 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Rollout from Sampling:An R1-Style Tokenized Traffic Simulation Model
Mar 26, 2026Learning diverse and high-fidelity traffic simulations from human driving demonstrations is crucial for autonomous driving evaluation. The recent next-token prediction (NTP) paradigm, widely adopted in large language models (LLMs), has been applied to traffic simulation and achieves iterative improvements via supervised fine-tuning (SFT). However, such methods limit active exploration of potentially valuable motion tokens, particularly in suboptimal regions. Entropy patterns provide a promising perspective for enabling exploration driven by motion token uncertainty. Motivated by this insight, we propose a novel tokenized traffic simulation policy, R1Sim, which represents an initial attempt to explore reinforcement learning based on motion token entropy patterns, and systematically analyzes the impact of different motion tokens on simulation outcomes. Specifically, we introduce an entropy-guided adaptive sampling mechanism that focuses on previously overlooked motion tokens with high uncertainty yet high potential. We further optimize motion behaviors using Group Relative Policy Optimization (GRPO), guided by a safety-aware reward design. Overall, these components enable a balanced exploration-exploitation trade-off through diverse high-uncertainty sampling and group-wise comparative estimation, resulting in realistic, safe, and diverse multi-agent behaviors. Extensive experiments on the Waymo Sim Agent benchmark demonstrate that R1Sim achieves competitive performance compared to state-of-the-art methods.
DreamerAD: Efficient Reinforcement Learning via Latent World Model for Autonomous Driving
Mar 25, 2026We introduce DreamerAD, the first latent world model framework that enables efficient reinforcement learning for autonomous driving by compressing diffusion sampling from 100 steps to 1 - achieving 80x speedup while maintaining visual interpretability. Training RL policies on real-world driving data incurs prohibitive costs and safety risks. While existing pixel-level diffusion world models enable safe imagination-based training, they suffer from multi-step diffusion inference latency (2s/frame) that prevents high-frequency RL interaction. Our approach leverages denoised latent features from video generation models through three key mechanisms: (1) shortcut forcing that reduces sampling complexity via recursive multi-resolution step compression, (2) an autoregressive dense reward model operating directly on latent representations for fine-grained credit assignment, and (3) Gaussian vocabulary sampling for GRPO that constrains exploration to physically plausible trajectories. DreamerAD achieves 87.7 EPDMS on NavSim v2, establishing state-of-the-art performance and demonstrating that latent-space RL is effective for autonomous driving.
PerlAD: Towards Enhanced Closed-loop End-to-end Autonomous Driving with Pseudo-simulation-based Reinforcement Learning
Mar 16, 2026End-to-end autonomous driving policies based on Imitation Learning (IL) often struggle in closed-loop execution due to the misalignment between inadequate open-loop training objectives and real driving requirements. While Reinforcement Learning (RL) offers a solution by directly optimizing driving goals via reward signals, the rendering-based training environments introduce the rendering gap and are inefficient due to high computational costs. To overcome these challenges, we present a novel Pseudo-simulation-based RL method for closed-loop end-to-end autonomous driving, PerlAD. Based on offline datasets, PerlAD constructs a pseudo-simulation that operates in vector space, enabling efficient, rendering-free trial-and-error training. To bridge the gap between static datasets and dynamic closed-loop environments, PerlAD introduces a prediction world model that generates reactive agent trajectories conditioned on the ego vehicle's plan. Furthermore, to facilitate efficient planning, PerlAD utilizes a hierarchical decoupled planner that combines IL for lateral path generation and RL for longitudinal speed optimization. Comprehensive experimental results demonstrate that PerlAD achieves state-of-the-art performance on the Bench2Drive benchmark, surpassing the previous E2E RL method by 10.29% in Driving Score without requiring expensive online interactions. Additional evaluations on the DOS benchmark further confirm its reliability in handling safety-critical occlusion scenarios.
