 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Grammatical Error Annotation: Combining Language-Agnostic Framework with Language-Specific Flexibility
Jun 09, 2025



Grammatical Error Correction (GEC) relies on accurate error annotation and evaluation, yet existing frameworks, such as $\texttt{errant}$, face limitations when extended to typologically diverse languages. In this paper, we introduce a standardized, modular framework for multilingual grammatical error annotation. Our approach combines a language-agnostic foundation with structured language-specific extensions, enabling both consistency and flexibility across languages. We reimplement $\texttt{errant}$ using $\texttt{stanza}$ to support broader multilingual coverage, and demonstrate the framework's adaptability through applications to English, German, Czech, Korean, and Chinese, ranging from general-purpose annotation to more customized linguistic refinements. This work supports scalable and interpretable GEC annotation across languages and promotes more consistent evaluation in multilingual settings. The complete codebase and annotation tools can be accessed at https://github.com/open-writing-evaluation/jp_errant_bea.
Can LLMs Simulate Human Behavioral Variability? A Case Study in the Phonemic Fluency Task
May 22, 2025Large language models (LLMs) are increasingly explored as substitutes for human participants in cognitive tasks, but their ability to simulate human behavioral variability remains unclear. This study examines whether LLMs can approximate individual differences in the phonemic fluency task, where participants generate words beginning with a target letter. We evaluated 34 model configurations, varying prompt specificity, sampling temperature, and model type, and compared outputs to responses from 106 human participants. While some configurations, especially Claude 3.7 Sonnet, matched human averages and lexical preferences, none reproduced the scope of human variability. LLM outputs were consistently less diverse and structurally rigid, and LLM ensembles failed to increase diversity. Network analyses further revealed fundamental differences in retrieval structure between humans and models. These results highlight key limitations in using LLMs to simulate human cognition and behavior.
Chinese Grammatical Error Correction: A Survey
Apr 01, 2025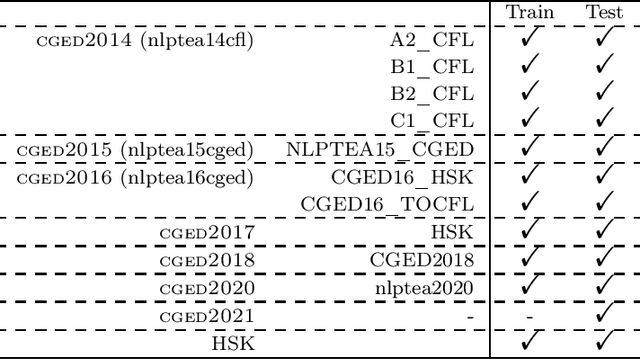



