 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Language-Action Understanding and Generation for Autonomous Driving
Mar 02, 2026Vision-Language-Action (VLA) models are emerging as a promising paradigm for end-to-end autonomous driving, valued for their potential to leverage world knowledge and reason about complex driving scenes. However, existing methods suffer from two critical limitations: a persistent misalignment between language instructions and action outputs, and the inherent inefficiency of typical auto-regressive action generation. In this paper, we introduce LinkVLA, a novel architecture that directly addresses these challenges to enhance both alignment and efficiency. First, we establish a structural link by unifying language and action tokens into a shared discrete codebook, processed within a single multi-modal model. This structurally enforces cross-modal consistency from the ground up. Second, to create a deep semantic link, we introduce an auxiliary action understanding objective that trains the model to generate descriptive captions from trajectories, fostering a bidirectional language-action mapping. Finally, we replace the slow, step-by-step generation with a two-step coarse-to-fine generation method C2F that efficiently decodes the action sequence, saving 86% inference time. Experiments on closed-loop driving benchmarks show consistent gains in instruction following accuracy and driving performance, alongside reduced inference latency.
DriveCombo: Benchmarking Compositional Traffic Rule Reasoning in Autonomous Driving
Mar 02, 2026Multimodal Large Language Models (MLLMs) are rapidly becoming the intelligence brain of end-to-end autonomous driving systems. A key challenge is to assess whether MLLMs can truly understand and follow complex real-world traffic rules. However, existing benchmarks mainly focus on single-rule scenarios like traffic sign recognition, neglecting the complexity of multi-rule concurrency and conflicts in real driving. Consequently, models perform well on simple tasks but often fail or violate rules in real world complex situations. To bridge this gap, we propose DriveCombo, a text and vision-based benchmark for compositional traffic rule reasoning. Inspired by human drivers' cognitive development, we propose a systematic Five-Level Cognitive Ladder that evaluates reasoning from single-rule understanding to multi-rule integration and conflict resolution, enabling quantitative assessment across cognitive stages. We further propose a Rule2Scene Agent that maps language-based traffic rules to dynamic driving scenes through rule crafting and scene generation, enabling scene-level traffic rule visual reasoning. Evaluations of 14 mainstream MLLMs reveal performance drops as task complexity grows, particularly during rule conflicts. After splitting the dataset and fine-tuning on the training set, we further observe substantial improvements in both traffic rule reasoning and downstream planning capabilities. These results highlight the effectiveness of DriveCombo in advancing compliant and intelligent autonomous driving systems.
Efficient Token Pruning for LLaDA-V
Jan 28, 2026Diffusion-based large multimodal models, such as LLaDA-V, have demonstrated impressive capabilities in vision-language understanding and generation. However, their bidirectional attention mechanism and diffusion-style iterative denoising paradigm introduce significant computational overhead, as visual tokens are repeatedly processed across all layers and denoising steps. In this work, we conduct an in-depth attention analysis and reveal that, unlike autoregressive decoders, LLaDA-V aggregates cross-modal information predominantly in middle-to-late layers, leading to delayed semantic alignment. Motivated by this observation, we propose a structured token pruning strategy inspired by FastV, selectively removing a proportion of visual tokens at designated layers to reduce FLOPs while preserving critical semantic information. To the best of our knowledge, this is the first work to investigate structured token pruning in diffusion-based large multimodal models. Unlike FastV, which focuses on shallow-layer pruning, our method targets the middle-to-late layers of the first denoising step to align with LLaDA-V's delayed attention aggregation to maintain output quality, and the first-step pruning strategy reduces the computation across all subsequent steps. Our framework provides an empirical basis for efficient LLaDA-V inference and highlights the potential of vision-aware pruning in diffusion-based multimodal models. Across multiple benchmarks, our best configuration reduces computational cost by up to 65% while preserving an average of 95% task performance.
