 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultibeam Phased Arrays with Spherical Gold Spatio-temporal Coding for Fading-Resilient and Delay Robust Beam Isolations
Mar 20, 2026Future integrated sensing and communication (ISAC) systems require simultaneous multibeam operation with low-latency hardware and robust isolation under synchronization error and fading. Conventional code-division multiplexing using Walsh-Hadamard codes is extremely time-sensitive. This paper demonstrates that conventional temporal-only coded multibeam arrays suffer from inter-beam sidelobe level (SLL) collapse to within a few dB of the main lobe, with variations exceeding 10-20 dB over delay. By embedding moderate-length Gold sequences into a spherical spatial codebook, the proposed Spherical-Gold scheme leverages both temporal and spatial correlation bounds, achieving effective inter-beam isolation without increasing RF complexity. Measurement results and verifications are performed using an Analog Devices ADAR3002 Ka-band 256-element receiver with four simultaneous beams. The proposed scheme demonstrates at least 15 dB rejection with less than 2.5 dB variation in SLL under time error and fading, whereas temporal-only CDMA degrades to approximately -5 to -7 dB SLL with nearly 8 dB variation under time delay.
Benchmarking Real-World Medical Image Classification with Noisy Labels: Challenges, Practice, and Outlook
Dec 10, 2025Learning from noisy labels remains a major challenge in medical image analysis, where annotation demands expert knowledge and substantial inter-observer variability often leads to inconsistent or erroneous labels. Despite extensive research on learning with noisy labels (LNL), the robustness of existing methods in medical imaging has not been systematically assessed. To address this gap, we introduce LNMBench, a comprehensive benchmark for Label Noise in Medical imaging. LNMBench encompasses \textbf{10} representative methods evaluated across 7 datasets, 6 imaging modalities, and 3 noise patterns, establishing a unified and reproducible framework for robustness evaluation under realistic conditions. Comprehensive experiments reveal that the performance of existing LNL methods degrades substantially under high and real-world noise, highlighting the persistent challenges of class imbalance and domain variability in medical data. Motivated by these findings, we further propose a simple yet effective improvement to enhance model robustness under such conditions. The LNMBench codebase is publicly released to facilitate standardized evaluation, promote reproducible research, and provide practical insights for developing noise-resilient algorithms in both research and real-world medical applications.The codebase is publicly available on https://github.com/myyy777/LNMBench.
The Better You Learn, The Smarter You Prune: Towards Efficient Vision-language-action Models via Differentiable Token Pruning
Sep 16, 2025We present LightVLA, a simple yet effective differentiable token pruning framework for vision-language-action (VLA) models. While VLA models have shown impressive capability in executing real-world robotic tasks, their deployment on resource-constrained platforms is often bottlenecked by the heavy attention-based computation over large sets of visual tokens. LightVLA addresses this challenge through adaptive, performance-driven pruning of visual tokens: It generates dynamic queries to evaluate visual token importance, and adopts Gumbel softmax to enable differentiable token selection. Through fine-tuning, LightVLA learns to preserve the most informative visual tokens while pruning tokens which do not contribute to task execution, thereby improving efficiency and performance simultaneously. Notably, LightVLA requires no heuristic magic numbers and introduces no additional trainable parameters, making it compatible with modern inference frameworks. Experimental results demonstrate that LightVLA outperforms different VLA models and existing token pruning methods across diverse tasks on the LIBERO benchmark, achieving higher success rates with substantially reduced computational overhead. Specifically, LightVLA reduces FLOPs and latency by 59.1% and 38.2% respectively, with a 2.9% improvement in task success rate. Meanwhile, we also investigate the learnable query-based token pruning method LightVLA* with additional trainable parameters, which also achieves satisfactory performance. Our work reveals that as VLA pursues optimal performance, LightVLA spontaneously learns to prune tokens from a performance-driven perspective. To the best of our knowledge, LightVLA is the first work to apply adaptive visual token pruning to VLA tasks with the collateral goals of efficiency and performance, marking a significant step toward more efficient, powerful and practical real-time robotic systems.
