 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Apr 14, 2026On-policy distillation (OPD) has become a core technique in the post-training of large language models, yet its training dynamics remain poorly understood. This paper provides a systematic investigation of OPD dynamics and mechanisms. We first identify that two conditions govern whether OPD succeeds or fails: (i) the student and teacher should share compatible thinking patterns; and (ii) even with consistent thinking patterns and higher scores, the teacher must offer genuinely new capabilities beyond what the student has seen during training. We validate these findings through weak-to-strong reverse distillation, showing that same-family 1.5B and 7B teachers are distributionally indistinguishable from the student's perspective. Probing into the token-level mechanism, we show that successful OPD is characterized by progressive alignment on high-probability tokens at student-visited states, a small shared token set that concentrates most of the probability mass (97%-99%). We further propose two practical strategies to recover failing OPD: off-policy cold start and teacher-aligned prompt selection. Finally, we show that OPD's apparent free lunch of dense token-level reward comes at a cost, raising the question of whether OPD can scale to long-horizon distillation.
Benchmarking PhD-Level Coding in 3D Geometric Computer Vision
Mar 31, 2026AI-assisted coding has rapidly reshaped software practice and research workflows, yet today's models still struggle to produce correct code for complex 3D geometric vision. If models could reliably write such code, the research of our community would change substantially. To measure progress toward that goal, we introduce GeoCodeBench, a PhD-level benchmark that evaluates coding for 3D vision. Each problem is a fill-in-the-function implementation task curated from representative papers at recent venues: we first let a tool propose candidate functions from official repositories, then perform careful human screening to select core 3D geometric components. For every target, we generate diverse, edge-case unit tests, enabling fully automatic, reproducible scoring. We evaluate eight representative open- and closed-source models to reflect the current ecosystem. The best model, GPT-5, attains only 36.6% pass rate, revealing a large gap between current capabilities and dependable 3D scientific coding. GeoCodeBench organizes tasks into a two-level hierarchy: General 3D capability (geometric transformations and mechanics/optics formulation) and Research capability (novel algorithm implementation and geometric logic routing). Scores are positively correlated across these axes, but research-oriented tasks are markedly harder. Context ablations further show that "more paper text" is not always better: cutting off at the Method section statistically outperforms full-paper inputs, highlighting unresolved challenges in long-context scientific comprehension. Together, these findings position GeoCodeBench as a rigorous testbed for advancing from generic coding to trustworthy 3D geometric vision coding.
PAM: A Pose-Appearance-Motion Engine for Sim-to-Real HOI Video Generation
Mar 23, 2026Hand-object interaction (HOI) reconstruction and synthesis are becoming central to embodied AI and AR/VR. Yet, despite rapid progress, existing HOI generation research remains fragmented across three disjoint tracks: (1) pose-only synthesis that predicts MANO trajectories without producing pixels; (2) single-image HOI generation that hallucinates appearance from masks or 2D cues but lacks dynamics; and (3) video generation methods that require both the entire pose sequence and the ground-truth first frame as inputs, preventing true sim-to-real deployment. Inspired by the philosophy of Joo et al. (2018), we think that HOI generation requires a unified engine that brings together pose, appearance, and motion within one coherent framework. Thus we introduce PAM: a Pose-Appearance-Motion Engine for controllable HOI video generation. The performance of our engine is validated by: (1) On DexYCB, we obtain an FVD of 29.13 (vs. 38.83 for InterDyn), and MPJPE of 19.37 mm (vs. 30.05 mm for CosHand), while generating higher-resolution 480x720 videos compared to 256x256 and 256x384 baselines. (2) On OAKINK2, our full multi-condition model improves FVD from 68.76 to 46.31. (3) An ablation over input conditions on DexYCB shows that combining depth, segmentation, and keypoints consistently yields the best results. (4) For a downstream hand pose estimation task using SimpleHand, augmenting training with 3,400 synthetic videos (207k frames) allows a model trained on only 50% of the real data plus our synthetic data to match the 100% real baseline.