PlannerRFT: Reinforcing Diffusion Planners through Closed-Loop and Sample-Efficient Fine-Tuning
Jan 19, 2026Diffusion-based planners have emerged as a promising approach for human-like trajectory generation in autonomous driving. Recent works incorporate reinforcement fine-tuning to enhance the robustness of diffusion planners through reward-oriented optimization in a generation-evaluation loop. However, they struggle to generate multi-modal, scenario-adaptive trajectories, hindering the exploitation efficiency of informative rewards during fine-tuning. To resolve this, we propose PlannerRFT, a sample-efficient reinforcement fine-tuning framework for diffusion-based planners. PlannerRFT adopts a dual-branch optimization that simultaneously refines the trajectory distribution and adaptively guides the denoising process toward more promising exploration, without altering the original inference pipeline. To support parallel learning at scale, we develop nuMax, an optimized simulator that achieves 10 times faster rollout compared to native nuPlan. Extensive experiments shows that PlannerRFT yields state-of-the-art performance with distinct behaviors emerging during the learning process.
SGDrive: Scene-to-Goal Hierarchical World Cognition for Autonomous Driving
Jan 12, 2026Recent end-to-end autonomous driving approaches have leveraged Vision-Language Models (VLMs) to enhance planning capabilities in complex driving scenarios. However, VLMs are inherently trained as generalist models, lacking specialized understanding of driving-specific reasoning in 3D space and time. When applied to autonomous driving, these models struggle to establish structured spatial-temporal representations that capture geometric relationships, scene context, and motion patterns critical for safe trajectory planning. To address these limitations, we propose SGDrive, a novel framework that explicitly structures the VLM's representation learning around driving-specific knowledge hierarchies. Built upon a pre-trained VLM backbone, SGDrive decomposes driving understanding into a scene-agent-goal hierarchy that mirrors human driving cognition: drivers first perceive the overall environment (scene context), then attend to safety-critical agents and their behaviors, and finally formulate short-term goals before executing actions. This hierarchical decomposition provides the structured spatial-temporal representation that generalist VLMs lack, integrating multi-level information into a compact yet comprehensive format for trajectory planning. Extensive experiments on the NAVSIM benchmark demonstrate that SGDrive achieves state-of-the-art performance among camera-only methods on both PDMS and EPDMS, validating the effectiveness of hierarchical knowledge structuring for adapting generalist VLMs to autonomous driving.
DriveLiDAR4D: Sequential and Controllable LiDAR Scene Generation for Autonomous Driving
Nov 17, 2025The generation of realistic LiDAR point clouds plays a crucial role in the development and evaluation of autonomous driving systems. Although recent methods for 3D LiDAR point cloud generation have shown significant improvements, they still face notable limitations, including the lack of sequential generation capabilities and the inability to produce accurately positioned foreground objects and realistic backgrounds. These shortcomings hinder their practical applicability. In this paper, we introduce DriveLiDAR4D, a novel LiDAR generation pipeline consisting of multimodal conditions and a novel sequential noise prediction model LiDAR4DNet, capable of producing temporally consistent LiDAR scenes with highly controllable foreground objects and realistic backgrounds. To the best of our knowledge, this is the first work to address the sequential generation of LiDAR scenes with full scene manipulation capability in an end-to-end manner. We evaluated DriveLiDAR4D on the nuScenes and KITTI datasets, where we achieved an FRD score of 743.13 and an FVD score of 16.96 on the nuScenes dataset, surpassing the current state-of-the-art (SOTA) method, UniScene, with an performance boost of 37.2% in FRD and 24.1% in FVD, respectively.