TransDiffuser: End-to-end Trajectory Generation with Decorrelated Multi-modal Representation for Autonomous Driving
May 14, 2025In recent years, diffusion model has shown its potential across diverse domains from vision generation to language modeling. Transferring its capabilities to modern autonomous driving systems has also emerged as a promising direction.In this work, we propose TransDiffuser, an encoder-decoder based generative trajectory planning model for end-to-end autonomous driving. The encoded scene information serves as the multi-modal conditional input of the denoising decoder. To tackle the mode collapse dilemma in generating high-quality diverse trajectories, we introduce a simple yet effective multi-modal representation decorrelation optimization mechanism during the training process.TransDiffuser achieves PDMS of 94.85 on the NAVSIM benchmark, surpassing previous state-of-the-art methods without any anchor-based prior trajectories.
Implementing Trust in Non-Small Cell Lung Cancer Diagnosis with a Conformalized Uncertainty-Aware AI Framework in Whole-Slide Images
Dec 28, 2024Ensuring trustworthiness is fundamental to the development of artificial intelligence (AI) that is considered societally responsible, particularly in cancer diagnostics, where a misdiagnosis can have dire consequences. Current digital pathology AI models lack systematic solutions to address trustworthiness concerns arising from model limitations and data discrepancies between model deployment and development environments. To address this issue, we developed TRUECAM, a framework designed to ensure both data and model trustworthiness in non-small cell lung cancer subtyping with whole-slide images. TRUECAM integrates 1) a spectral-normalized neural Gaussian process for identifying out-of-scope inputs and 2) an ambiguity-guided elimination of tiles to filter out highly ambiguous regions, addressing data trustworthiness, as well as 3) conformal prediction to ensure controlled error rates. We systematically evaluated the framework across multiple large-scale cancer datasets, leveraging both task-specific and foundation models, illustrate that an AI model wrapped with TRUECAM significantly outperforms models that lack such guidance, in terms of classification accuracy, robustness, interpretability, and data efficiency, while also achieving improvements in fairness. These findings highlight TRUECAM as a versatile wrapper framework for digital pathology AI models with diverse architectural designs, promoting their responsible and effective applications in real-world settings.
A Backdoor Attack Scheme with Invisible Triggers Based on Model Architecture Modification
Dec 22, 2024Machine learning systems are vulnerable to backdoor attacks, where attackers manipulate model behavior through data tampering or architectural modifications. Traditional backdoor attacks involve injecting malicious samples with specific triggers into the training data, causing the model to produce targeted incorrect outputs in the presence of the corresponding triggers. More sophisticated attacks modify the model's architecture directly, embedding backdoors that are harder to detect as they evade traditional data-based detection methods. However, the drawback of the architectural modification based backdoor attacks is that the trigger must be visible in order to activate the backdoor. To further strengthen the invisibility of the backdoor attacks, a novel backdoor attack method is presented in the paper. To be more specific, this method embeds the backdoor within the model's architecture and has the capability to generate inconspicuous and stealthy triggers. The attack is implemented by modifying pre-trained models, which are then redistributed, thereby posing a potential threat to unsuspecting users. Comprehensive experiments conducted on standard computer vision benchmarks validate the effectiveness of this attack and highlight the stealthiness of its triggers, which remain undetectable through both manual visual inspection and advanced detection tools.