MeanFuser: Fast One-Step Multi-Modal Trajectory Generation and Adaptive Reconstruction via MeanFlow for End-to-End Autonomous Driving
Feb 23, 2026Generative models have shown great potential in trajectory planning. Recent studies demonstrate that anchor-guided generative models are effective in modeling the uncertainty of driving behaviors and improving overall performance. However, these methods rely on discrete anchor vocabularies that must sufficiently cover the trajectory distribution during testing to ensure robustness, inducing an inherent trade-off between vocabulary size and model performance. To overcome this limitation, we propose MeanFuser, an end-to-end autonomous driving method that enhances both efficiency and robustness through three key designs. (1) We introduce Gaussian Mixture Noise (GMN) to guide generative sampling, enabling a continuous representation of the trajectory space and eliminating the dependency on discrete anchor vocabularies. (2) We adapt ``MeanFlow Identity" to end-to-end planning, which models the mean velocity field between GMN and trajectory distribution instead of the instantaneous velocity field used in vanilla flow matching methods, effectively eliminating numerical errors from ODE solvers and significantly accelerating inference. (3) We design a lightweight Adaptive Reconstruction Module (ARM) that enables the model to implicitly select from all sampled proposals or reconstruct a new trajectory when none is satisfactory via attention weights. Experiments on the NAVSIM closed-loop benchmark demonstrate that MeanFuser achieves outstanding performance without the supervision of the PDM Score. and exceptional inference efficiency, offering a robust and efficient solution for end-to-end autonomous driving. Our code and model are available at https://github.com/wjl2244/MeanFuser.
TakeAD: Preference-based Post-optimization for End-to-end Autonomous Driving with Expert Takeover Data
Dec 22, 2025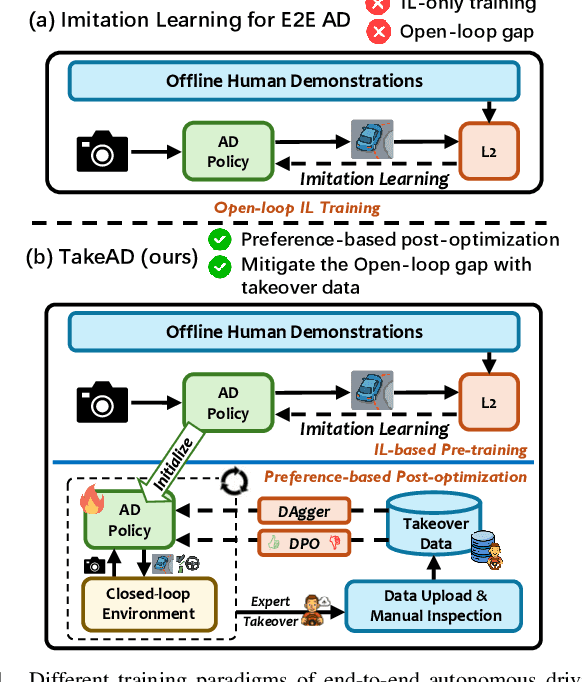
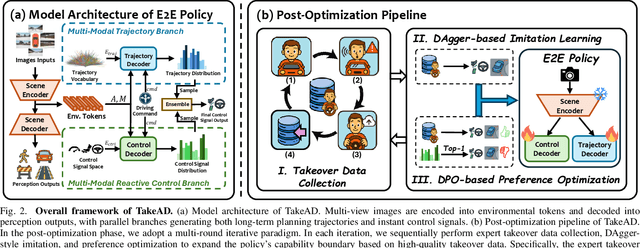
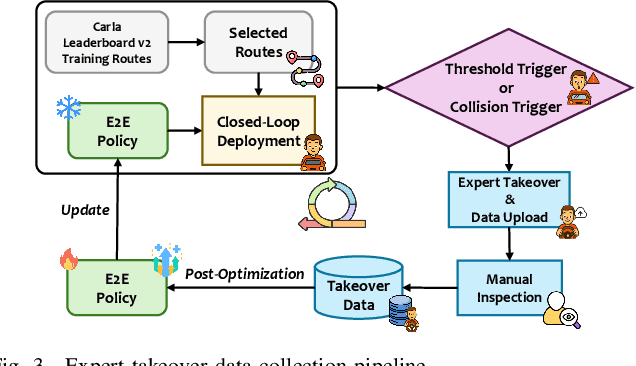
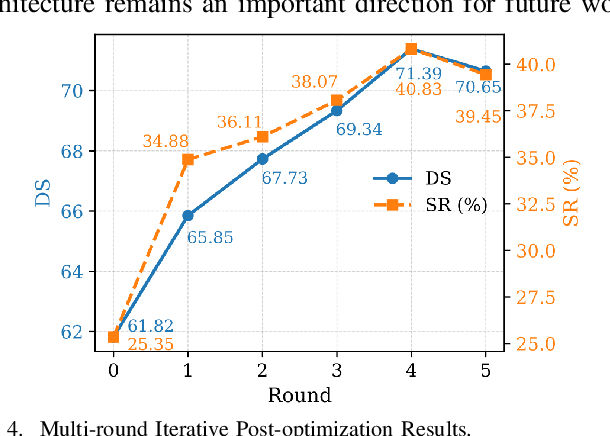
Existing end-to-end autonomous driving methods typically rely on imitation learning (IL) but face a key challenge: the misalignment between open-loop training and closed-loop deployment. This misalignment often triggers driver-initiated takeovers and system disengagements during closed-loop execution. How to leverage those expert takeover data from disengagement scenarios and effectively expand the IL policy's capability presents a valuable yet unexplored challenge. In this paper, we propose TakeAD, a novel preference-based post-optimization framework that fine-tunes the pre-trained IL policy with this disengagement data to enhance the closed-loop driving performance. First, we design an efficient expert takeover data collection pipeline inspired by human takeover mechanisms in real-world autonomous driving systems. Then, this post optimization framework integrates iterative Dataset Aggregation (DAgger) for imitation learning with Direct Preference Optimization (DPO) for preference alignment. The DAgger stage equips