ManiTwin: Scaling Data-Generation-Ready Digital Object Dataset to 100K
Mar 17, 2026Learning in simulation provides a useful foundation for scaling robotic manipulation capabilities. However, this paradigm often suffers from a lack of data-generation-ready digital assets, in both scale and diversity. In this work, we present ManiTwin, an automated and efficient pipeline for generating data-generation-ready digital object twins. Our pipeline transforms a single image into simulation-ready and semantically annotated 3D asset, enabling large-scale robotic manipulation data generation. Using this pipeline, we construct ManiTwin-100K, a dataset containing 100K high-quality annotated 3D assets. Each asset is equipped with physical properties, language descriptions, functional annotations, and verified manipulation proposals. Experiments demonstrate that ManiTwin provides an efficient asset synthesis and annotation workflow, and that ManiTwin-100K offers high-quality and diverse assets for manipulation data generation, random scene synthesis, and VQA data generation, establishing a strong foundation for scalable simulation data synthesis and policy learning. Our webpage is available at https://manitwin.github.io/.
How Far Can Unsupervised RLVR Scale LLM Training?
Mar 09, 2026Unsupervised reinforcement learning with verifiable rewards (URLVR) offers a pathway to scale LLM training beyond the supervision bottleneck by deriving rewards without ground truth labels. Recent works leverage model intrinsic signals, showing promising early gains, yet their potential and limitations remain unclear. In this work, we revisit URLVR and provide a comprehensive analysis spanning taxonomy, theory and extensive experiments. We first classify URLVR methods into intrinsic versus external based on reward sources, then establish a unified theoretical framework revealing that all intrinsic methods converge toward sharpening the model's initial distribution This sharpening mechanism succeeds when initial confidence aligns with correctness but fails catastrophically when misaligned. Through systematic experiments, we show intrinsic rewards consistently follow a rise-then-fall pattern across methods, with collapse timing determined by model prior rather than engineering choices. Despite these scaling limits, we find intrinsic rewards remain valuable in test-time training on small datasets, and propose Model Collapse Step to measure model prior, serving as a practical indicator for RL trainability. Finally, we explore external reward methods that ground verification in computational asymmetries, showing preliminary evidence they may escape the confidence-correctness ceiling. Our findings chart boundaries for intrinsic URLVR while motivating paths toward scalable alternatives.
CUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation
Feb 27, 2026GPU kernel optimization is fundamental to modern deep learning but remains a highly specialized task requiring deep hardware expertise. Despite strong performance in general programming, large language models (LLMs) remain uncompetitive with compiler-based systems such as torch.compile for CUDA kernel generation. Existing CUDA code generation approaches either rely on training-free refinement or fine-tune models within fixed multi-turn execution-feedback loops, but both paradigms fail to fundamentally improve the model's intrinsic CUDA optimization ability, resulting in limited performance gains. We present CUDA Agent, a large-scale agentic reinforcement learning system that develops CUDA kernel expertise through three components: a scalable data synthesis pipeline, a skill-augmented CUDA development environment with automated verification and profiling to provide reliable reward signals, and reinforcement learning algorithmic techniques enabling stable training. CUDA Agent achieves state-of-the-art results on KernelBench, delivering 100\%, 100\%, and 92\% faster rate over torch.compile on KernelBench Level-1, Level-2, and Level-3 splits, outperforming the strongest proprietary models such as Claude Opus 4.5 and Gemini 3 Pro by about 40\% on the hardest Level-3 setting.
CubeBench: Diagnosing Interactive, Long-Horizon Spatial Reasoning Under Partial Observations
Dec 30, 2025Large Language Model (LLM) agents, while proficient in the digital realm, face a significant gap in physical-world deployment due to the challenge of forming and maintaining a robust spatial mental model. We identify three core cognitive challenges hindering this transition: spatial reasoning, long-horizon state tracking via mental simulation, and active exploration under partial observation. To isolate and evaluate these faculties, we introduce CubeBench, a novel generative benchmark centered on the Rubik's Cube. CubeBench uses a three-tiered diagnostic framework that progressively assesses agent capabilities, from foundational state tracking with full symbolic information to active exploration with only partial visual data. Our experiments on leading LLMs reveal critical limitations, including a uniform 0.00% pass rate on all long-horizon tasks, exposing a fundamental failure in long-term planning. We also propose a diagnostic framework to isolate these cognitive bottlenecks by providing external solver tools. By analyzing the failure modes, we provide key insights to guide the development of more physically-grounded intelligent agents.