Deep learning and random light structuring ensure robust free-space communications
Jan 18, 2024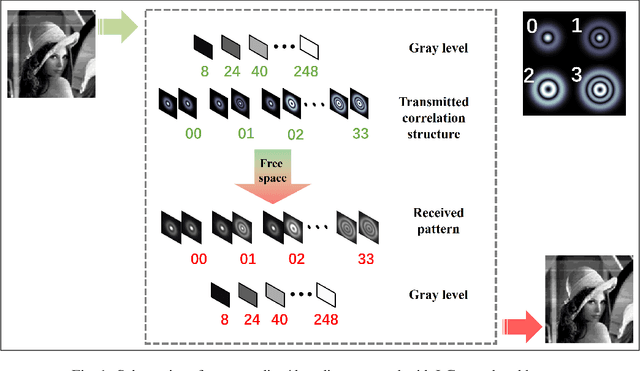
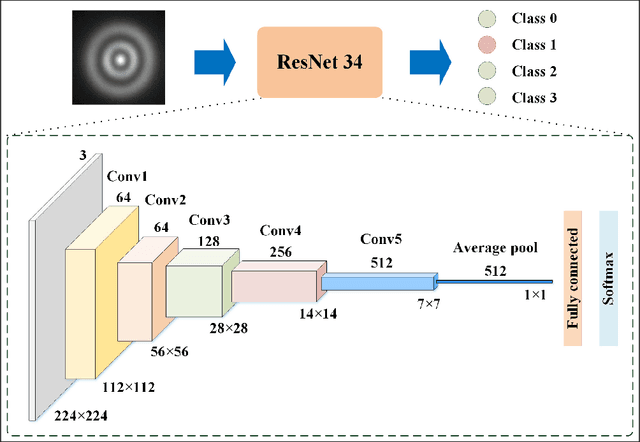
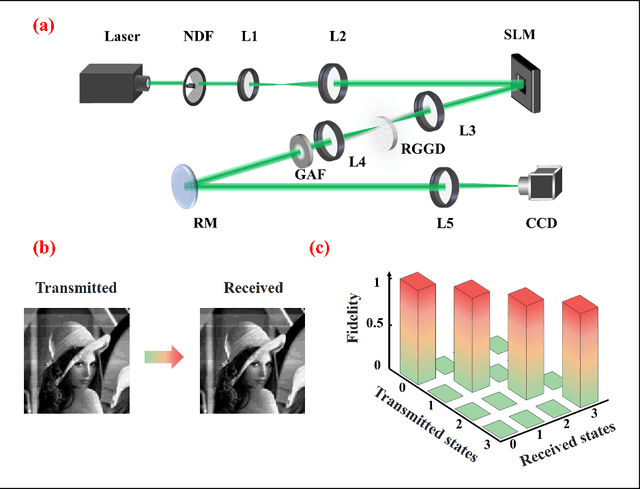

Having shown early promise, free-space optical communications (FSO) face formidable challenges in the age of information explosion. The ever-growing demand for greater channel communication capacity is one of the challenges. The inter-channel crosstalk, which severely degrades the quality of transmitted information, creates another roadblock in the way of efficient FSO implementation. Here we advance theoretically and realize experimentally a potentially high-capacity FSO protocol that enables high-fidelity transfer of an image, or set of images through a complex environment. In our protocol, we complement random light structuring at the transmitter with a deep learning image classification platform at the receiver. Multiplexing novel, independent, mutually orthogonal degrees of freedom available to structured random light can potentially significantly boost the channel communication capacity of our protocol without introducing any deleterious crosstalk. Specifically, we show how one can multiplex the degrees of freedom associated with the source coherence radius and a spatial position of a beamlet within an array of structured random beams to greatly enhance the capacity of our communication link. The superb resilience of structured random light to environmental noise, as well as extreme efficiency of deep learning networks at classifying images guarantees high-fidelity image transfer within the framework of our protocol.
Self-supervised Learning for Electroencephalogram: A Systematic Survey
Jan 09, 2024



Electroencephalogram (EEG) is a non-invasive technique to record bioelectrical signals. Integrating supervised deep learning techniques with EEG signals has recently facilitated automatic analysis across diverse EEG-based tasks. However, the label issues of EEG signals have constrained the development of EEG-based deep models. Obtaining EEG annotations is difficult that requires domain experts to guide collection and labeling, and the variability of EEG signals among different subjects causes significant label shifts. To solve the above challenges, self-supervised learning (SSL) has been proposed to extract representations from unlabeled samples through well-designed pretext tasks. This paper concentrates on integrating SSL frameworks with temporal EEG signals to achieve efficient representation and proposes a systematic review of the SSL for EEG signals. In this paper, 1) we introduce the concept and theory of self-supervised learning and typical SSL frameworks. 2) We provide a comprehensive review of SSL for EEG analysis, including taxonomy, methodology, and technique details of the existing EEG-based SSL frameworks, and discuss the difference between these methods. 3) We investigate the adaptation of the SSL approach to various downstream tasks, including the task description and related benchmark datasets. 4) Finally, we discuss the potential directions for future SSL-EEG research.
