 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing is Believing: Robust Vision-Guided Cross-Modal Prompt Learning under Label Noise
Apr 10, 2026Prompt learning is a parameter-efficient approach for vision-language models, yet its robustness under label noise is less investigated. Visual content contains richer and more reliable semantic information, which remains more robust under label noise. However, the prompt itself is highly susceptible to label noise. Motivated by this intuition, we propose VisPrompt, a lightweight and robust vision-guided prompt learning framework for noisy-label settings. Specifically, we exploit a cross-modal attention mechanism to reversely inject visual semantics into prompt representations. This enables the prompt tokens to selectively aggregate visual information relevant to the current sample, thereby improving robustness by anchoring prompt learning to stable instance-level visual evidence and reducing the influence of noisy supervision. To address the instability caused by using the same way of injecting visual information for all samples, despite differences in the quality of their visual cues, we further introduce a lightweight conditional modulation mechanism to adaptively control the strength of visual information injection, which strikes a more robust balance between text-side semantic priors and image-side instance evidence. The proposed framework effectively suppresses the noise-induced disturbances, reduce instability in prompt updates, and alleviate memorization of mislabeled samples. VisPrompt significantly improves robustness while keeping the pretrained VLM backbone frozen and introducing only a small amount of additional trainable parameters. Extensive experiments under synthetic and real-world label noise demonstrate that VisPrompt generally outperforms existing baselines on seven benchmark datasets and achieves stronger robustness. Our code is publicly available at https://github.com/gezbww/Vis_Prompt.
FedRG: Unleashing the Representation Geometry for Federated Learning with Noisy Clients
Mar 20, 2026Federated learning (FL) suffers from performance degradation due to the inevitable presence of noisy annotations in distributed scenarios. Existing approaches have advanced in distinguishing noisy samples from the dataset for label correction by leveraging loss values. However, noisy samples recognition relying on scalar loss lacks reliability for FL under heterogeneous scenarios. In this paper, we rethink this paradigm from a representation perspective and propose \method~(\textbf{Fed}erated under \textbf{R}epresentation \textbf{G}emometry), which follows \textbf{the principle of ``representation geometry priority''} to recognize noisy labels. Firstly, \method~creates label-agnostic spherical representations by using self-supervision. It then iteratively fits a spherical von Mises-Fisher (vMF) mixture model to this geometry using previously identified clean samples to capture semantic clusters. This geometric evidence is integrated with a semantic-label soft mapping mechanism to derive a distribution divergence between the label-free and annotated label-conditioned feature space, which robustly identifies noisy samples and updates the vMF mixture model with the newly separated clean dataset. Lastly, we employ an additional personalized noise absorption matrix on noisy labels to achieve robust optimization. Extensive experimental results demonstrate that \method~significantly outperforms state-of-the-art methods for FL with data heterogeneity under diverse noisy clients scenarios.
The Better You Learn, The Smarter You Prune: Towards Efficient Vision-language-action Models via Differentiable Token Pruning
Sep 16, 2025We present LightVLA, a simple yet effective differentiable token pruning framework for vision-language-action (VLA) models. While VLA models have shown impressive capability in executing real-world robotic tasks, their deployment on resource-constrained platforms is often bottlenecked by the heavy attention-based computation over large sets of visual tokens. LightVLA addresses this challenge through adaptive, performance-driven pruning of visual tokens: It generates dynamic queries to evaluate visual token importance, and adopts Gumbel softmax to enable differentiable token selection. Through fine-tuning, LightVLA learns to preserve the most informative visual tokens while pruning tokens which do not contribute to task execution, thereby improving efficiency and performance simultaneously. Notably, LightVLA requires no heuristic magic numbers and introduces no additional trainable parameters, making it compatible with modern inference frameworks. Experimental results demonstrate that LightVLA outperforms different VLA models and existing token pruning methods across diverse tasks on the LIBERO benchmark, achieving higher success rates with substantially reduced computational overhead. Specifically, LightVLA reduces FLOPs and latency by 59.1% and 38.2% respectively, with a 2.9% improvement in task success rate. Meanwhile, we also investigate the learnable query-based token pruning method LightVLA* with additional trainable parameters, which also achieves satisfactory performance. Our work reveals that as VLA pursues optimal performance, LightVLA spontaneously learns to prune tokens from a performance-driven perspective. To the best of our knowledge, LightVLA is the first work to apply adaptive visual token pruning to VLA tasks with the collateral goals of efficiency and performance, marking a significant step toward more efficient, powerful and practical real-time robotic systems.