the policy with fundamental capabilities to handle disengagement states through direct imitation of expert interventions. Subsequently, the DPO stage refines the policy's behavior to better align with expert preferences in disengagement scenarios. Through multiple iterations, the policy progressively learns recovery strategies for disengagement states, thereby mitigating the open-loop gap. Experiments on the closed-loop Bench2Drive benchmark demonstrate our method's effectiveness compared with pure IL methods, with comprehensive ablations confirming the contribution of each component.
WorldRFT: Latent World Model Planning with Reinforcement Fine-Tuning for Autonomous Driving
Dec 22, 2025Latent World Models enhance scene representation through temporal self-supervised learning, presenting a perception annotation-free paradigm for end-to-end autonomous driving. However, the reconstruction-oriented representation learning tangles perception with planning tasks, leading to suboptimal optimization for planning. To address this challenge, we propose WorldRFT, a planning-oriented latent world model framework that aligns scene representation learning with planning via a hierarchical planning decomposition and local-aware interactive refinement mechanism, augmented by reinforcement learning fine-tuning (RFT) to enhance safety-critical policy performance. Specifically, WorldRFT integrates a vision-geometry foundation model to improve 3D spatial awareness, employs hierarchical planning task decomposition to guide representation optimization, and utilizes local-aware iterative refinement to derive a planning-oriented driving policy. Furthermore, we introduce Group Relative Policy Optimization (GRPO), which applies trajectory Gaussianization and collision-aware rewards to fine-tune the driving policy, yielding systematic improvements in safety. WorldRFT achieves state-of-the-art (SOTA) performance on both open-loop nuScenes and closed-loop NavSim benchmarks. On nuScenes, it reduces collision rates by 83% (0.30% -> 0.05%). On NavSim, using camera-only sensors input, it attains competitive performance with the LiDAR-based SOTA method DiffusionDrive (87.8 vs. 88.1 PDMS).
TransDiffuser: End-to-end Trajectory Generation with Decorrelated Multi-modal Representation for Autonomous Driving
May 14, 2025In recent years, diffusion model has shown its potential across diverse domains from vision generation to language modeling. Transferring its capabilities to modern autonomous driving systems has also emerged as a promising direction.In this work, we propose TransDiffuser, an encoder-decoder based generative trajectory planning model for end-to-end autonomous driving. The encoded scene information serves as the multi-modal conditional input of the denoising decoder. To tackle the mode collapse dilemma in generating high-quality diverse trajectories, we introduce a simple yet effective multi-modal representation decorrelation optimization mechanism during the training process.TransDiffuser achieves PDMS of 94.85 on the NAVSIM benchmark, surpassing previous state-of-the-art methods without any anchor-based prior trajectories.