Infrared Small Target Detection Using Double-Weighted Multi-Granularity Patch Tensor Model With Tensor-Train Decomposition
Oct 09, 2023Infrared small target detection plays an important role in the remote sensing fields. Therefore, many detection algorithms have been proposed, in which the infrared patch-tensor (IPT) model has become a mainstream tool due to its excellent performance. However, most IPT-based methods face great challenges, such as inaccurate measure of the tensor low-rankness and poor robustness to complex scenes, which will leadto poor detection performance. In order to solve these problems, this paper proposes a novel double-weighted multi-granularity infrared patch tensor (DWMGIPT) model. First, to capture different granularity information of tensor from multiple modes, a multi-granularity infrared patch tensor (MGIPT) model is constructed by collecting nonoverlapping patches and tensor augmentation based on the tensor train (TT) decomposition. Second, to explore the latent structure of tensor more efficiently, we utilize the auto-weighted mechanism to balance the importance of information at different granularity. Then, the steering kernel (SK) is employed to extract local structure prior, which suppresses background interference such as strong edges and noise. Finally, an efficient optimization algorithm based on the alternating direction method of multipliers (ADMM) is presented to solve the model. Extensive experiments in various challenging scenes show that the proposed algorithm is robust to noise and different scenes. Compared with the other eight state-of-the-art methods, different evaluation metrics demonstrate that our method achieves better detection performance in various complex scenes.
Image Super-Resolution via Residual Blended Attention Generative Adversarial Network with Dual Discriminators
Nov 13, 2019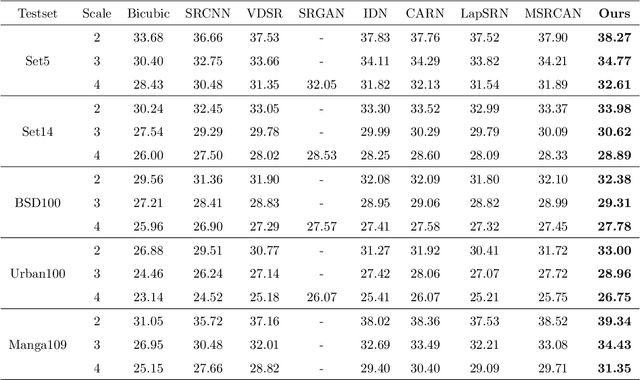
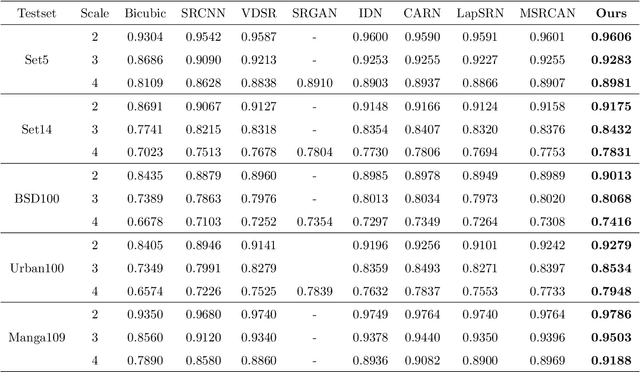
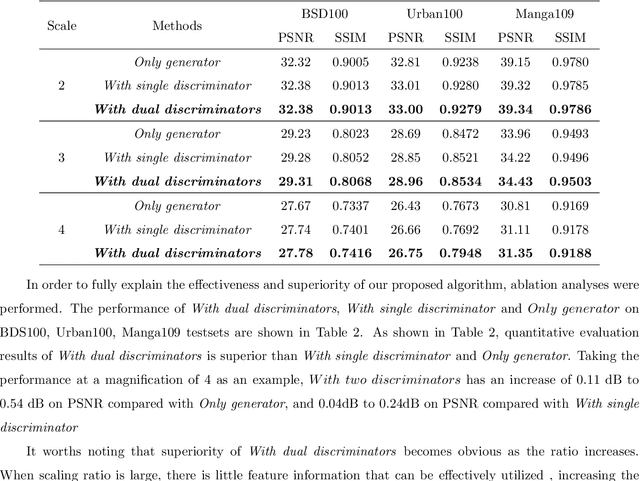
When reviewing codes, it seems that there's something wrong with the training codes that we did not notice, this article is temporarily withdrawn and will be modified and resubmitted after codes reviewing.