 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingLanMiDian: Systematic Evaluation of LLMs on TCM Knowledge and Clinical Reasoning
Feb 02, 2026Large language models (LLMs) are advancing rapidly in medical NLP, yet Traditional Chinese Medicine (TCM) with its distinctive ontology, terminology, and reasoning patterns requires domain-faithful evaluation. Existing TCM benchmarks are fragmented in coverage and scale and rely on non-unified or generation-heavy scoring that hinders fair comparison. We present the LingLanMiDian (LingLan) benchmark, a large-scale, expert-curated, multi-task suite that unifies evaluation across knowledge recall, multi-hop reasoning, information extraction, and real-world clinical decision-making. LingLan introduces a consistent metric design, a synonym-tolerant protocol for clinical labels, a per-dataset 400-item Hard subset, and a reframing of diagnosis and treatment recommendation into single-choice decision recognition. We conduct comprehensive, zero-shot evaluations on 14 leading open-source and proprietary LLMs, providing a unified perspective on their strengths and limitations in TCM commonsense knowledge understanding, reasoning, and clinical decision support; critically, the evaluation on Hard subset reveals a substantial gap between current models and human experts in TCM-specialized reasoning. By bridging fundamental knowledge and applied reasoning through standardized evaluation, LingLan establishes a unified, quantitative, and extensible foundation for advancing TCM LLMs and domain-specific medical AI research. All evaluation data and code are available at https://github.com/TCMAI-BJTU/LingLan and http://tcmnlp.com.
Auto-Augmentation Contrastive Learning for Wearable-based Human Activity Recognition
Jan 30, 2026For low-semantic sensor signals from human activity recognition (HAR), contrastive learning (CL) is essential to implement novel applications or generic models without manual annotation, which is a high-performance self-supervised learning (SSL) method. However, CL relies heavily on data augmentation for pairwise comparisons. Especially for low semantic data in the HAR area, conducting good performance augmentation strategies in pretext tasks still rely on manual attempts lacking generalizability and flexibility. To reduce the augmentation burden, we propose an end-to-end auto-augmentation contrastive learning (AutoCL) method for wearable-based HAR. AutoCL is based on a Siamese network architecture that shares the parameters of the backbone and with a generator embedded to learn auto-augmentation. AutoCL trains the generator based on the representation in the latent space to overcome the disturbances caused by noise and redundant information in raw sensor data. The architecture empirical study indicates the effectiveness of this design. Furthermore, we propose a stop-gradient design and correlation reduction strategy in AutoCL to enhance encoder representation learning. Extensive experiments based on four wide-used HAR datasets demonstrate that the proposed AutoCL method significantly improves recognition accuracy compared with other SOTA methods.
Multilingual Grammatical Error Annotation: Combining Language-Agnostic Framework with Language-Specific Flexibility
Jun 09, 2025



Grammatical Error Correction (GEC) relies on accurate error annotation and evaluation, yet existing frameworks, such as $\texttt{errant}$, face limitations when extended to typologically diverse languages. In this paper, we introduce a standardized, modular framework for multilingual grammatical error annotation. Our approach combines a language-agnostic foundation with structured language-specific extensions, enabling both consistency and flexibility across languages. We reimplement $\texttt{errant}$ using $\texttt{stanza}$ to support broader multilingual coverage, and demonstrate the framework's adaptability through applications to English, German, Czech, Korean, and Chinese, ranging from general-purpose annotation to more customized linguistic refinements. This work supports scalable and interpretable GEC annotation across languages and promotes more consistent evaluation in multilingual settings. The complete codebase and annotation tools can be accessed at https://github.com/open-writing-evaluation/jp_errant_bea.
