 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccTENS: 3D Occupancy World Model via Temporal Next-Scale Prediction
Sep 04, 2025In this paper, we propose OccTENS, a generative occupancy world model that enables controllable, high-fidelity long-term occupancy generation while maintaining computational efficiency. Different from visual generation, the occupancy world model must capture the fine-grained 3D geometry and dynamic evolution of the 3D scenes, posing great challenges for the generative models. Recent approaches based on autoregression (AR) have demonstrated the potential to predict vehicle movement and future occupancy scenes simultaneously from historical observations, but they typically suffer from \textbf{inefficiency}, \textbf{temporal degradation} in long-term generation and \textbf{lack of controllability}. To holistically address these issues, we reformulate the occupancy world model as a temporal next-scale prediction (TENS) task, which decomposes the temporal sequence modeling problem into the modeling of spatial scale-by-scale generation and temporal scene-by-scene prediction. With a \textbf{TensFormer}, OccTENS can effectively manage the temporal causality and spatial relationships of occupancy sequences in a flexible and scalable way. To enhance the pose controllability, we further propose a holistic pose aggregation strategy, which features a unified sequence modeling for occupancy and ego-motion. Experiments show that OccTENS outperforms the state-of-the-art method with both higher occupancy quality and faster inference time.
LiloDriver: A Lifelong Learning Framework for Closed-loop Motion Planning in Long-tail Autonomous Driving Scenarios
May 22, 2025Recent advances in autonomous driving research towards motion planners that are robust, safe, and adaptive. However, existing rule-based and data-driven planners lack adaptability to long-tail scenarios, while knowledge-driven methods offer strong reasoning but face challenges in representation, control, and real-world evaluation. To address these challenges, we present LiloDriver, a lifelong learning framework for closed-loop motion planning in long-tail autonomous driving scenarios. By integrating large language models (LLMs) with a memory-augmented planner generation system, LiloDriver continuously adapts to new scenarios without retraining. It features a four-stage architecture including perception, scene encoding, memory-based strategy refinement, and LLM-guided reasoning. Evaluated on the nuPlan benchmark, LiloDriver achieves superior performance in both common and rare driving scenarios, outperforming static rule-based and learning-based planners. Our results highlight the effectiveness of combining structured memory and LLM reasoning to enable scalable, human-like motion planning in real-world autonomous driving. Our code is available at https://github.com/Hyan-Yao/LiloDriver.
PosePilot: Steering Camera Pose for Generative World Models with Self-supervised Depth
May 03, 2025Recent advancements in autonomous driving (AD) systems have highlighted the potential of world models in achieving robust and generalizable performance across both ordinary and challenging driving conditions. However, a key challenge remains: precise and flexible camera pose control, which is crucial for accurate viewpoint transformation and realistic simulation of scene dynamics. In this paper, we introduce PosePilot, a lightweight yet powerful framework that significantly enhances camera pose controllability in generative world models. Drawing inspiration from self-supervised depth estimation, PosePilot leverages structure-from-motion principles to establish a tight coupling between camera pose and video generation. Specifically, we incorporate self-supervised depth and pose readouts, allowing the model to infer depth and relative camera motion directly from video sequences. These outputs drive pose-aware frame warping, guided by a photometric warping loss that enforces geometric consistency across synthesized frames. To further refine camera pose estimation, we introduce a reverse warping step and a pose regression loss, improving viewpoint precision and adaptability. Extensive experiments on autonomous driving and general-domain video datasets demonstrate that PosePilot significantly enhances structural understanding and motion reasoning in both diffusion-based and auto-regressive world models. By steering camera pose with self-supervised depth, PosePilot sets a new benchmark for pose controllability, enabling physically consistent, reliable viewpoint synthesis in generative world models.