TokenFLEX: Unified VLM Training for Flexible Visual Tokens Inference
Apr 04, 2025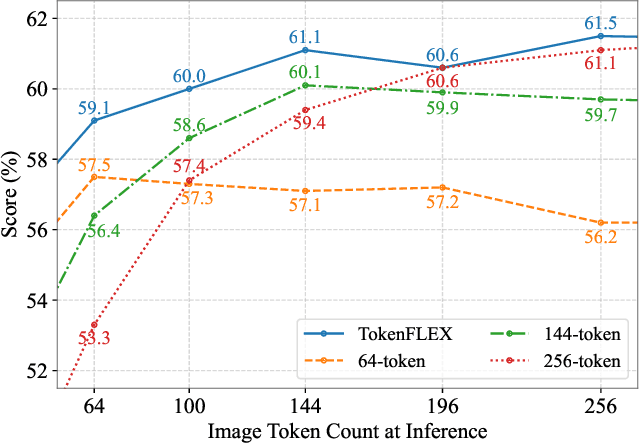
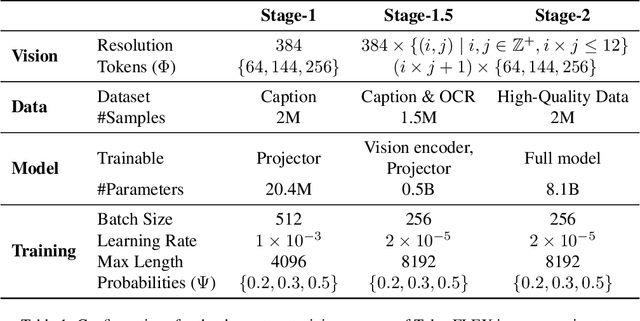
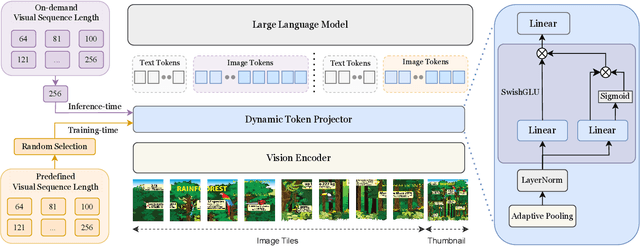
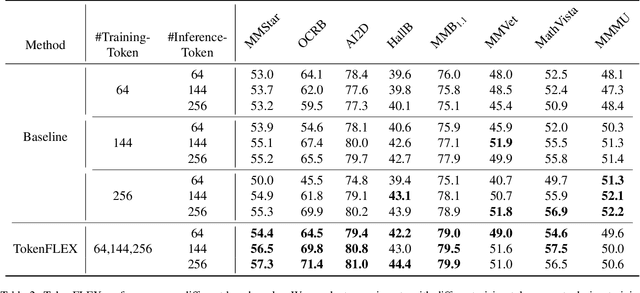
Conventional Vision-Language Models(VLMs) typically utilize a fixed number of vision tokens, regardless of task complexity. This one-size-fits-all strategy introduces notable inefficiencies: using excessive tokens leads to unnecessary computational overhead in simpler tasks, whereas insufficient tokens compromise fine-grained visual comprehension in more complex contexts. To overcome these limitations, we present TokenFLEX, an innovative and adaptable vision-language framework that encodes images into a variable number of tokens for efficient integration with a Large Language Model (LLM). Our approach is underpinned by two pivotal innovations. Firstly, we present a novel training paradigm that enhances performance across varying numbers of vision tokens by stochastically modulating token counts during training. Secondly, we design a lightweight vision token projector incorporating an adaptive pooling layer and SwiGLU, allowing for flexible downsampling of vision tokens and adaptive selection of features tailored to specific token counts. Comprehensive experiments reveal that TokenFLEX consistently outperforms its fixed-token counterparts, achieving notable performance gains across various token counts enhancements of 1.6%, 1.0%, and 0.4% with 64, 144, and 256 tokens, respectively averaged over eight vision-language benchmarks. These results underscore TokenFLEX's remarkable flexibility while maintaining high-performance vision-language understanding.