RoboChemist: Long-Horizon and Safety-Compliant Robotic Chemical Experimentation
Sep 10, 2025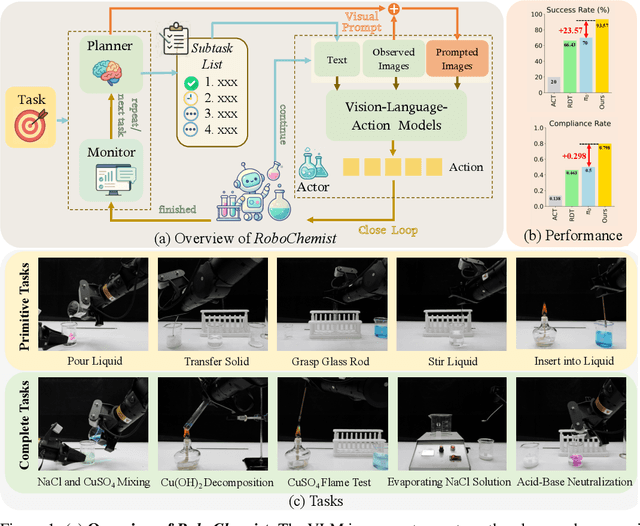



Robotic chemists promise to both liberate human experts from repetitive tasks and accelerate scientific discovery, yet remain in their infancy. Chemical experiments involve long-horizon procedures over hazardous and deformable substances, where success requires not only task completion but also strict compliance with experimental norms. To address these challenges, we propose \textit{RoboChemist}, a dual-loop framework that integrates Vision-Language Models (VLMs) with Vision-Language-Action (VLA) models. Unlike prior VLM-based systems (e.g., VoxPoser, ReKep) that rely on depth perception and struggle with transparent labware, and existing VLA systems (e.g., RDT, pi0) that lack semantic-level feedback for complex tasks, our method leverages a VLM to serve as (1) a planner to decompose tasks into primitive actions, (2) a visual prompt generator to guide VLA models, and (3) a monitor to assess task success and regulatory compliance. Notably, we introduce a VLA interface that accepts image-based visual targets from the VLM, enabling precise, goal-conditioned control. Our system successfully executes both primitive actions and complete multi-step chemistry protocols. Results show 23.57% higher average success rate and a 0.298 average increase in compliance rate over state-of-the-art VLA baselines, while also demonstrating strong generalization to objects and tasks.
TA-VLA: Elucidating the Design Space of Torque-aware Vision-Language-Action Models
Sep 09, 2025Many robotic manipulation tasks require sensing and responding to force signals such as torque to assess whether the task has been successfully completed and to enable closed-loop control. However, current Vision-Language-Action (VLA) models lack the ability to integrate such subtle physical feedback. In this work, we explore Torque-aware VLA models, aiming to bridge this gap by systematically studying the design space for incorporating torque signals into existing VLA architectures. We identify and evaluate several strategies, leading to three key findings. First, introducing torque adapters into the decoder consistently outperforms inserting them into the encoder.Third, inspired by joint prediction and planning paradigms in autonomous driving, we propose predicting torque as an auxiliary output, which further improves performance. This strategy encourages the model to build a physically grounded internal representation of interaction dynamics. Extensive quantitative and qualitative experiments across contact-rich manipulation benchmarks validate our findings.
