 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenFLEX: Unified VLM Training for Flexible Visual Tokens Inference
Apr 04, 2025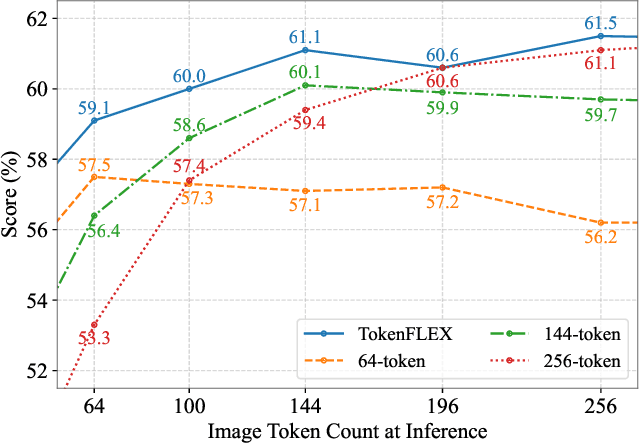
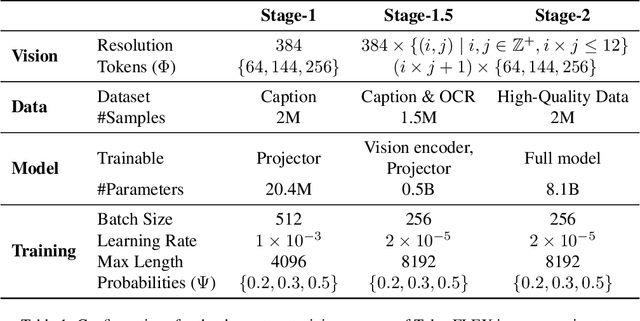
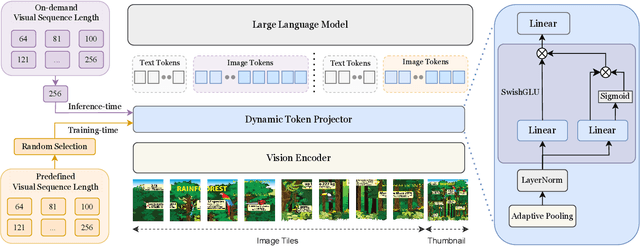
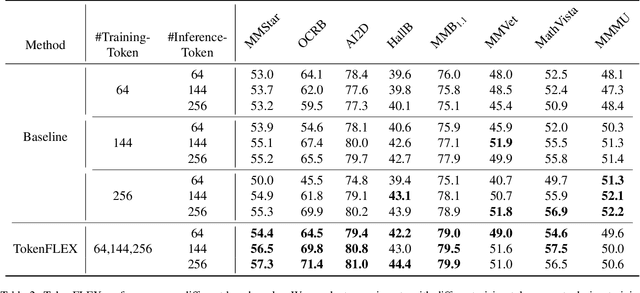
Conventional Vision-Language Models(VLMs) typically utilize a fixed number of vision tokens, regardless of task complexity. This one-size-fits-all strategy introduces notable inefficiencies: using excessive tokens leads to unnecessary computational overhead in simpler tasks, whereas insufficient tokens compromise fine-grained visual comprehension in more complex contexts. To overcome these limitations, we present TokenFLEX, an innovative and adaptable vision-language framework that encodes images into a variable number of tokens for efficient integration with a Large Language Model (LLM). Our approach is underpinned by two pivotal innovations. Firstly, we present a novel training paradigm that enhances performance across varying numbers of vision tokens by stochastically modulating token counts during training. Secondly, we design a lightweight vision token projector incorporating an adaptive pooling layer and SwiGLU, allowing for flexible downsampling of vision tokens and adaptive selection of features tailored to specific token counts. Comprehensive experiments reveal that TokenFLEX consistently outperforms its fixed-token counterparts, achieving notable performance gains across various token counts enhancements of 1.6%, 1.0%, and 0.4% with 64, 144, and 256 tokens, respectively averaged over eight vision-language benchmarks. These results underscore TokenFLEX's remarkable flexibility while maintaining high-performance vision-language understanding.
Estimation of Reliable Proposal Quality for Temporal Action Detection
Apr 25, 2022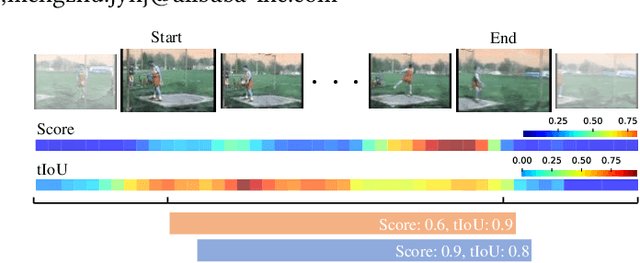

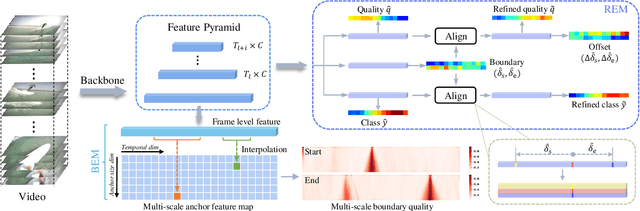

Temporal action detection (TAD) aims to locate and recognize the actions in an untrimmed video. Anchor-free methods have made remarkable progress which mainly formulate TAD into two tasks: classification and localization using two separate branches. This paper reveals the temporal misalignment between the two tasks hindering further progress. To address this, we propose a new method that gives insights into moment and region perspectives simultaneously to align the two tasks by acquiring reliable proposal quality. For the moment perspective, Boundary Evaluate Module (BEM) is designed which focuses on local appearance and motion evolvement to estimate boundary quality and adopts a multi-scale manner to deal with varied action durations. For the region perspective, we introduce Region Evaluate Module (REM) which uses a new and efficient sampling method for proposal feature representation containing more contextual information compared with point feature to refine category score and proposal boundary. The proposed Boundary Evaluate Module and Region Evaluate Module (BREM) are generic, and they can be easily integrated with other anchor-free TAD methods to achieve superior performance. In our experiments, BREM is combined with two different frameworks and improves the performance on THUMOS14 by 3.6$\%$ and 1.0$\%$ respectively, reaching a new state-of-the-art (63.6$\%$ average $m$AP). Meanwhile, a competitive result of 36.2\% average $m$AP is achieved on ActivityNet-1.3 with the consistent improvement of BREM.