The Better You Learn, The Smarter You Prune: Towards Efficient Vision-language-action Models via Differentiable Token Pruning
Sep 16, 2025We present LightVLA, a simple yet effective differentiable token pruning framework for vision-language-action (VLA) models. While VLA models have shown impressive capability in executing real-world robotic tasks, their deployment on resource-constrained platforms is often bottlenecked by the heavy attention-based computation over large sets of visual tokens. LightVLA addresses this challenge through adaptive, performance-driven pruning of visual tokens: It generates dynamic queries to evaluate visual token importance, and adopts Gumbel softmax to enable differentiable token selection. Through fine-tuning, LightVLA learns to preserve the most informative visual tokens while pruning tokens which do not contribute to task execution, thereby improving efficiency and performance simultaneously. Notably, LightVLA requires no heuristic magic numbers and introduces no additional trainable parameters, making it compatible with modern inference frameworks. Experimental results demonstrate that LightVLA outperforms different VLA models and existing token pruning methods across diverse tasks on the LIBERO benchmark, achieving higher success rates with substantially reduced computational overhead. Specifically, LightVLA reduces FLOPs and latency by 59.1% and 38.2% respectively, with a 2.9% improvement in task success rate. Meanwhile, we also investigate the learnable query-based token pruning method LightVLA* with additional trainable parameters, which also achieves satisfactory performance. Our work reveals that as VLA pursues optimal performance, LightVLA spontaneously learns to prune tokens from a performance-driven perspective. To the best of our knowledge, LightVLA is the first work to apply adaptive visual token pruning to VLA tasks with the collateral goals of efficiency and performance, marking a significant step toward more efficient, powerful and practical real-time robotic systems.
DriveAgent-R1: Advancing VLM-based Autonomous Driving with Hybrid Thinking and Active Perception
Jul 28, 2025Vision-Language Models (VLMs) are advancing autonomous driving, yet their potential is constrained by myopic decision-making and passive perception, limiting reliability in complex environments. We introduce DriveAgent-R1 to tackle these challenges in long-horizon, high-level behavioral decision-making. DriveAgent-R1 features two core innovations: a Hybrid-Thinking framework that adaptively switches between efficient text-based and in-depth tool-based reasoning, and an Active Perception mechanism with a vision toolkit to proactively resolve uncertainties, thereby balancing decision-making efficiency and reliability. The agent is trained using a novel, three-stage progressive reinforcement learning strategy designed to master these hybrid capabilities. Extensive experiments demonstrate that DriveAgent-R1 achieves state-of-the-art performance, outperforming even leading proprietary large multimodal models, such as Claude Sonnet 4. Ablation studies validate our approach and confirm that the agent's decisions are robustly grounded in actively perceived visual evidence, paving a path toward safer and more intelligent autonomous systems.
DriveAction: A Benchmark for Exploring Human-like Driving Decisions in VLA Models
Jun 06, 2025Vision-Language-Action (VLA) models have advanced autonomous driving, but existing benchmarks still lack scenario diversity, reliable action-level annotation, and evaluation protocols aligned with human preferences. To address these limitations, we introduce DriveAction, the first action-driven benchmark specifically designed for VLA models, comprising 16,185 QA pairs generated from 2,610 driving scenarios. DriveAction leverages real-world driving data proactively collected by users of production-level autonomous vehicles to ensure broad and representative scenario coverage, offers high-level discrete action labels collected directly from users' actual driving operations, and implements an action-rooted tree-structured evaluation framework that explicitly links vision, language, and action tasks, supporting both comprehensive and task-specific assessment. Our experiments demonstrate that state-of-the-art vision-language models (VLMs) require both vision and language guidance for accurate action prediction: on average, accuracy drops by 3.3% without vision input, by 4.1% without language input, and by 8.0% without either. Our evaluation supports precise identification of model bottlenecks with robust and consistent results, thus providing new insights and a rigorous foundation for advancing human-like decisions in autonomous driving.