Learning Critically: Selective Self Distillation in Federated Learning on Non-IID Data
Apr 20, 2025Federated learning (FL) enables multiple clients to collaboratively train a global model while keeping local data decentralized. Data heterogeneity (non-IID) across clients has imposed significant challenges to FL, which makes local models re-optimize towards their own local optima and forget the global knowledge, resulting in performance degradation and convergence slowdown. Many existing works have attempted to address the non-IID issue by adding an extra global-model-based regularizing item to the local training but without an adaption scheme, which is not efficient enough to achieve high performance with deep learning models. In this paper, we propose a Selective Self-Distillation method for Federated learning (FedSSD), which imposes adaptive constraints on the local updates by self-distilling the global model's knowledge and selectively weighting it by evaluating the credibility at both the class and sample level. The convergence guarantee of FedSSD is theoretically analyzed and extensive experiments are conducted on three public benchmark datasets, which demonstrates that FedSSD achieves better generalization and robustness in fewer communication rounds, compared with other state-of-the-art FL methods.
A Survey on Unlearnable Data
Apr 01, 2025



Unlearnable data (ULD) has emerged as an innovative defense technique to prevent machine learning models from learning meaningful patterns from specific data, thus protecting data privacy and security. By introducing perturbations to the training data, ULD degrades model performance, making it difficult for unauthorized models to extract useful representations. Despite the growing significance of ULD, existing surveys predominantly focus on related fields, such as adversarial attacks and machine unlearning, with little attention given to ULD as an independent area of study. This survey fills that gap by offering a comprehensive review of ULD, examining unlearnable data generation methods, public benchmarks, evaluation metrics, theoretical foundations and practical applications. We compare and contrast different ULD approaches, analyzing their strengths, limitations, and trade-offs related to unlearnability, imperceptibility, efficiency and robustness. Moreover, we discuss key challenges, such as balancing perturbation imperceptibility with model degradation and the computational complexity of ULD generation. Finally, we highlight promising future research directions to advance the effectiveness and applicability of ULD, underscoring its potential to become a crucial tool in the evolving landscape of data protection in machine learning.
Chinese Grammatical Error Correction: A Survey
Apr 01, 2025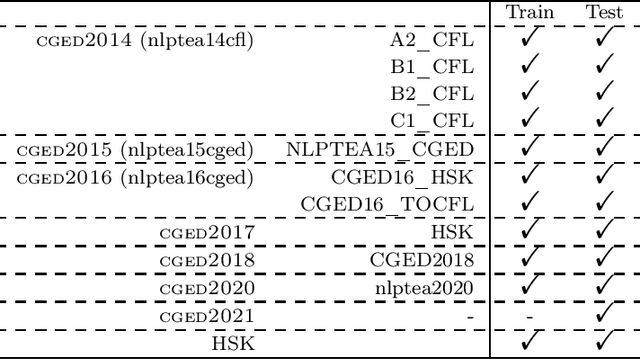



Chinese Grammatical Error Correction (CGEC) is a critical task in Natural Language Processing, addressing the growing demand for automated writing assistance in both second-language (L2) and native (L1) Chinese writing. While L2 learners struggle with mastering complex grammatical structures, L1 users also benefit from CGEC in academic, professional, and formal contexts where writing precision is essential. This survey provides a comprehensive review of CGEC research, covering datasets, annotation schemes, evaluation methodologies, and system advancements. We examine widely used CGEC datasets, highlighting their characteristics, limitations, and the need for improved standardization. We also analyze error annotation frameworks, discussing challenges such as word segmentation ambiguity and the classification of Chinese-specific error types. Furthermore, we review evaluation metrics, focusing on their adaptation from English GEC to Chinese, including character-level scoring and the use of multiple references. In terms of system development, we trace the evolution from rule-based and statistical approaches to neural architectures, including Transformer-based models and the integration of large pre-trained language models. By consolidating existing research and identifying key challenges, this survey provides insights into the current state of CGEC and outlines future directions, including refining annotation standards to address segmentation challenges, and leveraging multilingual approaches to enhance CGEC.