AVD2: Accident Video Diffusion for Accident Video Description
Feb 21, 2025Traffic accidents present complex challenges for autonomous driving, often featuring unpredictable scenarios that hinder accurate system interpretation and responses. Nonetheless, prevailing methodologies fall short in elucidating the causes of accidents and proposing preventive measures due to the paucity of training data specific to accident scenarios. In this work, we introduce AVD2 (Accident Video Diffusion for Accident Video Description), a novel framework that enhances accident scene understanding by generating accident videos that aligned with detailed natural language descriptions and reasoning, resulting in the contributed EMM-AU (Enhanced Multi-Modal Accident Video Understanding) dataset. Empirical results reveal that the integration of the EMM-AU dataset establishes state-of-the-art performance across both automated metrics and human evaluations, markedly advancing the domains of accident analysis and prevention. Project resources are available at https://an-answer-tree.github.io
Preliminary Investigation into Data Scaling Laws for Imitation Learning-Based End-to-End Autonomous Driving
Dec 03, 2024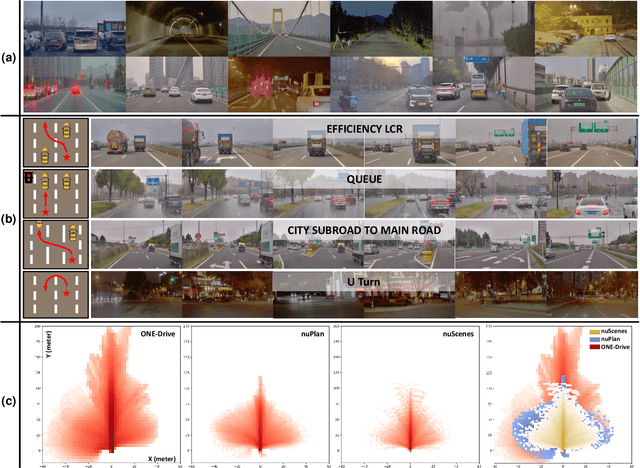
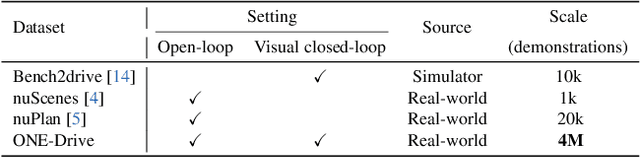

The end-to-end autonomous driving paradigm has recently attracted lots of attention due to its scalability. However, existing methods are constrained by the limited scale of real-world data, which hinders a comprehensive exploration of the scaling laws associated with end-to-end autonomous driving. To address this issue, we collected substantial data from various driving scenarios and behaviors and conducted an extensive study on the scaling laws of existing imitation learning-based end-to-end autonomous driving paradigms. Specifically, approximately 4 million demonstrations from 23 different scenario types were gathered, amounting to over 30,000 hours of driving demonstrations. We performed open-loop evaluations and closed-loop simulation evaluations in 1,400 diverse driving demonstrations (1,300 for open-loop and 100 for closed-loop) under stringent assessment conditions. Through experimental analysis, we discovered that (1) the performance of the driving model exhibits a power-law relationship with the amount of training data; (2) a small increase in the quantity of long-tailed data can significantly improve the performance for the corresponding scenarios; (3) appropriate scaling of data enables the model to achieve combinatorial generalization in novel scenes and actions. Our results highlight the critical role of data scaling in improving the generalizability of models across diverse autonomous driving scenarios, assuring safe deployment in the real world. Project repository: https://github.com/ucaszyp/Driving-Scaling-Law
DOME: Taming Diffusion Model into High-Fidelity Controllable Occupancy World Model
Oct 14, 2024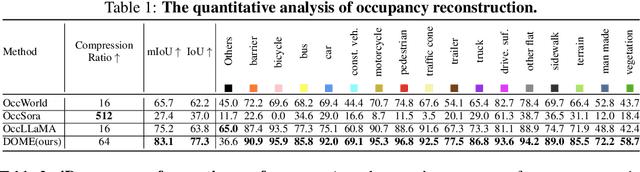

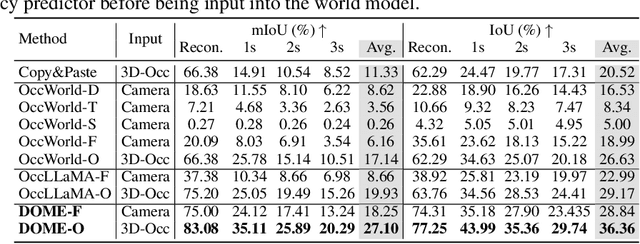
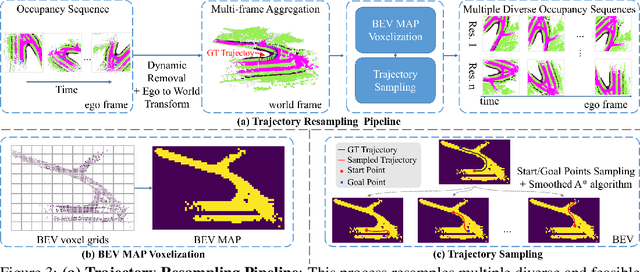
We propose DOME, a diffusion-based world model that predicts future occupancy frames based on past occupancy observations. The ability of this world model to capture the evolution of the environment is crucial for planning in autonomous driving. Compared to 2D video-based world models, the occupancy world model utilizes a native 3D representation, which features easily obtainable annotations and is modality-agnostic. This flexibility has the potential to facilitate the development of more advanced world models. Existing occupancy world models either suffer from detail loss due to discrete tokenization or rely on simplistic diffusion architectures, leading to inefficiencies and difficulties in predicting future occupancy with controllability. Our DOME exhibits two key features:(1) High-Fidelity and Long-Duration Generation. We adopt a spatial-temporal diffusion transformer to predict future occupancy frames based on historical context. This architecture efficiently captures spatial-temporal information, enabling high-fidelity details and the ability to generate predictions over long durations. (2)Fine-grained Controllability. We address the challenge of controllability in predictions by introducing a trajectory resampling method, which significantly enhances the model's ability to generate controlled predictions. Extensive experiments on the widely used nuScenes dataset demonstrate that our method surpasses existing baselines in both qualitative and quantitative evaluations, establishing a new state-of-the-art performance on nuScenes. Specifically, our approach surpasses the baseline by 10.5% in mIoU and 21.2% in IoU for occupancy reconstruction and by 36.0% in mIoU and 24.6% in IoU for 4D occupancy forecasting.