Chinese Grammatical Error Correction (CGEC) is a critical task in Natural Language Processing, addressing the growing demand for automated writing assistance in both second-language (L2) and native (L1) Chinese writing. While L2 learners struggle with mastering complex grammatical structures, L1 users also benefit from CGEC in academic, professional, and formal contexts where writing precision is essential. This survey provides a comprehensive review of CGEC research, covering datasets, annotation schemes, evaluation methodologies, and system advancements. We examine widely used CGEC datasets, highlighting their characteristics, limitations, and the need for improved standardization. We also analyze error annotation frameworks, discussing challenges such as word segmentation ambiguity and the classification of Chinese-specific error types. Furthermore, we review evaluation metrics, focusing on their adaptation from English GEC to Chinese, including character-level scoring and the use of multiple references. In terms of system development, we trace the evolution from rule-based and statistical approaches to neural architectures, including Transformer-based models and the integration of large pre-trained language models. By consolidating existing research and identifying key challenges, this survey provides insights into the current state of CGEC and outlines future directions, including refining annotation standards to address segmentation challenges, and leveraging multilingual approaches to enhance CGEC.
Bias in Large Language Models: Origin, Evaluation, and Mitigation
Nov 16, 2024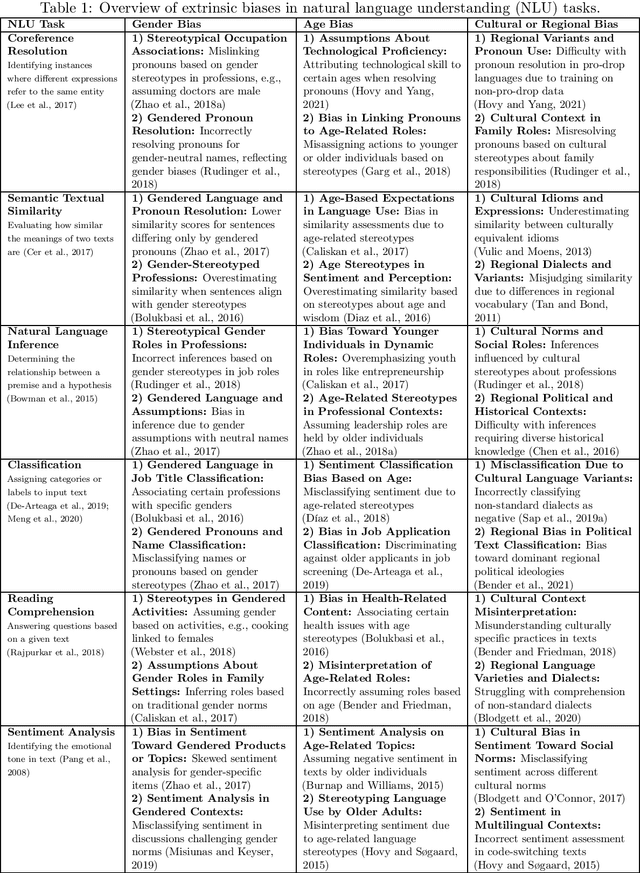
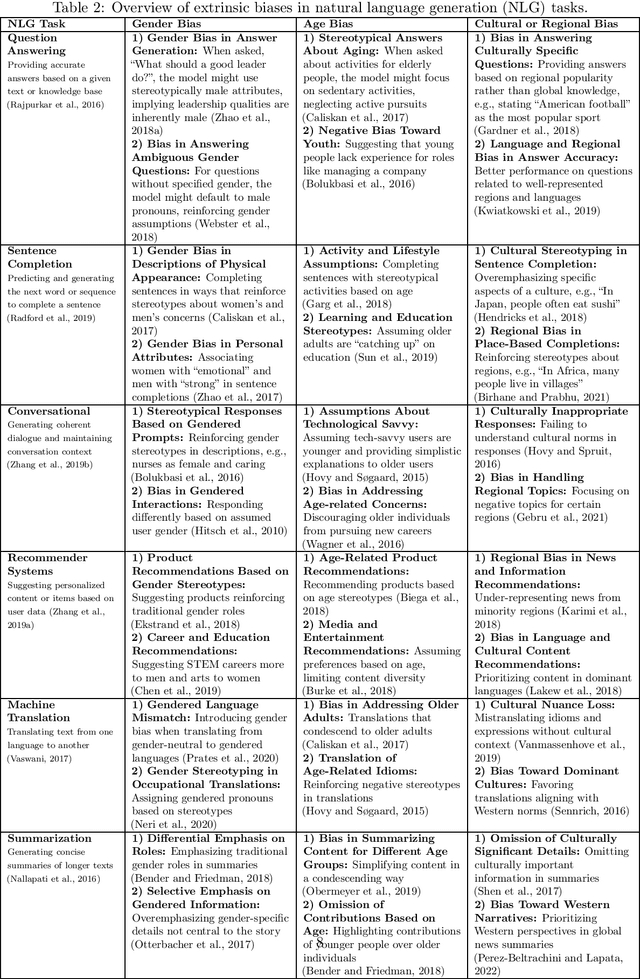
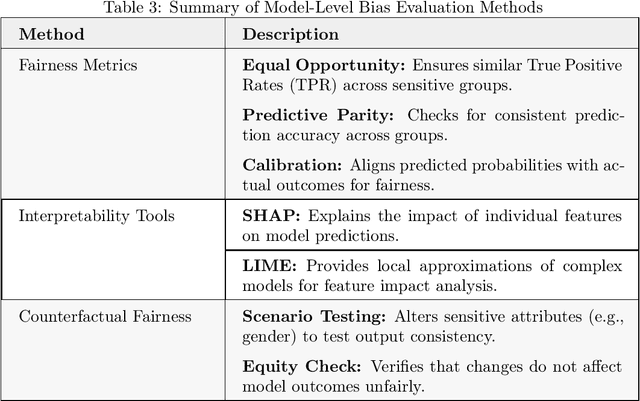

