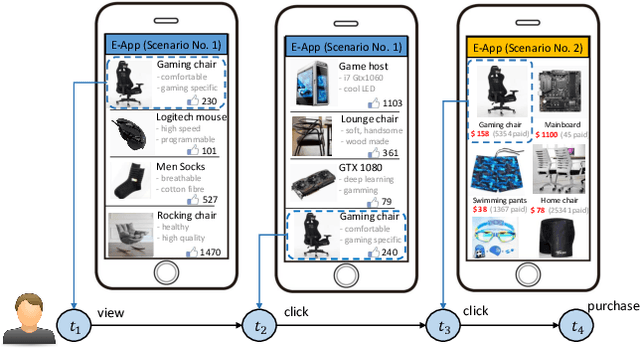
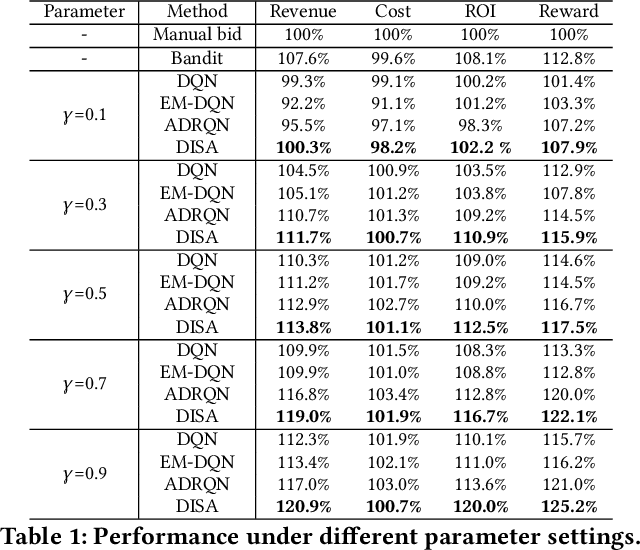
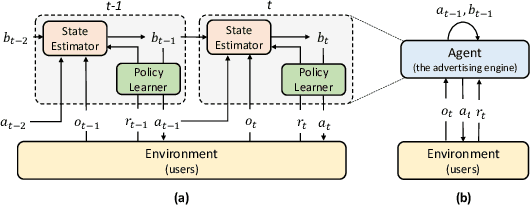
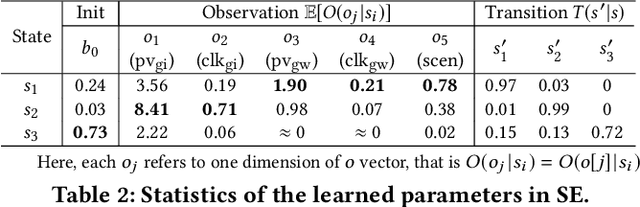
To drive purchase in online advertising, it is of the advertiser's great interest to optimize the sequential advertising strategy whose performance and interpretability are both important. The lack of interpretability in existing deep reinforcement learning methods makes it not easy to understand, diagnose and further optimize the strategy. In this paper, we propose our Deep Intents Sequential Advertising (DISA) method to address these issues. The key part of interpretability is to understand a consumer's purchase intent which is, however, unobservable (called hidden states). In this paper, we model this intention as a latent variable and formulate the problem as a Partially Observable Markov Decision Process (POMDP) where the underlying intents are inferred based on the observable behaviors. Large-scale industrial offline and online experiments demonstrate our method's superior performance over several baselines. The inferred hidden states are analyzed, and the results prove the rationality of our inference.