Finetuning Generative Trajectory Model with Reinforcement Learning from Human Feedback
Mar 13, 2025


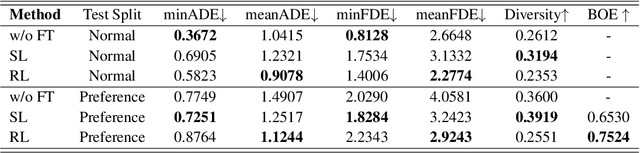
Generating human-like and adaptive trajectories is essential for autonomous driving in dynamic environments. While generative models have shown promise in synthesizing feasible trajectories, they often fail to capture the nuanced variability of human driving styles due to dataset biases and distributional shifts. To address this, we introduce TrajHF, a human feedback-driven finetuning framework for generative trajectory models, designed to align motion planning with diverse driving preferences. TrajHF incorporates multi-conditional denoiser and reinforcement learning with human feedback to refine multi-modal trajectory generation beyond conventional imitation learning. This enables better alignment with human driving preferences while maintaining safety and feasibility constraints. TrajHF achieves PDMS of 93.95 on NavSim benchmark, significantly exceeding other methods. TrajHF sets a new paradigm for personalized and adaptable trajectory generation in autonomous driving.
Preliminary Investigation into Data Scaling Laws for Imitation Learning-Based End-to-End Autonomous Driving
Dec 03, 2024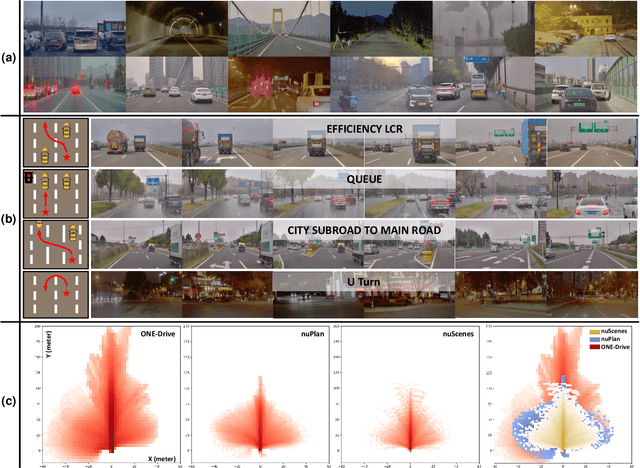
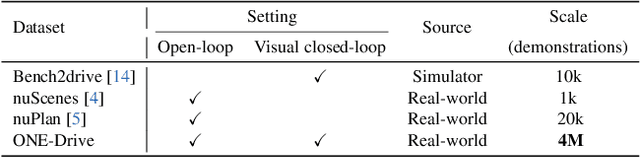

The end-to-end autonomous driving paradigm has recently attracted lots of attention due to its scalability. However, existing methods are constrained by the limited scale of real-world data, which hinders a comprehensive exploration of the scaling laws associated with end-to-end autonomous driving. To address this issue, we collected substantial data from various driving scenarios and behaviors and conducted an extensive study on the scaling laws of existing imitation learning-based end-to-end autonomous driving paradigms. Specifically, approximately 4 million demonstrations from 23 different scenario types were gathered, amounting to over 30,000 hours of driving demonstrations. We performed open-loop evaluations and closed-loop simulation evaluations in 1,400 diverse driving demonstrations (1,300 for open-loop and 100 for closed-loop) under stringent assessment conditions. Through experimental analysis, we discovered that (1) the performance of the driving model exhibits a power-law relationship with the amount of training data; (2) a small increase in the quantity of long-tailed data can significantly improve the performance for the corresponding scenarios; (3) appropriate scaling of data enables the model to achieve combinatorial generalization in novel scenes and actions. Our results highlight the critical role of data scaling in improving the generalizability of models across diverse autonomous driving scenarios, assuring safe deployment in the real world. Project repository: https://github.com/ucaszyp/Driving-Scaling-Law