A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
Jul 28, 2025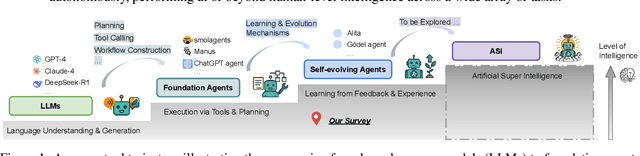

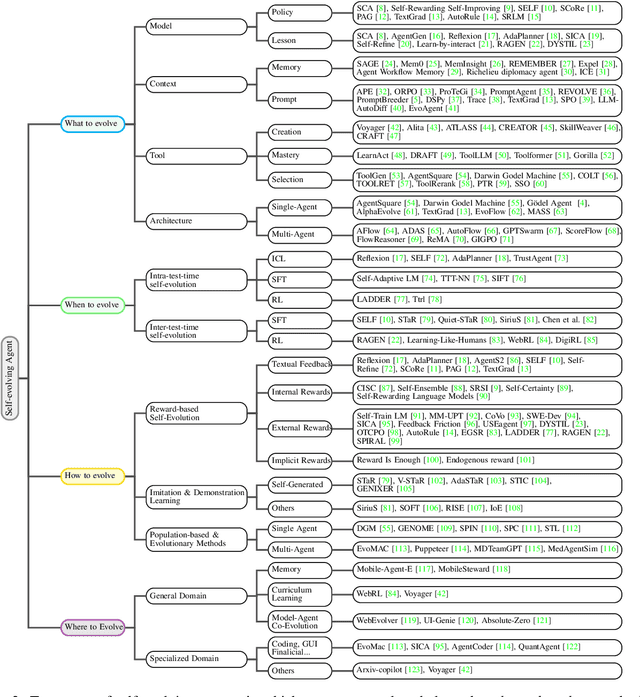
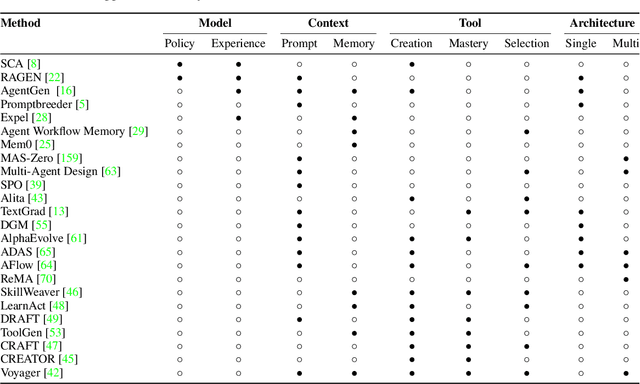
Large Language Models (LLMs) have demonstrated strong capabilities but remain fundamentally static, unable to adapt their internal parameters to novel tasks, evolving knowledge domains, or dynamic interaction contexts. As LLMs are increasingly deployed in open-ended, interactive environments, this static nature has become a critical bottleneck, necessitating agents that can adaptively reason, act, and evolve in real time. This paradigm shift -- from scaling static models to developing self-evolving agents -- has sparked growing interest in architectures and methods enabling continual learning and adaptation from data, interactions, and experiences. This survey provides the first systematic and comprehensive review of self-evolving agents, organized around three foundational dimensions -- what to evolve, when to evolve, and how to evolve. We examine evolutionary mechanisms across agent components (e.g., models, memory, tools, architecture), categorize adaptation methods by stages (e.g., intra-test-time, inter-test-time), and analyze the algorithmic and architectural designs that guide evolutionary adaptation (e.g., scalar rewards, textual feedback, single-agent and multi-agent systems). Additionally, we analyze evaluation metrics and benchmarks tailored for self-evolving agents, highlight applications in domains such as coding, education, and healthcare, and identify critical challenges and research directions in safety, scalability, and co-evolutionary dynamics. By providing a structured framework for understanding and designing self-evolving agents, this survey establishes a roadmap for advancing adaptive agentic systems in both research and real-world deployments, ultimately shedding lights to pave the way for the realization of Artificial Super Intelligence (ASI), where agents evolve autonomously, performing at or beyond human-level intelligence across a wide array of tasks.