Hint-AD: Holistically Aligned Interpretability in End-to-End Autonomous Driving
Sep 10, 2024
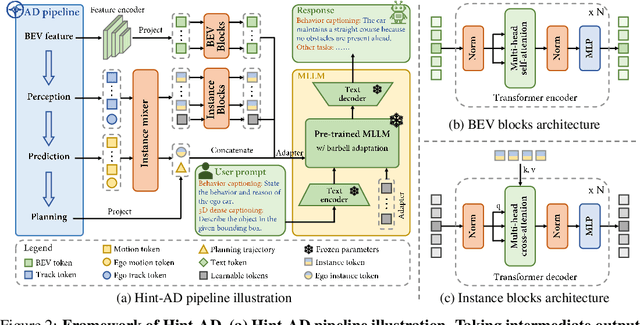

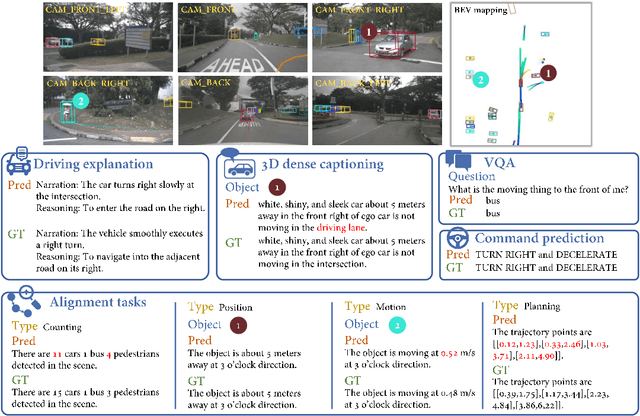
End-to-end architectures in autonomous driving (AD) face a significant challenge in interpretability, impeding human-AI trust. Human-friendly natural language has been explored for tasks such as driving explanation and 3D captioning. However, previous works primarily focused on the paradigm of declarative interpretability, where the natural language interpretations are not grounded in the intermediate outputs of AD systems, making the interpretations only declarative. In contrast, aligned interpretability establishes a connection between language and the intermediate outputs of AD systems. Here we introduce Hint-AD, an integrated AD-language system that generates language aligned with the holistic perception-prediction-planning outputs of the AD model. By incorporating the intermediate outputs and a holistic token mixer sub-network for effective feature adaptation, Hint-AD achieves desirable accuracy, achieving state-of-the-art results in driving language tasks including driving explanation, 3D dense captioning, and command prediction. To facilitate further study on driving explanation task on nuScenes, we also introduce a human-labeled dataset, Nu-X. Codes, dataset, and models will be publicly available.
HiPrompt: Tuning-free Higher-Resolution Generation with Hierarchical MLLM Prompts
Sep 04, 2024



The potential for higher-resolution image generation using pretrained diffusion models is immense, yet these models often struggle with issues of object repetition and structural artifacts especially when scaling to 4K resolution and higher. We figure out that the problem is caused by that, a single prompt for the generation of multiple scales provides insufficient efficacy. In response, we propose HiPrompt, a new tuning-free solution that tackles the above problems by introducing hierarchical prompts. The hierarchical prompts offer both global and local guidance. Specifically, the global guidance comes from the user input that describes the overall content, while the local guidance utilizes patch-wise descriptions from MLLMs to elaborately guide the regional structure and texture generation. Furthermore, during the inverse denoising process, the generated noise is decomposed into low- and high-frequency spatial components. These components are conditioned on multiple prompt levels, including detailed patch-wise descriptions and broader image-level prompts, facilitating prompt-guided denoising under hierarchical semantic guidance. It further allows the generation to focus more on local spatial regions and ensures the generated images maintain coherent local and global semantics, structures, and textures with high definition. Extensive experiments demonstrate that HiPrompt outperforms state-of-the-art works in higher-resolution image generation, significantly reducing object repetition and enhancing structural quality.