Large Language Models for Constructing and Optimizing Machine Learning Workflows: A Survey
Nov 11, 2024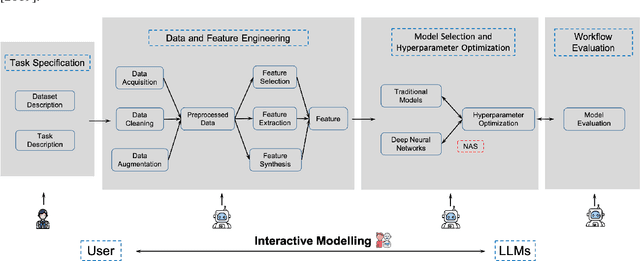
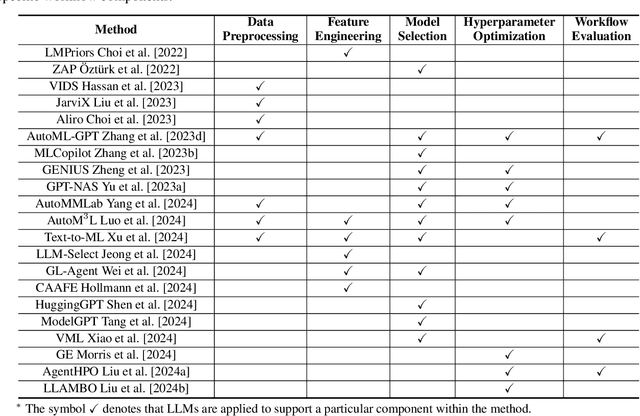

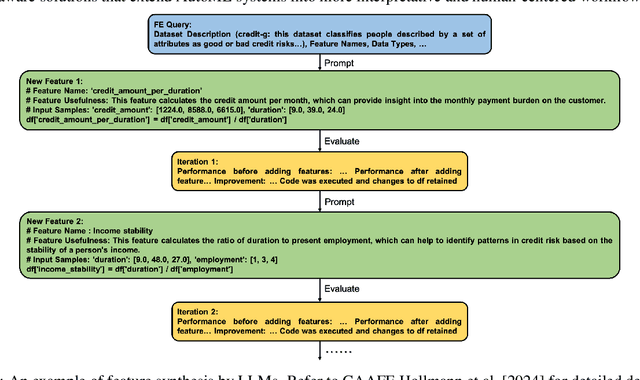
Building effective machine learning (ML) workflows to address complex tasks is a primary focus of the Automatic ML (AutoML) community and a critical step toward achieving artificial general intelligence (AGI). Recently, the integration of Large Language Models (LLMs) into ML workflows has shown great potential for automating and enhancing various stages of the ML pipeline. This survey provides a comprehensive and up-to-date review of recent advancements in using LLMs to construct and optimize ML workflows, focusing on key components encompassing data and feature engineering, model selection and hyperparameter optimization, and workflow evaluation. We discuss both the advantages and limitations of LLM-driven approaches, emphasizing their capacity to streamline and enhance ML workflow modeling process through language understanding, reasoning, interaction, and generation. Finally, we highlight open challenges and propose future research directions to advance the effective application of LLMs in ML workflows.
