 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTREX: Tokenizer Regression for Optimal Data Mixture
Jan 20, 2026Building effective tokenizers for multilingual Large Language Models (LLMs) requires careful control over language-specific data mixtures. While a tokenizer's compression performance critically affects the efficiency of LLM training and inference, existing approaches rely on heuristics or costly large-scale searches to determine optimal language ratios. We introduce Tokenizer Regression for Optimal Data MiXture (TREX), a regression-based framework that efficiently predicts the optimal data mixture for tokenizer training. TREX trains small-scale proxy tokenizers on random mixtures, gathers their compression statistics, and learns to predict compression performance from data mixtures. This learned model enables scalable mixture search before large-scale tokenizer training, mitigating the accuracy-cost trade-off in multilingual tokenizer design. Tokenizers trained with TReX's predicted mixtures outperform mixtures based on LLaMA3 and uniform distributions by up to 12% in both inand out-of-distribution compression efficiency, demonstrating strong scalability, robustness, and practical effectiveness.
Constituency Structure over Eojeol in Korean Treebanks
Dec 27, 2025The design of Korean constituency treebanks raises a fundamental representational question concerning the choice of terminal units. Although Korean words are morphologically complex, treating morphemes as constituency terminals conflates word internal morphology with phrase level syntactic structure and creates mismatches with eojeol based dependency resources. This paper argues for an eojeol based constituency representation, with morphological segmentation and fine grained part of speech information encoded in a separate, non constituent layer. A comparative analysis shows that, under explicit normalization assumptions, the Sejong and Penn Korean treebanks can be treated as representationally equivalent at the eojeol based constituency level. Building on this result, we outline an eojeol based annotation scheme that preserves interpretable constituency and supports cross treebank comparison and constituency dependency conversion.
Multilingual Grammatical Error Annotation: Combining Language-Agnostic Framework with Language-Specific Flexibility
Jun 09, 2025



Grammatical Error Correction (GEC) relies on accurate error annotation and evaluation, yet existing frameworks, such as $\texttt{errant}$, face limitations when extended to typologically diverse languages. In this paper, we introduce a standardized, modular framework for multilingual grammatical error annotation. Our approach combines a language-agnostic foundation with structured language-specific extensions, enabling both consistency and flexibility across languages. We reimplement $\texttt{errant}$ using $\texttt{stanza}$ to support broader multilingual coverage, and demonstrate the framework's adaptability through applications to English, German, Czech, Korean, and Chinese, ranging from general-purpose annotation to more customized linguistic refinements. This work supports scalable and interpretable GEC annotation across languages and promotes more consistent evaluation in multilingual settings. The complete codebase and annotation tools can be accessed at https://github.com/open-writing-evaluation/jp_errant_bea.
Enriching the Korean Learner Corpus with Multi-reference Annotations and Rubric-Based Scoring
May 01, 2025Despite growing global interest in Korean language education, there remains a significant lack of learner corpora tailored to Korean L2 writing. To address this gap, we enhance the KoLLA Korean learner corpus by adding multiple grammatical error correction (GEC) references, thereby enabling more nuanced and flexible evaluation of GEC systems, and reflects the variability of human language. Additionally, we enrich the corpus with rubric-based scores aligned with guidelines from the Korean National Language Institute, capturing grammatical accuracy, coherence, and lexical diversity. These enhancements make KoLLA a robust and standardized resource for research in Korean L2 education, supporting advancements in language learning, assessment, and automated error correction.
Proposing TAGbank as a Corpus of Tree-Adjoining Grammar Derivations
Apr 07, 2025The development of lexicalized grammars, particularly Tree-Adjoining Grammar (TAG), has significantly advanced our understanding of syntax and semantics in natural language processing (NLP). While existing syntactic resources like the Penn Treebank and Universal Dependencies offer extensive annotations for phrase-structure and dependency parsing, there is a lack of large-scale corpora grounded in lexicalized grammar formalisms. To address this gap, we introduce TAGbank, a corpus of TAG derivations automatically extracted from existing syntactic treebanks. This paper outlines a methodology for mapping phrase-structure annotations to TAG derivations, leveraging the generative power of TAG to support parsing, grammar induction, and semantic analysis. Our approach builds on the work of CCGbank, extending it to incorporate the unique structural properties of TAG, including its transparent derivation trees and its ability to capture long-distance dependencies. We also discuss the challenges involved in the extraction process, including ensuring consistency across treebank schemes and dealing with language-specific syntactic idiosyncrasies. Finally, we propose the future extension of TAGbank to include multilingual corpora, focusing on the Penn Korean and Penn Chinese Treebanks, to explore the cross-linguistic application of TAG's formalism. By providing a robust, derivation-based resource, TAGbank aims to support a wide range of computational tasks and contribute to the theoretical understanding of TAG's generative capacity.