TokenFLEX: Unified VLM Training for Flexible Visual Tokens Inference
Apr 04, 2025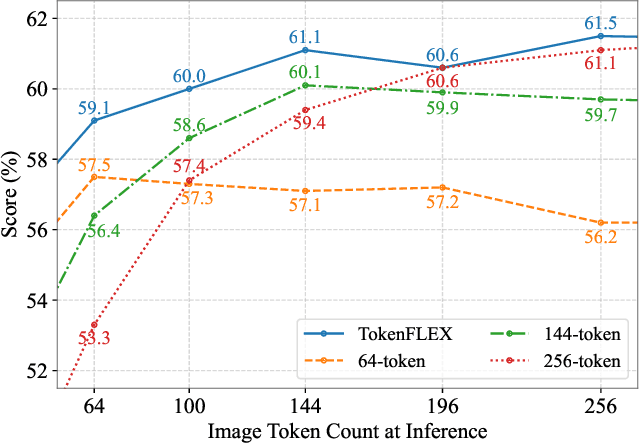
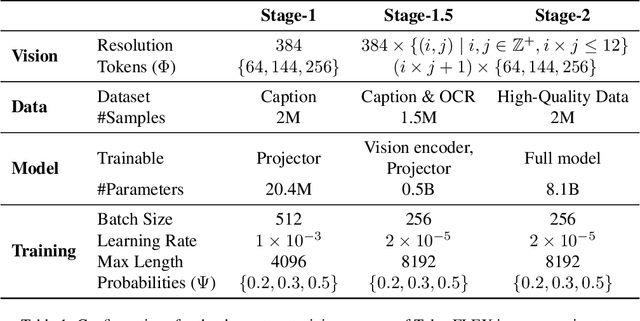
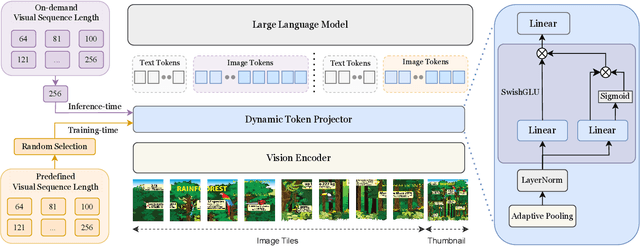
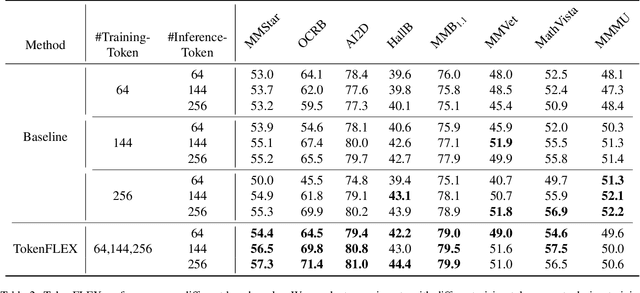
Conventional Vision-Language Models(VLMs) typically utilize a fixed number of vision tokens, regardless of task complexity. This one-size-fits-all strategy introduces notable inefficiencies: using excessive tokens leads to unnecessary computational overhead in simpler tasks, whereas insufficient tokens compromise fine-grained visual comprehension in more complex contexts. To overcome these limitations, we present TokenFLEX, an innovative and adaptable vision-language framework that encodes images into a variable number of tokens for efficient integration with a Large Language Model (LLM). Our approach is underpinned by two pivotal innovations. Firstly, we present a novel training paradigm that enhances performance across varying numbers of vision tokens by stochastically modulating token counts during training. Secondly, we design a lightweight vision token projector incorporating an adaptive pooling layer and SwiGLU, allowing for flexible downsampling of vision tokens and adaptive selection of features tailored to specific token counts. Comprehensive experiments reveal that TokenFLEX consistently outperforms its fixed-token counterparts, achieving notable performance gains across various token counts enhancements of 1.6%, 1.0%, and 0.4% with 64, 144, and 256 tokens, respectively averaged over eight vision-language benchmarks. These results underscore TokenFLEX's remarkable flexibility while maintaining high-performance vision-language understanding.