TransDiffuser: End-to-end Trajectory Generation with Decorrelated Multi-modal Representation for Autonomous Driving
May 14, 2025In recent years, diffusion model has shown its potential across diverse domains from vision generation to language modeling. Transferring its capabilities to modern autonomous driving systems has also emerged as a promising direction.In this work, we propose TransDiffuser, an encoder-decoder based generative trajectory planning model for end-to-end autonomous driving. The encoded scene information serves as the multi-modal conditional input of the denoising decoder. To tackle the mode collapse dilemma in generating high-quality diverse trajectories, we introduce a simple yet effective multi-modal representation decorrelation optimization mechanism during the training process.TransDiffuser achieves PDMS of 94.85 on the NAVSIM benchmark, surpassing previous state-of-the-art methods without any anchor-based prior trajectories.
FNBench: Benchmarking Robust Federated Learning against Noisy Labels
May 10, 2025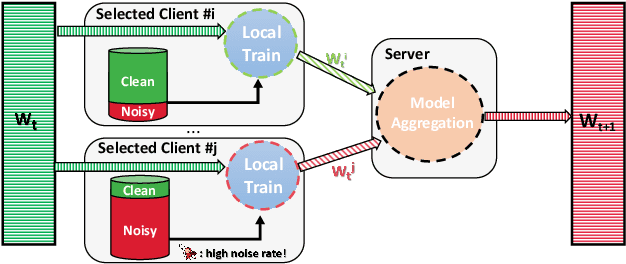
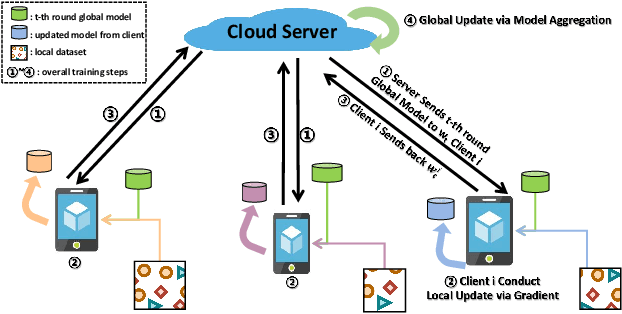
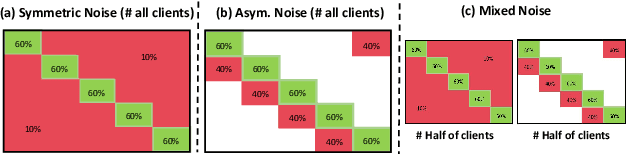
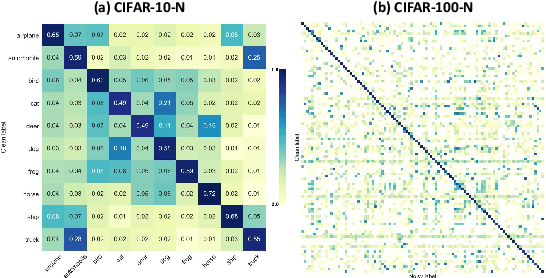
Robustness to label noise within data is a significant challenge in federated learning (FL). From the data-centric perspective, the data quality of distributed datasets can not be guaranteed since annotations of different clients contain complicated label noise of varying degrees, which causes the performance degradation. There have been some early attempts to tackle noisy labels in FL. However, there exists a lack of benchmark studies on comprehensively evaluating their practical performance under unified settings. To this end, we propose the first benchmark study FNBench to provide an experimental investigation which considers three diverse label noise patterns covering synthetic label noise, imperfect human-annotation errors and systematic errors. Our evaluation incorporates eighteen state-of-the-art methods over five image recognition datasets and one text classification dataset. Meanwhile, we provide observations to understand why noisy labels impair FL, and additionally exploit a representation-aware regularization method to enhance the robustness of existing methods against noisy labels based on our observations. Finally, we discuss the limitations of this work and propose three-fold future directions. To facilitate related communities, our source code is open-sourced at https://github.com/Sprinter1999/FNBench.