Foundations and Evaluations in NLP
Apr 02, 2025This memoir explores two fundamental aspects of Natural Language Processing (NLP): the creation of linguistic resources and the evaluation of NLP system performance. Over the past decade, my work has focused on developing a morpheme-based annotation scheme for the Korean language that captures linguistic properties from morphology to semantics. This approach has achieved state-of-the-art results in various NLP tasks, including part-of-speech tagging, dependency parsing, and named entity recognition. Additionally, this work provides a comprehensive analysis of segmentation granularity and its critical impact on NLP system performance. In parallel with linguistic resource development, I have proposed a novel evaluation framework, the jp-algorithm, which introduces an alignment-based method to address challenges in preprocessing tasks like tokenization and sentence boundary detection (SBD). Traditional evaluation methods assume identical tokenization and sentence lengths between gold standards and system outputs, limiting their applicability to real-world data. The jp-algorithm overcomes these limitations, enabling robust end-to-end evaluations across a variety of NLP tasks. It enhances accuracy and flexibility by incorporating linear-time alignment while preserving the complexity of traditional evaluation metrics. This memoir provides key insights into the processing of morphologically rich languages, such as Korean, while offering a generalizable framework for evaluating diverse end-to-end NLP systems. My contributions lay the foundation for future developments, with broader implications for multilingual resource development and system evaluation.
Chinese Grammatical Error Correction: A Survey
Apr 01, 2025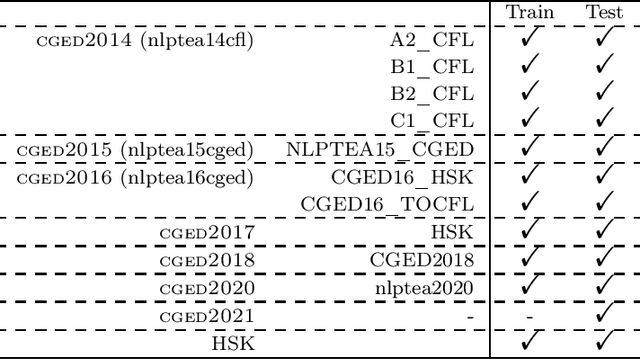



Chinese Grammatical Error Correction (CGEC) is a critical task in Natural Language Processing, addressing the growing demand for automated writing assistance in both second-language (L2) and native (L1) Chinese writing. While L2 learners struggle with mastering complex grammatical structures, L1 users also benefit from CGEC in academic, professional, and formal contexts where writing precision is essential. This survey provides a comprehensive review of CGEC research, covering datasets, annotation schemes, evaluation methodologies, and system advancements. We examine widely used CGEC datasets, highlighting their characteristics, limitations, and the need for improved standardization. We also analyze error annotation frameworks, discussing challenges such as word segmentation ambiguity and the classification of Chinese-specific error types. Furthermore, we review evaluation metrics, focusing on their adaptation from English GEC to Chinese, including character-level scoring and the use of multiple references. In terms of system development, we trace the evolution from rule-based and statistical approaches to neural architectures, including Transformer-based models and the integration of large pre-trained language models. By consolidating existing research and identifying key challenges, this survey provides insights into the current state of CGEC and outlines future directions, including refining annotation standards to address segmentation challenges, and leveraging multilingual approaches to enhance CGEC.
Parsing Through Boundaries in Chinese Word Segmentation
Mar 29, 2025Chinese word segmentation is a foundational task in natural language processing (NLP), with far-reaching effects on syntactic analysis. Unlike alphabetic languages like English, Chinese lacks explicit word boundaries, making segmentation both necessary and inherently ambiguous. This study highlights the intricate relationship between word segmentation and syntactic parsing, providing a clearer understanding of how different segmentation strategies shape dependency structures in Chinese. Focusing on the Chinese GSD treebank, we analyze multiple word boundary schemes, each reflecting distinct linguistic and computational assumptions, and examine how they influence the resulting syntactic structures. To support detailed comparison, we introduce an interactive web-based visualization tool that displays parsing outcomes across segmentation methods.