Large Language Models (LLMs) have revolutionized natural language processing, but their susceptibility to biases poses significant challenges. This comprehensive review examines the landscape of bias in LLMs, from its origins to current mitigation strategies. We categorize biases as intrinsic and extrinsic, analyzing their manifestations in various NLP tasks. The review critically assesses a range of bias evaluation methods, including data-level, model-level, and output-level approaches, providing researchers with a robust toolkit for bias detection. We further explore mitigation strategies, categorizing them into pre-model, intra-model, and post-model techniques, highlighting their effectiveness and limitations. Ethical and legal implications of biased LLMs are discussed, emphasizing potential harms in real-world applications such as healthcare and criminal justice. By synthesizing current knowledge on bias in LLMs, this review contributes to the ongoing effort to develop fair and responsible AI systems. Our work serves as a comprehensive resource for researchers and practitioners working towards understanding, evaluating, and mitigating bias in LLMs, fostering the development of more equitable AI technologies.
Neural Automated Writing Evaluation with Corrective Feedback
Feb 27, 2024

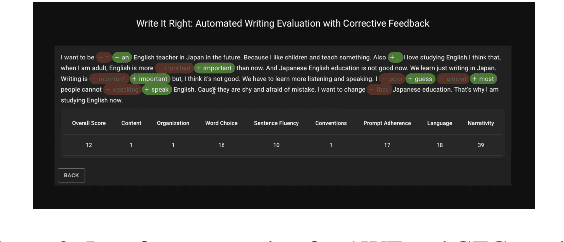

The utilization of technology in second language learning and teaching has become ubiquitous. For the assessment of writing specifically, automated writing evaluation (AWE) and grammatical error correction (GEC) have become immensely popular and effective methods for enhancing writing proficiency and delivering instant and individualized feedback to learners. By leveraging the power of natural language processing (NLP) and machine learning algorithms, AWE and GEC systems have been developed separately to provide language learners with automated corrective feedback and more accurate and unbiased scoring that would otherwise be subject to examiners. In this paper, we propose an integrated system for automated writing evaluation with corrective feedback as a means of bridging the gap between AWE and GEC results for second language learners. This system enables language learners to simulate the essay writing tests: a student writes and submits an essay, and the system returns the assessment of the writing along with suggested grammatical error corrections. Given that automated scoring and grammatical correction are more efficient and cost-effective than human grading, this integrated system would also alleviate the burden of manually correcting innumerable essays.
Frustratingly Simple Prompting-based Text Denoising
Feb 24, 2024This paper introduces a novel perspective on the automated essay scoring (AES) task, challenging the conventional view of the ASAP dataset as a static entity. Employing simple text denoising techniques using prompting, we explore the dynamic potential within the dataset. While acknowledging the previous emphasis on building regression systems, our paper underscores how making minor changes to a dataset through text denoising can enhance the final results.
Evaluating Prompting Strategies for Grammatical Error Correction Based on Language Proficiency
Feb 24, 2024The writing examples of English language learners may be different from those of native speakers. Given that there is a significant differences in second language (L2) learners' error types by their proficiency levels, this paper attempts to reduce overcorrection by examining the interaction between LLM's performance and L2 language proficiency. Our method focuses on zero-shot and few-shot prompting and fine-tuning models for GEC for learners of English as a foreign language based on the different proficiency. We investigate GEC results and find that overcorrection happens primarily in advanced language learners' writing (proficiency C) rather than proficiency A (a beginner level) and proficiency B (an intermediate level). Fine-tuned LLMs, and even few-shot prompting with writing examples of English learners, actually tend to exhibit decreased recall measures. To make our claim concrete, we conduct a comprehensive examination of GEC outcomes and their evaluation results based on language proficiency.