Investigating Large Language Models for Code Vulnerability Detection: An Experimental Study
Dec 24, 2024



Code vulnerability detection (CVD) is essential for addressing and preventing system security issues, playing a crucial role in ensuring software security. Previous learning-based vulnerability detection methods rely on either fine-tuning medium-size sequence models or training smaller neural networks from scratch. Recent advancements in large pre-trained language models (LLMs) have showcased remarkable capabilities in various code intelligence tasks including code understanding and generation. However, the effectiveness of LLMs in detecting code vulnerabilities is largely under-explored. This work aims to investigate the gap by fine-tuning LLMs for the CVD task, involving four widely-used open-source LLMs. We also implement other five previous graph-based or medium-size sequence models for comparison. Experiments are conducted on five commonly-used CVD datasets, including both the part of short samples and long samples. In addition, we conduct quantitative experiments to investigate the class imbalance issue and the model's performance on samples of different lengths, which are rarely studied in previous works. To better facilitate communities, we open-source all codes and resources of this study in https://github.com/SakiRinn/LLM4CVD and https://huggingface.co/datasets/xuefen/VulResource.
FedLF: Adaptive Logit Adjustment and Feature Optimization in Federated Long-Tailed Learning
Sep 18, 2024Federated learning offers a paradigm to the challenge of preserving privacy in distributed machine learning. However, datasets distributed across each client in the real world are inevitably heterogeneous, and if the datasets can be globally aggregated, they tend to be long-tailed distributed, which greatly affects the performance of the model. The traditional approach to federated learning primarily addresses the heterogeneity of data among clients, yet it fails to address the phenomenon of class-wise bias in global long-tailed data. This results in the trained model focusing on the head classes while neglecting the equally important tail classes. Consequently, it is essential to develop a methodology that considers classes holistically. To address the above problems, we propose a new method FedLF, which introduces three modifications in the local training phase: adaptive logit adjustment, continuous class centred optimization, and feature decorrelation. We compare seven state-of-the-art methods with varying degrees of data heterogeneity and long-tailed distribution. Extensive experiments on benchmark datasets CIFAR-10-LT and CIFAR-100-LT demonstrate that our approach effectively mitigates the problem of model performance degradation due to data heterogeneity and long-tailed distribution. our code is available at https://github.com/18sym/FedLF.
Tackling Noisy Clients in Federated Learning with End-to-end Label Correction
Aug 08, 2024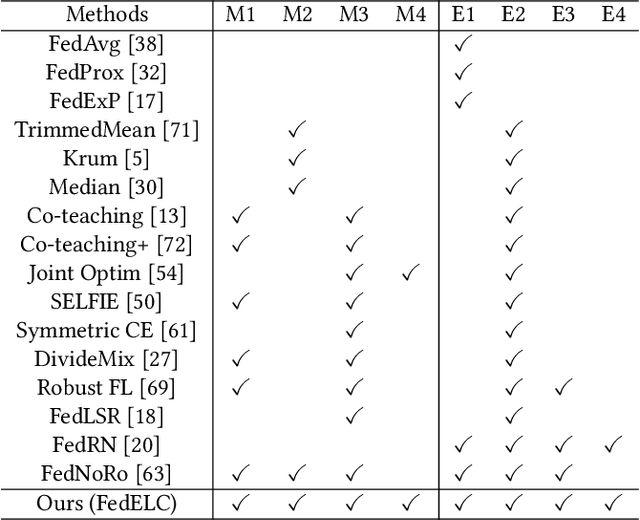
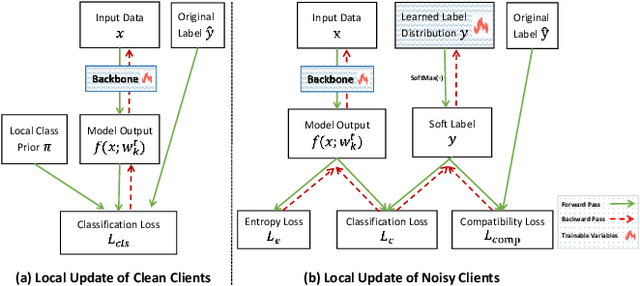

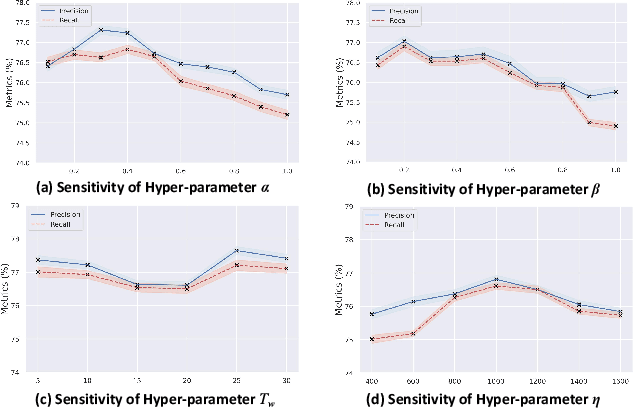
Recently, federated learning (FL) has achieved wide successes for diverse privacy-sensitive applications without sacrificing the sensitive private information of clients. However, the data quality of client datasets can not be guaranteed since corresponding annotations of different clients often contain complex label noise of varying degrees, which inevitably causes the performance degradation. Intuitively, the performance degradation is dominated by clients with higher noise rates since their trained models contain more misinformation from data, thus it is necessary to devise an effective optimization scheme to mitigate the negative impacts of these noisy clients. In this work, we propose a two-stage framework FedELC to tackle this complicated