Enhancing Korean Dependency Parsing with Morphosyntactic Features
Mar 26, 2025This paper introduces UniDive for Korean, an integrated framework that bridges Universal Dependencies (UD) and Universal Morphology (UniMorph) to enhance the representation and processing of Korean {morphosyntax}. Korean's rich inflectional morphology and flexible word order pose challenges for existing frameworks, which often treat morphology and syntax separately, leading to inconsistencies in linguistic analysis. UniDive unifies syntactic and morphological annotations by preserving syntactic dependencies while incorporating UniMorph-derived features, improving consistency in annotation. We construct an integrated dataset and apply it to dependency parsing, demonstrating that enriched morphosyntactic features enhance parsing accuracy, particularly in distinguishing grammatical relations influenced by morphology. Our experiments, conducted with both encoder-only and decoder-only models, confirm that explicit morphological information contributes to more accurate syntactic analysis.
Revisiting Absence withSymptoms that *T* Show up Decades Later to Recover Empty Categories
Dec 02, 2024
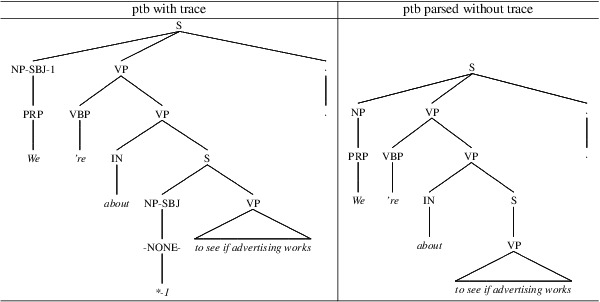
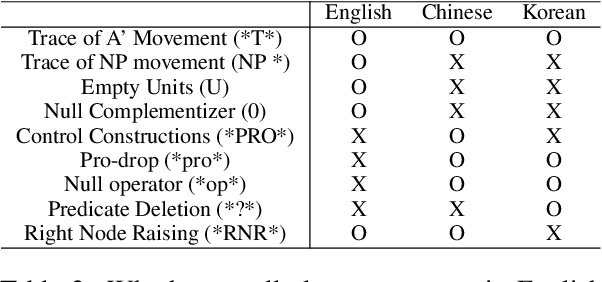
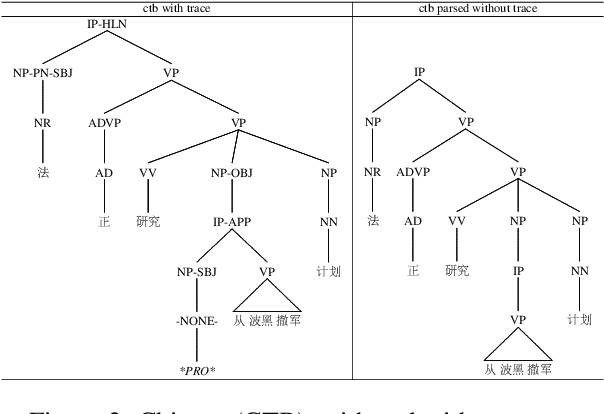
This paper explores null elements in English, Chinese, and Korean Penn treebanks. Null elements contain important syntactic and semantic information, yet they have typically been treated as entities to be removed during language processing tasks, particularly in constituency parsing. Thus, we work towards the removal and, in particular, the restoration of null elements in parse trees. We focus on expanding a rule-based approach utilizing linguistic context information to Chinese, as rule based approaches have historically only been applied to English. We also worked to conduct neural experiments with a language agnostic sequence-to-sequence model to recover null elements for English (PTB), Chinese (CTB) and Korean (KTB). To the best of the authors' knowledge, null elements in three different languages have been explored and compared for the first time. In expanding a rule based approach to Chinese, we achieved an overall F1 score of 80.00, which is comparable to past results in the CTB. In our neural experiments we achieved F1 scores up to 90.94, 85.38 and 88.79 for English, Chinese, and Korean respectively with functional labels.