LLMs for User Interest Exploration: A Hybrid Approach
May 25, 2024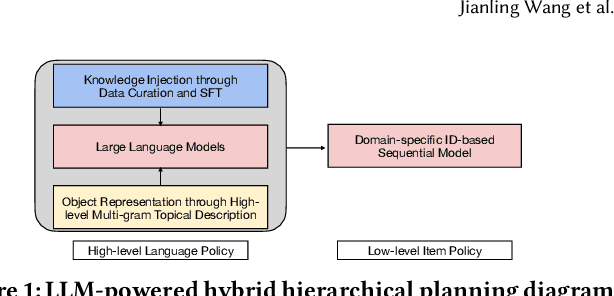

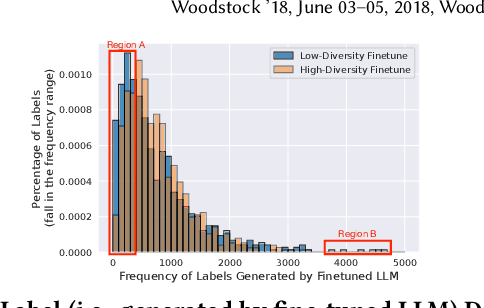
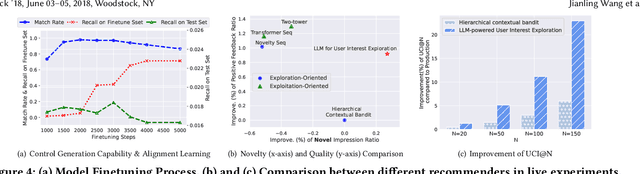
Traditional recommendation systems are subject to a strong feedback loop by learning from and reinforcing past user-item interactions, which in turn limits the discovery of novel user interests. To address this, we introduce a hybrid hierarchical framework combining Large Language Models (LLMs) and classic recommendation models for user interest exploration. The framework controls the interfacing between the LLMs and the classic recommendation models through "interest clusters", the granularity of which can be explicitly determined by algorithm designers. It recommends the next novel interests by first representing "interest clusters" using language, and employs a fine-tuned LLM to generate novel interest descriptions that are strictly within these predefined clusters. At the low level, it grounds these generated interests to an item-level policy by restricting classic recommendation models, in this case a transformer-based sequence recommender to return items that fall within the novel clusters generated at the high level. We showcase the efficacy of this approach on an industrial-scale commercial platform serving billions of users. Live experiments show a significant increase in both exploration of novel interests and overall user enjoyment of the platform.
Self-supervised Learning for Electroencephalogram: A Systematic Survey
Jan 09, 2024



Electroencephalogram (EEG) is a non-invasive technique to record bioelectrical signals. Integrating supervised deep learning techniques with EEG signals has recently facilitated automatic analysis across diverse EEG-based tasks. However, the label issues of EEG signals have constrained the development of EEG-based deep models. Obtaining EEG annotations is difficult that requires domain experts to guide collection and labeling, and the variability of EEG signals among different subjects causes significant label shifts. To solve the above challenges, self-supervised learning (SSL) has been proposed to extract representations from unlabeled samples through well-designed pretext tasks. This paper concentrates on integrating SSL frameworks with temporal EEG signals to achieve efficient representation and proposes a systematic review of the SSL for EEG signals. In this paper, 1) we introduce the concept and theory of self-supervised learning and typical SSL frameworks. 2) We provide a comprehensive review of SSL for EEG analysis, including taxonomy, methodology, and technique details of the existing EEG-based SSL frameworks, and discuss the difference between these methods. 3) We investigate the adaptation of the SSL approach to various downstream tasks, including the task description and related benchmark datasets. 4) Finally, we discuss the potential directions for future SSL-EEG research.
Unsupervised Deep Cross-Language Entity Alignment
Sep 19, 2023Cross-lingual entity alignment is the task of finding the same semantic entities from different language knowledge graphs. In this paper, we propose a simple and novel unsupervised method for cross-language entity alignment. We utilize the deep learning multi-language encoder combined with a machine translator to encode knowledge graph text, which reduces the reliance on label data. Unlike traditional methods that only emphasize global or local alignment, our method simultaneously considers both alignment strategies. We first view the alignment task as a bipartite matching problem and then adopt the re-exchanging idea to accomplish alignment. Compared with the traditional bipartite matching algorithm that only gives one optimal solution, our algorithm generates ranked matching results which enabled many potentials downstream tasks. Additionally, our method can adapt two different types of optimization (minimal and maximal) in the bipartite matching process, which provides more flexibility. Our evaluation shows, we each scored 0.966, 0.990, and 0.996 Hits@1 rates on the DBP15K dataset in Chinese, Japanese, and French to English alignment tasks. We outperformed the state-of-the-art method in unsupervised and semi-supervised categories. Compared with the state-of-the-art supervised method, our method outperforms 2.6% and 0.4% in Ja-En and Fr-En alignment tasks while marginally lower by 0.2% in the Zh-En alignment task.