label noise issue. The first stage aims to guide the detection of noisy clients with higher label noise, while the second stage aims to correct the labels of noisy clients' data via an end-to-end label correction framework which is achieved by learning possible ground-truth labels of noisy clients' datasets via back propagation. We implement sixteen related methods and evaluate five datasets with three types of complicated label noise scenarios for a comprehensive comparison. Extensive experimental results demonstrate our proposed framework achieves superior performance than its counterparts for different scenarios. Additionally, we effectively improve the data quality of detected noisy clients' local datasets with our label correction framework. The code is available at https://github.com/Sprinter1999/FedELC.
VIPS-Odom: Visual-Inertial Odometry Tightly-coupled with Parking Slots for Autonomous Parking
Jul 06, 2024Precise localization is of great importance for autonomous parking task since it provides service for the downstream planning and control modules, which significantly affects the system performance. For parking scenarios, dynamic lighting, sparse textures, and the instability of global positioning system (GPS) signals pose challenges for most traditional localization methods. To address these difficulties, we propose VIPS-Odom, a novel semantic visual-inertial odometry framework for underground autonomous parking, which adopts tightly-coupled optimization to fuse measurements from multi-modal sensors and solves odometry. Our VIPS-Odom integrates parking slots detected from the synthesized bird-eye-view (BEV) image with traditional feature points in the frontend, and conducts tightly-coupled optimization with joint constraints introduced by measurements from the inertial measurement unit, wheel speed sensor and parking slots in the backend. We develop a multi-object tracking framework to robustly track parking slots' states. To prove the superiority of our method, we equip an electronic vehicle with related sensors and build an experimental platform based on ROS2 system. Extensive experiments demonstrate the efficacy and advantages of our method compared with other baselines for parking scenarios.
Federated Class-Incremental Learning with New-Class Augmented Self-Distillation
Jan 09, 2024



Federated Learning (FL) enables collaborative model training among participants while guaranteeing the privacy of raw data. Mainstream FL methodologies overlook the dynamic nature of real-world data, particularly its tendency to grow in volume and diversify in classes over time. This oversight results in FL methods suffering from catastrophic forgetting, where the trained models inadvertently discard previously learned information upon assimilating new data. In response to this challenge, we propose a novel Federated Class-Incremental Learning (FCIL) method, named \underline{Fed}erated \underline{C}lass-Incremental \underline{L}earning with New-Class \underline{A}ugmented \underline{S}elf-Di\underline{S}tillation (FedCLASS). The core of FedCLASS is to enrich the class scores of historical models with new class scores predicted by current models and utilize the combined knowledge for self-distillation, enabling a more sufficient and precise knowledge transfer from historical models to current models. Theoretical analyses demonstrate that FedCLASS stands on reliable foundations, considering scores of old classes predicted by historical models as conditional probabilities in the absence of new classes, and the scores of new classes predicted by current models as the conditional probabilities of class scores derived from historical models. Empirical experiments demonstrate the superiority of FedCLASS over four baseline algorithms in reducing average forgetting rate and boosting global accuracy.