PlanAgent: A Multi-modal Large Language Agent for Closed-loop Vehicle Motion Planning
Jun 04, 2024



Vehicle motion planning is an essential component of autonomous driving technology. Current rule-based vehicle motion planning methods perform satisfactorily in common scenarios but struggle to generalize to long-tailed situations. Meanwhile, learning-based methods have yet to achieve superior performance over rule-based approaches in large-scale closed-loop scenarios. To address these issues, we propose PlanAgent, the first mid-to-mid planning system based on a Multi-modal Large Language Model (MLLM). MLLM is used as a cognitive agent to introduce human-like knowledge, interpretability, and common-sense reasoning into the closed-loop planning. Specifically, PlanAgent leverages the power of MLLM through three core modules. First, an Environment Transformation module constructs a Bird's Eye View (BEV) map and a lane-graph-based textual description from the environment as inputs. Second, a Reasoning Engine module introduces a hierarchical chain-of-thought from scene understanding to lateral and longitudinal motion instructions, culminating in planner code generation. Last, a Reflection module is integrated to simulate and evaluate the generated planner for reducing MLLM's uncertainty. PlanAgent is endowed with the common-sense reasoning and generalization capability of MLLM, which empowers it to effectively tackle both common and complex long-tailed scenarios. Our proposed PlanAgent is evaluated on the large-scale and challenging nuPlan benchmarks. A comprehensive set of experiments convincingly demonstrates that PlanAgent outperforms the existing state-of-the-art in the closed-loop motion planning task. Codes will be soon released.
TOD3Cap: Towards 3D Dense Captioning in Outdoor Scenes
Mar 28, 2024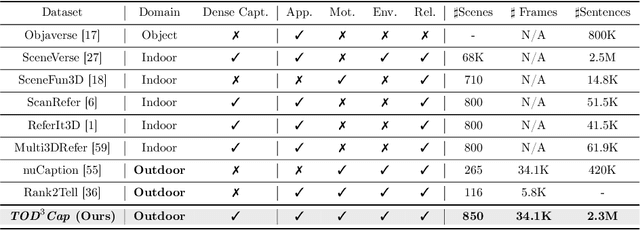
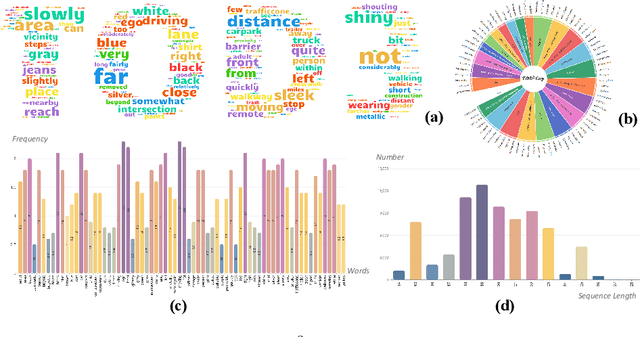

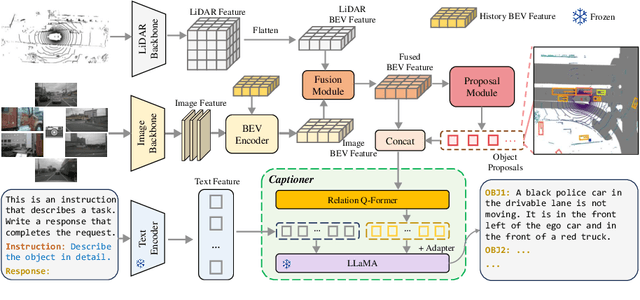
3D dense captioning stands as a cornerstone in achieving a comprehensive understanding of 3D scenes through natural language. It has recently witnessed remarkable achievements, particularly in indoor settings. However, the exploration of 3D dense captioning in outdoor scenes is hindered by two major challenges: 1) the \textbf{domain gap} between indoor and outdoor scenes, such as dynamics and sparse visual inputs, makes it difficult to directly adapt existing indoor methods; 2) the \textbf{lack of data} with comprehensive box-caption pair annotations specifically tailored for outdoor scenes. To this end, we introduce the new task of outdoor 3D dense captioning. As input, we assume a LiDAR point cloud and a set of RGB images captured by the panoramic camera rig. The expected output is a set of object boxes with captions. To tackle this task, we propose the TOD3Cap network, which leverages the BEV representation to generate object box proposals and integrates Relation Q-Former with LLaMA-Adapter to generate rich captions for these objects. We also introduce the TOD3Cap dataset, the largest one to our knowledge for 3D dense captioning in outdoor scenes, which contains 2.3M descriptions of 64.3K outdoor objects from 850 scenes. Notably, our TOD3Cap network can effectively localize and caption 3D objects in outdoor scenes, which outperforms baseline methods by a significant margin (+9.6 CiDEr@0.5IoU). Code, data, and models are publicly available at https://github.com/jxbbb/TOD3Cap.